高光谱图像分类 HybridSN混合网络
本次实验主要参考《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》,通过HybridSN混合网络实现了高光谱图像分类,平台使用Google Colab平台。
背景
近年来,由于高光谱数据的独特性质以及所包含的海量信息,对于高光谱图像的分析与处理已经成为遥感影像研究领域的热点之一,而其中的高光谱图像分类任务又对地质勘探、农作物检测、国防军事等领域起着实质性的重要作用,值得更加深入的研究。然而高光谱图像分类任务中,数据特征的获取和学习一直是研究的重点与难点,如何提取充分有效的特征直接影响到分类结果的好坏。

在技术方面,高光谱图像是立体数据,也有光谱维数,仅凭2D-CNN无法从光谱维度中提取出具有良好鉴别能力的feature maps。一个深度3D-CNN在计算上更加复杂,对于在许多光谱带上具有相似纹理的类来说,单独使用似乎表现得更差。
混合CNN模型克服了之前模型的这些缺点,将3D-CNN和2D-CNN层组合到该模型中,充分利用光谱和空间特征图,以达到最大可能的精度。其中3D-CNN在2D-CNN的基础上,保留了对应的时空特征。
相关知识
高光谱图像(Hyperspectral Image):在光谱的维度进行了细致的分割,不仅仅是传统的黑,白或者RGB的区别,而是在光谱维度上也有N个通道。
例如:我们可以把400nm-1000nm分为300个通道,一次,通过高光谱设备获取的是一个数据立方,不仅有图像的信息,并且在光谱维度上进行展开,结果不仅可以获得图像上每个点的光谱数据,还可以获得任意一个谱段的影像信息。
高光谱图像成像原理:空间中的一维信息通过镜头和狭缝后,不同波长的光按照不同程度的弯散传播,一维图像上的每个点,再通过光栅进行衍射分光,形成一个谱带,照射到探测器上,探测器上的每个像素位置和强度表征光谱和强度。

论文实现
空间光谱高光谱数据立方体表示为:

I为原始输入,M为宽度,N为高度,D为光谱带数/深度
I中的每个HSI像素包含D个光谱测度,形成一个one-hot向量
之后的步骤:
- 将主成分分析(PCA)应用于原始HSI数据(I)的光谱波段(将光谱波段从D减少到B,保持相同的空间维数),只减少了光谱波段,保留了对识别物体重要的空间信息。
- 下式为处理后的数据立方体,其中X为PCA后的输入,M为宽度,N为高度,B为主成分后的光谱带数。

- 将HSI数据立方体划分为重叠的三维小块,小块的truth label由中心像素的label决定。
- 从X开始,创建以空间位置(α,β)为中心的三维相邻块,覆盖了S×S的窗口或者是空间范围和所有B光谱波段。
- 在(α,β)上的三维块覆盖了宽度从α-(S-1)/2到α+(S-1)/2,高度从β-(S-1)/2到β+(S-1)/2和所有的PCA简化立体数据X的B光谱波段。
- 在二维卷积中,第j个特征图的i层中(x,y)位置的激活值表示如公式(1)下:(其中φ是激活函数,bi, j是第j个特征图的i层的偏差参数,dl−1是第(l−1)层特征图的数量和第i层j个特征图的数量,2γ+ 1是卷积核的宽度,2δ +1 是卷积核的高度,wi,j 为第i层j个特征图权重指数的值)

在HSI数据模型中,利用三维核在输入层的多个连续频带上生成卷积层的特征图,捕获了光谱信息;在三维卷积中,在第i层第j个特征图中(x,y)的激活值记为Vx,y, Zi,j,如公式(2)所示:

其中2η + 1 为卷积核沿光谱维数的深度,其他参数不变
实验实现
1.读入数据、引入库
#读入数据
!wget http://www.ehu.eus/ccwintco/uploads/6/67/Indian_pines_corrected.mat
!wget http://www.ehu.eus/ccwintco/uploads/c/c4/Indian_pines_gt.mat
!pip install spectral
#引入库函数
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,accuracy_score,classification_report,cohen_kappa_score
import spectral
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
2.网络结构

三维卷积部分:
conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout
最后输出为 16 个节点,是最终的分类类别数。
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
#三维卷积
self.conv3d_1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
#二维卷积
self.conv2d_4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
3.创建数据集
首先对高光谱数据实施PCA降维;然后创建 keras 方便处理的数据格式;然后随机抽取 10% 数据做为训练集,剩余的做为测试集。
首先,定义基本函数:
# 对高光谱数据 X 应用 PCA 变换
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
#对单个像素周围提取 patch 时,边缘像素就无法取了,因此,给这部分像素进行 padding 操作
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
#在每个像素周围提取 patch ,然后创建成符合 keras 处理的格式
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
# 给 X 做 padding
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test
下面读取并创建数据集:
# 地物类别
class_num = 16
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
# 用于测试样本的比例
test_ratio = 0.90
# 每个像素周围提取 patch 的尺寸
patch_size = 25
# 使用 PCA 降维,得到主成分的数量
pca_components = 30
print('Hyperspectral data shape: ', X.shape)
print('Label shape: ', y.shape)
print('\n... ... PCA tranformation ... ...')
X_pca = applyPCA(X, numComponents=pca_components)
print('Data shape after PCA: ', X_pca.shape)
print('\n... ... create data cubes ... ...')
X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size)
print('Data cube X shape: ', X_pca.shape)
print('Data cube y shape: ', y.shape)
print('\n... ... create train & test data ... ...')
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio)
print('Xtrain shape: ', Xtrain.shape)
print('Xtest shape: ', Xtest.shape)
# 改变 Xtrain, Ytrain 的形状,以符合 keras 的要求
Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1)
Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1)
print('before transpose: Xtrain shape: ', Xtrain.shape)
print('before transpose: Xtest shape: ', Xtest.shape)
# 为了适应 pytorch 结构,数据要做 transpose
Xtrain = Xtrain.transpose(0, 4, 3, 1, 2)
Xtest = Xtest.transpose(0, 4, 3, 1, 2)
print('after transpose: Xtrain shape: ', Xtrain.shape)
print('after transpose: Xtest shape: ', Xtest.shape)
""" Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
# 创建 trainloader 和 testloader
trainset = TrainDS()
testset = TestDS()
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=2)

4.开始训练
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 网络放到GPU上
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 开始训练
total_loss = 0
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
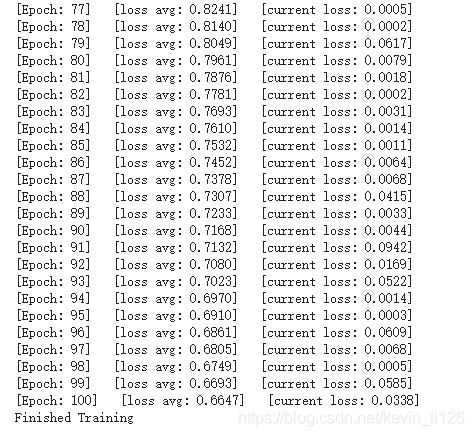
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')
5.模型测试
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)
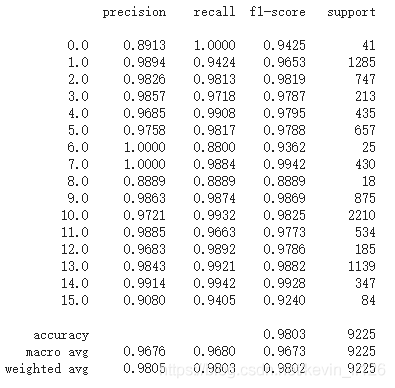
可以看到,正确率到达了98%以上,效果非常好。
6.附加函数显示结果
from operator import truediv
def AA_andEachClassAccuracy(confusion_matrix):
counter = confusion_matrix.shape[0]
list_diag = np.diag(confusion_matrix)
list_raw_sum = np.sum(confusion_matrix, axis=1)
each_acc = np.nan_to_num(truediv(list_diag, list_raw_sum))
average_acc = np.mean(each_acc)
return each_acc, average_acc
def reports (test_loader, y_test, name):
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred = outputs
count = 1
else:
y_pred = np.concatenate( (y_pred, outputs) )
if name == 'IP':
target_names = ['Alfalfa', 'Corn-notill', 'Corn-mintill', 'Corn'
,'Grass-pasture', 'Grass-trees', 'Grass-pasture-mowed',
'Hay-windrowed', 'Oats', 'Soybean-notill', 'Soybean-mintill',
'Soybean-clean', 'Wheat', 'Woods', 'Buildings-Grass-Trees-Drives',
'Stone-Steel-Towers']
elif name == 'SA':
target_names = ['Brocoli_green_weeds_1','Brocoli_green_weeds_2','Fallow','Fallow_rough_plow','Fallow_smooth',
'Stubble','Celery','Grapes_untrained','Soil_vinyard_develop','Corn_senesced_green_weeds',
'Lettuce_romaine_4wk','Lettuce_romaine_5wk','Lettuce_romaine_6wk','Lettuce_romaine_7wk',
'Vinyard_untrained','Vinyard_vertical_trellis']
elif name == 'PU':
target_names = ['Asphalt','Meadows','Gravel','Trees', 'Painted metal sheets','Bare Soil','Bitumen',
'Self-Blocking Bricks','Shadows']
classification = classification_report(y_test, y_pred, target_names=target_names)
oa = accuracy_score(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
each_acc, aa = AA_andEachClassAccuracy(confusion)
kappa = cohen_kappa_score(y_test, y_pred)
return classification, confusion, oa*100, each_acc*100, aa*100, kappa*100
#将结果写在文件里
classification, confusion, oa, each_acc, aa, kappa = reports(test_loader, ytest, 'IP')
classification = str(classification)
confusion = str(confusion)
file_name = "classification_report.txt"
with open(file_name, 'w') as x_file:
x_file.write('\n')
x_file.write('{} Kappa accuracy (%)'.format(kappa))
x_file.write('\n')
x_file.write('{} Overall accuracy (%)'.format(oa))
x_file.write('\n')
x_file.write('{} Average accuracy (%)'.format(aa))
x_file.write('\n')
x_file.write('\n')
x_file.write('{}'.format(classification))
x_file.write('\n')
x_file.write('{}'.format(confusion))
#显示结果
# load the original image
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
height = y.shape[0]
width = y.shape[1]
X = applyPCA(X, numComponents= pca_components)
X = padWithZeros(X, patch_size//2)
# 逐像素预测类别
outputs = np.zeros((height,width))
for i in range(height):
for j in range(width):
if int(y[i,j]) == 0:
continue
else :
image_patch = X[i:i+patch_size, j:j+patch_size, :]
image_patch = image_patch.reshape(1,image_patch.shape[0],image_patch.shape[1], image_patch.shape[2], 1)
X_test_image = torch.FloatTensor(image_patch.transpose(0, 4, 3, 1, 2)).to(device)
prediction = net(X_test_image)
prediction = np.argmax(prediction.detach().cpu().numpy(), axis=1)
outputs[i][j] = prediction+1
if i % 20 == 0:
print('... ... row ', i, ' handling ... ...')
predict_image = spectral.imshow(classes = outputs.astype(int),figsize =(5,5))
第一次训练测试结果:

第二次训练训练结果:

结果不是很稳定,第一次的结果存在较大噪声,第二次的结果较好。
进一步思考
我们能否在此基础上,进一步的改善高光谱图像的分类性能?答案是必然的,我们可以用注意力机制来进行改良。
注意力机制
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。

视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
上图形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于上图所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
可能的改进方法
如果从维度上考虑,可以从图像空间,通道,和光谱的波长三个方向使用注意力机制来处理特征,理论上是可以得到更好的效果的。
其中最为直观的方法就是针对图像空间,使用注意力机制。可以采用空间注意力机制,针对局部区域的关键特征,并找到与之对应的特征空间。根据获取到的信息进行提取,将有可能改善高光谱图像的分类性能。
参考:
[1]:https://www.cnblogs.com/cch-EX/p/13458764.html
[2]:https://blog.csdn.net/hpulfc/article/details/80448570