【推荐系统学习总结 NCF => NGCF => LightGCN】
推荐系统学习总结 NCF => NGCF => LightGCN
- NCF(别名 NeuMF)
-
- 背景
- 动机
- 创新点
- 模型框架
- 损失函数
- 核心代码实现
- NGCF
-
- 背景
- 动机
- 创新点
- 模型框架
- 损失函数
- 核心代码实现
- LightGCN
-
- 背景
- 动机
- 创新点
- 模型框架
- 损失函数
- 核心代码实现
- 其他参考链接
NCF(别名 NeuMF)
背景
(1)神经网络已经点燃了视觉领域,但在推荐领域还未有波澜;有几篇把深度学习和推荐结合的文章,例如 wang hao 的 collaborative deep learning,但主要是用深度学习从 side information 里进行特征抽取,协同过滤还是传统方式。大家都不知道怎么把协同过滤 formulate 成可以用神经网络解决的问题。当然现在回头看来,NCF把协同过滤formulate成神经网络学习问题是非常简单和自然的,以及把MF表示成神经网络的一个特例也很自然,但在当时确实是很困扰推荐领域学者的一个问题。
(2)深度学习编程框架还很不成熟,tensorflow 刚发表 0.1 版没多久 bug 频出且可参考代码很少,最流行框架是 theano(现在已经退出了历史舞台),但几乎没有 theano 的推荐项目(那时几乎没有深度学习+推荐的论文,更别提公开的项目了);当然现在回头看来,NCF 的实现是很简单的,有各种各样深度学习推荐系统工具包可用,但在当时是几乎没有可参考代码的
参考链接:如何看待Google推荐系统大佬Steffen Rendle发文讨论何向南的NCF方法中的问题?
动机
现实数据是高维数据,而矩阵分解只能将高维 (high-dimension) 数据映射到低维 (low-dimension) 的嵌入层 (embedding),编码到嵌入层的信息并不能完全正确反映现实数据,因此会产生如图 (b) 的错误 “利用有限的、错误的信息预测出了错误的用户偏好”。

创新点
将 神经网络 引入到 协同过滤 里
模型框架
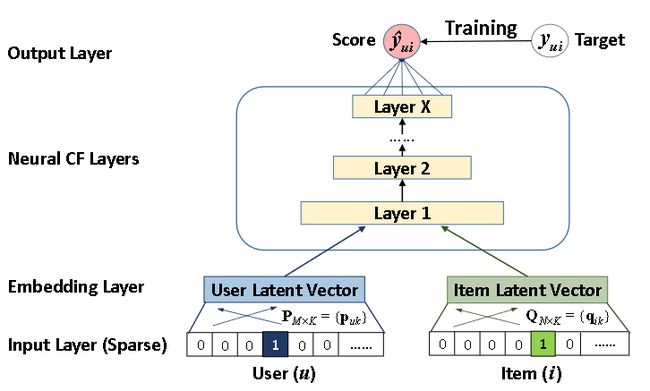
损失函数
成对损失 (pairwise loss)

核心代码实现
def forward(self, user, item):
if not self.model == 'MLP':
embed_user_GMF = self.embed_user_GMF(user)
embed_item_GMF = self.embed_item_GMF(item)
output_GMF = embed_user_GMF * embed_item_GMF
if not self.model == 'GMF':
embed_user_MLP = self.embed_user_MLP(user)
embed_item_MLP = self.embed_item_MLP(item)
""" 按最后一个维度进行堆叠 """
interaction = torch.cat((embed_user_MLP, embed_item_MLP), -1)
output_MLP = self.MLP_layers(interaction)
if self.model == 'GMF':
concat = output_GMF
elif self.model == 'MLP':
concat = output_MLP
else:
concat = torch.cat((output_GMF, output_MLP), -1)
prediction = self.predict_layer(concat)
""" .view(-1) 将 tensor 变成一维的形式,-1 表示自动调整维度,
这里是将 torch.Size([256, 1]) --> torch.Size([256])
参考链接:https://blog.csdn.net/qq_38929105/article/details/106438045
参考链接:https://m.imooc.com/qadetail/339372 """
return prediction.view(-1)
NGCF
背景
传统的推荐系统在设计嵌入层(Embeddings)时,要么是基于 用户 (user) 设计,要么是基于 物品 (item) 设计。
动机
将 用户-物品 (user-item) 的协同信号 (collaborative signal)(或者说 user-item 的交互信息)引入到嵌入层(Embeddings)的设计中。
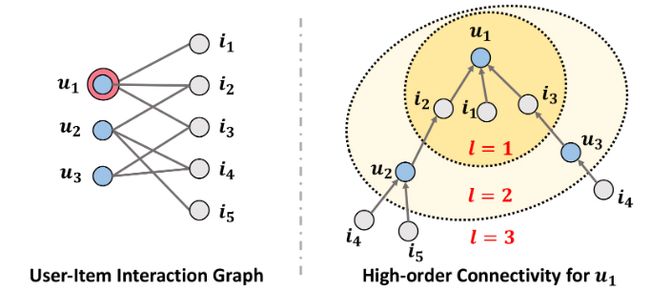
创新点
将卷积层的理念引入到推荐系统中,通过堆叠多层卷积层找到 用户-物品 (user-item) 的 高阶连通性 (high-order connectivity)
模型框架

损失函数
成对损失 (pairwise loss)

核心代码实现
def forward(self, users, pos_items, neg_items, drop_flag=True):
""" A_hat: torch.Size([70839, 70839])
添加了 dropout 的归一化系数, where each decay factor bewteen two connected nodes is set as 1/(out degree of the node + self-conncetion)
这里 self.sparse_norm_adj._nnz() 的作用就是取出非零元素 interaction """
A_hat = self.sparse_dropout(self.sparse_norm_adj,
self.node_dropout,
self.sparse_norm_adj._nnz()) if drop_flag else self.sparse_norm_adj
""" 直接把 user embedding 和 item embedding 并起来拿去训练(前半部分 user, 剩余部分 item) """
ego_embeddings = torch.cat([self.embedding_dict['user_emb'],
self.embedding_dict['item_emb']], 0)
""" 把 ego_embedding 放到 list 里,为了接下来将序列里的多个 tensor 并联 """
all_embeddings = [ego_embeddings]
for k in range(len(self.layers)):
""" 利用折扣系数构造边信息(side_embedding):
折扣系数(A_hat)与原始信息的自我嵌入(ego_embedding)进行叉乘(矩阵乘法)
用 A_hat 里的 mask,把部分 ego_embedding 给丢弃掉,即(node dropout: 丢失部分原始信息)
side_embeddings: torch.Size([70839, 64])"""
side_embeddings = torch.sparse.mm(A_hat, ego_embeddings)
""" 构建总信息(自信息+交互信息)的一部分,即自信息部分(前半 user + 后半 item),
‘W1 x (user 的 ego_embedding) || W1 x (item 的 ego_embedding)’
torch.matmul: 逐元素乘积, https://blog.csdn.net/didi_ya/article/details/121158666
torch.Size([70839, 64]) 叉乘 torch.Size([64, 64]) 加 torch.Size([1, 64]) """
# transformed sum messages of neighbors.
sum_embeddings = torch.matmul(side_embeddings, self.weight_dict['W_gc_%d' % k]) \
+ self.weight_dict['b_gc_%d' % k]
""" 用逐元素乘法构造交互信号,将原始信息的自我嵌入(ego_embedding)
与 side embedding (node dropout 后的 ego_embedding) 逐元素乘法,即构造出了交互信号,
【side embedding 通过 p_ui 控制 user 和 item 的交互强度】
【原文:uses the coefficient p_ui to control the decay factor on each propagation on edge (u, i).】
torch.mul()、torch.mm()、torch.matmul()的区别: https://blog.csdn.net/weixin_44443160/article/details/118553309"""
# bi messages of neighbors.
# element-wise product
bi_embeddings = torch.mul(ego_embeddings, side_embeddings)
# transformed bi messages of neighbors.
""" W2 x (user interaction embedding) || W2 x (item interaction embedding) """
bi_embeddings = torch.matmul(bi_embeddings, self.weight_dict['W_bi_%d' % k]) \
+ self.weight_dict['b_bi_%d' % k]
""" 为 (self-message + interactional message) 的 embedding 套上激活函数。
构建出要传播到下一层的 ego message"""
# non-linear activation.
ego_embeddings = nn.LeakyReLU(negative_slope=0.2)(sum_embeddings + bi_embeddings)
""" 给每层 message embedding 套上 dropout (即 message dropout),防止过拟合 """
# message dropout.
ego_embeddings = nn.Dropout(self.mess_dropout[k])(ego_embeddings)
""" 对 embedding 规范化, 提高泛化能力
F.normalize 将某一个维度除以那个维度对应的范数(默认是2范数)
https://blog.csdn.net/lj2048/article/details/118115681 """
# normalize the distribution of embeddings.
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
""" 每一层的消息传递结果都被记录(记录了 256 维), torch.Size([70839, 256]) """
all_embeddings = torch.cat(all_embeddings, 1)
""" 从总嵌入里取出前半部分,即 user 嵌入部分, torch.Size([29858, 256])"""
u_g_embeddings = all_embeddings[:self.n_user, :]
""" 从总嵌入里取出后半部分,即 item 嵌入部分, torch.Size([40981, 256]) """
i_g_embeddings = all_embeddings[self.n_user:, :]
"""
*********************************************************
look up.
根据抽样的 userID, 正样本ID, 负样本ID 作为索引,获取最终嵌入层的结果
"""
u_g_embeddings = u_g_embeddings[users, :] # torch.Size([1024, 256])
pos_i_g_embeddings = i_g_embeddings[pos_items, :] # torch.Size([1024, 256])
neg_i_g_embeddings = i_g_embeddings[neg_items, :] # torch.Size([1024, 256])
return u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings
LightGCN
背景
NGCF 太复杂了,非线性激活函数 和 特征变换矩阵 的引入对于 userID / itemID embedding 而言,没什么用
动机
对 NGCF 进行消融实验,去除 非线性激活函数 和 特征变换矩阵
创新点
效果比 NGCF 好了,变成了推荐系统领域优秀的 baseline
模型框架
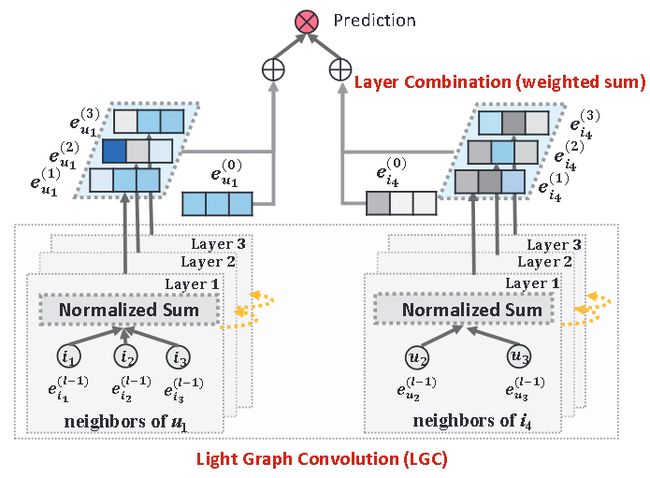
损失函数
成对损失 (pairwise loss)

核心代码实现
def computer(self):
"""
propagate methods for lightGCN, 前向传播过程
"""
users_emb = self.embedding_user.weight
items_emb = self.embedding_item.weight
""" 将 user 和 item 的 embedding 拼接在一起 """
all_emb = torch.cat([users_emb, items_emb])
# torch.split(all_emb , [self.num_users, self.num_items])
embs = [all_emb]
if self.config['dropout']:
if self.training:
print("droping")
g_droped = self.__dropout(self.keep_prob)
else:
g_droped = self.Graph
else:
g_droped = self.Graph
""" 计算每一层的 embedding
g_droped 存的是含有 user-item 交互信息的稀疏矩阵,同时应该包含 decay factor[ 1/(N_u*N_i) ]
(猜测是分解后的形式,涉及拉普拉斯矩阵分解的知识,具体可以看看邱锡鹏的神经网络与深度学习的附录页),
all_emb 每次循环后的结果都是承接上一次循环结束后的结果,依次获得了 e^(1), e^(2), e^(3), ...,
最后将 e^(0), e^(1), e^(2), e^(3), ... 放入 embs 里"""
for layer in range(self.n_layers):
if self.A_split:
temp_emb = []
for f in range(len(g_droped)):
temp_emb.append(torch.sparse.mm(g_droped[f], all_emb))
side_emb = torch.cat(temp_emb, dim=0)
all_emb = side_emb
else:
all_emb = torch.sparse.mm(g_droped, all_emb)
embs.append(all_emb)
embs = torch.stack(embs, dim=1)
#print(embs.size())
""" torch.mean 对 embs 中 e^(0), e^(1), e^(2), e^(3), ... 的第 1 个维度取平均值
参考链接:https://blog.csdn.net/a1208498468/article/details/123215636
【Why】值得注意的是,这里并没有像论文里一样,对不同的 embedding 设置不同的权值,仅仅是求平均,
难道 g_droped 里已经包含了权值了吗?还是说,不用特意对每层加权求和,因为感知机学到的权重本身就能
代表每一层的 embedding 的不同的权值 """
light_out = torch.mean(embs, dim=1)
""" torch.mean 将上述 light_out 拆分成 user embedding 块和 item embedding 块
参考链接:https://blog.csdn.net/qq_42518956/article/details/103882579"""
users, items = torch.split(light_out, [self.num_users, self.num_items])
return users, items
其他参考链接
图神经网络用于推荐系统问题(NGCF,LightGCN,UltraGCN)