pytorch实现简单全连接层
文章目录
- 线性回归
-
- 导入所需库
- 生成数据集
- 读取数据
- 定义模型
- 初始化模型参数
- 定义损失函数和优化算法
- 训练模型
- 小结
- 补充
- softmax回归
-
- 基本原理
- 交叉熵损失函数
- 简洁实现
线性回归
导入所需库
import torch
import torch.nn as nn
import numpy as np
import random
生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
#最后一行添加噪声
读取数据
import torch.utils.data as Data
batch_size = 10
# 将训练数据的特征和标签组合
dataset = Data.TensorDataset(features, labels)
# 随机读取小批量
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)
定义模型
pytorch提供了大量预定义的层,这使我们只需关注使用哪些层来构造模型。在实际使用中,最常见的做法是继承nn.Module,撰写自己的网络/层。一个nn.Module实例应该包含一些层以及返回输出的前向传播(forward)方法。
写法如下:
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__()
self.linear = nn.Linear(n_feature, 1)
# forward 定义前向传播
def forward(self, x):
y = self.linear(x)
return y
net = LinearNet(num_inputs)
print(net) # 使用print可以打印出网络的结构
输出:
LinearNet(
(linear): Linear(in_features=2, out_features=1, bias=True)
)
此外,也可利用nn.Sequential更简洁地搭建网络。
# 写法一
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# 此处还可以传入其他层
)
# 写法二
net = nn.Sequential()
net.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module ......
# 写法三
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
('linear', nn.Linear(num_inputs, 1))
# ......
]))
print(net)
print(net[0])
输出:
Sequential(
(linear): Linear(in_features=2, out_features=1, bias=True)
)
Linear(in_features=2, out_features=1, bias=True)
初始化模型参数
from torch.nn import init
init.normal_(net[0].weight, mean=0, std=0.01)
init.constant_(net[0].bias, val=0) # 也可以直接修改bias的data: net[0].bias.data.fill_(0)
定义损失函数和优化算法
loss = nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.03)
训练模型
num_epochs = 3
for epoch in range(1, num_epochs + 1):
for X, y in data_iter:
output = net(X)
l = loss(output, y.view(-1, 1))
optimizer.zero_grad() # 梯度清零,等价于net.zero_grad()
l.backward()
optimizer.step()
print('epoch %d, loss: %f' % (epoch, l.item()))
小结
torch.utils.data模块提供了有关数据处理的工具,torch.nn模块定义了大量神经网络的层,torch.nn.init模块定义了各种初始化方法,torch.optim模块提供了很多常用的优化算法。
补充
构建模型时,在单层神经网络基础上,添加一个隐藏层(加上激活函数),即构成多层感知机。
softmax回归
基本原理
softmax回归跟线性回归一样将输入特征与权重做线性叠加。与线性回归的一个主要不同在于,softmax回归的输出值个数等于标签里的类别数。假设有4种特征和3种输出类别:
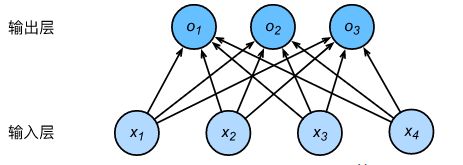
对每个输入做如下计算:
- o 1 = x 1 w 11 + x 2 w 21 + x 3 w 31 + x 4 w 41 + b 1 o_1=x_1w_{11}+x_2w_{21}+x_3w_{31}+x_4w_{41}+b_1 o1=x1w11+x2w21+x3w31+x4w41+b1
o 2 = x 1 w 12 + x 2 w 22 + x 3 w 32 + x 4 w 42 + b 2 o_2=x_1w_{12}+x_2w_{22}+x_3w_{32}+x_4w_{42}+b_2 o2=x1w12+x2w22+x3w32+x4w42+b2
o 3 = x 1 w 13 + x 2 w 23 + x 3 w 33 + x 4 w 43 + b 3 o_3=x_1w_{13}+x_2w_{23}+x_3w_{33}+x_4w_{43}+b_3 o3=x1w13+x2w23+x3w33+x4w43+b3 - y 1 ^ , y 2 ^ , y 3 ^ = s o f t m a x ( o 1 , o 2 , o 3 ) \hat{y_1},\hat{y_2},\hat{y_3}=softmax(o_1,o_2,o_3) y1^,y2^,y3^=softmax(o1,o2,o3)
其中 y i ^ = e y i ∑ j = 1 3 e y j ( i = 1 , 2 , 3 ) \hat{y_i}=\frac{e^{y_i}}{\sum_{j=1}^3e^{y_j}}(i=1,2,3) yi^=∑j=13eyjeyi(i=1,2,3)
矢量表示如下:
O = X W + b , Y ^ = s o f t m a x ( O ) \boldsymbol {O=XW+b},\\ \boldsymbol{\hat{Y}}=softmax(\boldsymbol O) O=XW+b,Y^=softmax(O)
交叉熵损失函数
交叉熵: H ( y ( i ) , y ^ ( i ) ) = − ∑ j = 1 q y j ( i ) l o g y ^ j ( i ) H(\boldsymbol{y^{(i)}},\boldsymbol{\hat{y}^{(i)}})=-\sum_{j=1}^qy_j^{(i)}log\hat{y}_j^{(i)} H(y(i),y^(i))=−j=1∑qyj(i)logy^j(i)
交叉熵损失函数定义为: l ( Θ ) = 1 n ∑ i = 1 n H ( y ( i ) , y ^ ( i ) ) l(\Theta)=\frac{1}{n}\sum_{i=1}^nH(\boldsymbol{y^{(i)}},\boldsymbol{\hat{y}^{(i)}}) l(Θ)=n1i=1∑nH(y(i),y^(i))
简洁实现
softmax回归地简洁实现与线性回归基本相似,注意将损失函数改为交叉熵损失函数即可
loss = nn.CrossEntropyLoss()