七天七夜,终于实现了实时的实例分割算法部署TensorRT,40FPS!
七天七夜,终于实现了实时的实例分割算法部署TensorRT,40FPS!
本文由林大佬原创,转载请注明出处,我们有来自腾讯、阿里等一线AI算法工程师组成微信交流群, 如果你想交流欢迎添加微信: jintianandmerry 拉群, 添加请备注 “交流群”
2021年的第一篇文章, 我和我的团队经过七天七夜的赶工 (元旦三天别人跨年我们和键盘度过了三天…),终于将panopticfcn部署到了TensorRT, 关于这个算法我在之前的文章有给大家讲解,可以说是一篇非常非常新鲜的文章, 论文中mAP可以高达32, 与MaskRCNN一样, 并且这个算法是一个全景分割算法, 它可以产生的是一个全景分割的输出.
我们都知道, 现如今在实例分割这个领域, 能够跑到Realtime的算法很少, 能够跑到超过实时的算法就更少了. 大家比较熟悉的MaskRCNN, 在detectron2里面, 即便是输入在512的尺寸, 速度也只能达到8-9ms, 这个速度连10fps都没有. 而对于一些实时的算法, 比如Yolact, 它的速度虽然很快,但是精度很感人. 在实际使用中,几乎是不可用的. 而如今我们可以得到一个精度可以和MaskRCNN相媲美, 但同时速度是它40倍的算法! 当然这个加速是基于TensorRT以及算法两部分加成的, 且PanopticFCN并非是一个2 stage的算法, 因此速度相较于MaskrCNN是一个很大的优势.
先来看一下我们最终实现的效果吧:

我们做到的速度大概是网络前传19ms, 所有包括可视化后处理等大概24ms, 总的FPS可以达到40! 可以看到这个速度还是很快的, 并且对于一些小目标的分割来说, 丝毫没有太大的影响.
这个模型的python代码和论文相关大家可以参照:
https://github.com/yanwei-li/PanopticFCN
当然在实现这个模型转tensorrt的过程中, 也是很麻烦的, 遇到了许多挑战(不然不会让我们的男子天团耗费七天七夜的时间). 首先在转到onnx的时候就遇到了许多问题, 比如这个模型是把实例和背景图全部当做是分割图并杂糅在一起的, 我们一开始的思路是先把实例 部分抠出来做部署,因此这两个部分拆分需要修改不少模型的代码. 另外就是这个模型具有5层的FPN的输出, 这和Fcos等模型操作一样, 如何merge这5层的操作, 并将这些输出全部塞到onnx里面去,需要一些技巧. 还有就是这个模型的后处理,涉及到很多TopK的操作, 熟悉模型部署的同学应该都知道, TopK是一个很麻烦的事情, 首先onnx转tensorrt的时候是不支持topk的, 或者对于topk支持不够完全, 另外就是这个模型最大的难点和SOlOv2的TensorRT部署是一样的, 也就是: 它的mask生成是通过卷积权重来合成的, 这就意味着输出有一部分是卷积的权重.
我们最终踏平了所有困难, 导出onnx大概只占了我们所有工作量的30%, 剩下的工作都是在debug CUDA代码…
我们在这个项目里主要实现了:
- panopticfcn的onnx导出, 当然这个导出我们尽可能的把所有的操作塞进了onnx里面;
- 解决了InstanceSegmentation op在tensorrt支持的问题;
- 解决了GatherElements的问题, 事实上GatherElements在TensorRT不支持;
- 通过将所有的后处理封装为一个Plugin实现了所有的后处理操作, 最后的输出直接就是mask;
- 实现了一套可行的方案, 处理输出是conv卷积权重的问题.
最后完成了一整套的解决方案. 据我们所知, 这也是业内能找到的唯一一个能跑到这么快的实例分割TensorRT部署方案. 顺便打个广告, 同样的算法和方案也可以通过onnx部署到任何平台, 包括FPGA, CPU, 以及其他库, 欢迎私聊我进行进一步的商业合作.
算法讲解
这个算法的大概处理流程是这样的:
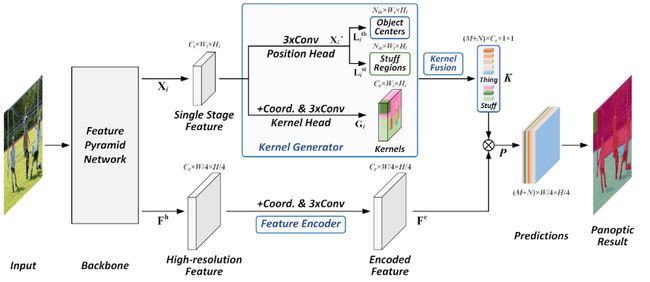
具体细节 大家也可以查看论文. 在处理的时候这里面的难点就是:
- KernelGenerator如何处理;
- 如何拆分Thing和Stuff, 有人问为什么要拆分, 因为不拆分后处理很复杂,我们无法确保拿到正确的结果, 现在验证了实例部分我们会想办法把全景也加入;
- 如何通过Feature encoder输出的feature, 联合输出的卷积权重来生成mask.
由于解决方案过于复杂, 就不赘述了, 具体大家可以从神力平台获取python代码查看具体的修改:
http://manaai.cn
TensorRT部署
最后我们的部署方案在GTX1080TI可以跑到 40FPS, 在RTX2080Ti使用fp16预测速度可以缩减到10ms. 如果再进一步对模型进行小模型优化,速度可以更快. 我们目前部署的版本是Resnet50.
我们在使用C++进行TensorRT部署时发现. 模型的后处理可以尽可能的快, 只要onnx和tensorrt的engine截断方式合理. 由于我们的导出策略, 将大部分复杂的运算全部转成了固定的engine, 从而最终的后处理时间被大大的缩短. 这相较于MaskRCNN等二阶段的实例分割算法部署带来的好处就是更快的端到端时间, 并且不受限于实例的个数.
下一步
大家可以在神力平台获取到我们修改过的python代码 (支持onnx导出以及推理), 同时也可以获取到tensorrt的对应加速方案. 但禁止白嫖, 现在植发越来越贵了,哎…
更多

如果你想学习人工智能,对前沿的AI技术比较感兴趣,可以加入我们的知识星球,获取第一时间资讯,前沿学术动态,业界新闻等等!你的支持将会鼓励我们更频繁的创作,我们也会帮助你开启更深入的深度学习之旅!
往期文章
https://zhuanlan.zhihu.com/p/165009477
https://zhuanlan.zhihu.com/p/149398749
https://zhuanlan.zhihu.com/p/147622974
https://zhuanlan.zhihu.com/p/144727162