【论文学习】:ICCV 2017-Detect-and-Track: Efficient Pose Estimation in Videos
项目配置链接:https://blog.csdn.net/m0_37644085/article/details/84338463
ps:不仔细学习RCNN系列→FCN→Mask RCNN是不太可能读懂这篇文章的。
---------2019.1.25
论文学习:
导读】近日,针对视频中场景复杂、人物众多等困难挑战,来自Facebook、CMU和达特茅斯学院的研究人员提出了一种新颖的基于检测和跟踪的视频中人体姿态估计方法。其方法是一种轻量级的两阶段建模方式:先对单帧或者短片段进行关键点估计,后续使用轻量级的跟踪方法来生成关键点的预测并链接到整个视频上。另外,本文还对Mask R-CNN进行了3D扩展。提出的方法在最新的多人视频姿态估计数据集PoseTrack上进行了大量的对比实验,在Multi-Object Tracking Accuracy (MOTA)度量下取得了55.2%的验证精度和51.8%的测试精度,并且在ICCV2017 PoseTrack keypoint tracking challenge 中取得了极佳的效果。
论文:Detect-and-Track: Efficient Pose Estimation in Videos
▌摘要
这篇文章致力于解决复杂的,多人视频下人体关键点的估计和跟踪。基于最新的人体检测和视频理解方面的进展,文章提出了一种极度轻量化和高效的两阶段方法:先对单帧或者短片段进行关键点估计,后续使用轻量级的跟踪方法来生成关键点的预测并链接到整个视频上;对于帧层次(frame-level)的姿态估计,本文使用了Mask R-CNN和提出的3D扩展,能够利用短片段上的时序信息来生成更加鲁棒的帧预测。
本文在最新的多人视频姿态估计数据集PoseTrack上进行了大量的对比实验,来验证模型中的多种设计选择。提出的方法在Multi-Object Tracking Accuracy (MOTA)度量下取得了55.2%的验证精度和51.8%的测试精度,并且在ICCV2017 PoseTrack keypoint tracking challenge 中取得了state-of-the-art的效果。
▌详细内容
最近几年,例如物体和场景识别等视觉理解任务在深度视觉表示的帮助下已经取得了惊人的突破。由于对大量实际应用的重要性,对图像中的人体行为进行建模和理解已经成为了视觉研究领域的一个热点。特别地,单张图片中的人体检测和姿态估计是视觉识别中的一个重要的、有挑战性的任务。
对于大量的、复杂的图像理解任务的引入,虽然单张图片的理解已经取得了很大的进步,但是视频理解目前尚未取得很大突破。虽然有一些工作为整个视频标注了单种动作类型,但是这些工作并没有关注随着时间的改变,以及如何对视频中场景、物体和人体等外观和语义上的变化进行建模。
在这篇文章中,主要关注复杂内容视频中人体姿态的跟踪,包含了整个时间段每个人姿态的跟踪和评估。这个任务存在很多挑战,包括姿态变化,遮挡和多个人体的重叠。理想的跟踪器必须根据对整个时间段外观和姿态改变的推理来对所有人的姿态进行预测。因此,实现一个姿态跟踪器不仅需要追求最好的姿态估计效果,并且需要很好地将特定个体层面上的时序信息融合进来。
大部分现有的视频姿态估计方法使用了手工设计的图模型或者整数规划优化,通过计算整个时间的预测来进行基于帧的关键点预测。虽然这些方法展现出良好的效果,但是他们要求对优化约束进行手工编程并且受计算复杂度的影响,从而无法在长时间的视频片段上进行拓展。更重要的是,这种跟踪优化方法只对帧层次的预测起作用,系统无法使用时序信息来提升对关键点的预测。(除了[41],但是只在单人视频中有效)。这就意味着,尽管帧与帧之间的信息是相关的并且十分明确的,如果一个帧画面的关键点定位的不好,比如由于部分遮挡或运动模糊,会使得预测结果无法得到提升。
为了解决这个问题,本文提出了一个简单且高效的方法,该方法使用了目前姿态估计中state-of-the-art的方法并使用一个新颖的3D Mask RCNN结构将视频相邻帧中的时序信息融合到其中。值得注意的是,这种方法保持了两阶段过程的简单性:帧层次的关键点估计通过在短片段上使用了一个滑动窗口运算来完成时空操作。这使得提出的3D模型能够在前后帧中传播有用的信息来使得每个帧的预测更加鲁棒,通过使用一个轻量级的长期跟踪模块,使得提出的方法可以在任意长视频上使用。图一解释了本文的方法。

图1,提出了一种两阶段的方法来进行视频中关键点预测和跟踪。第一阶段,本文提出了一种创新的视频姿态估计,3D Mask R-CNN,将一段视频的片段作为输入并检测出每个人的tubelet和关键点。在第二阶段,本文使用了一个轻量级的优化方法(匈牙利算法或者贪婪算法)来将整个时间段的检测结果联系起来。
本文在极具挑战性的PoseTrack dataset上训练并评估了提出的方法,这个数据集包含了人们在不同的日常场景中的视频,并且在所有帧上标注了人体关节的位置和对应的人体索引。首先,为了证实方法的有效性,受Mask R-CNN的启发,本文建立了一个关于帧层次的预测baseline。文章中的baseline方法在ICCV’17 PoseTrack Challenge上取得了state-of-the-art的结果,证明了他可以在这个新的数据集上拥有良好的表现。
然后作者接下来提出了对Mask R-CNN进行3D扩展,使用了短片段中的时序信息,使得在每个帧上产生更加鲁棒的预测结果。对于相同的基本结构和图像分辨率,作者提出的3D模型在关键点检测mAP上对于2D的baseline有2%的提升,在MOTA metric 上有1%的提升。并且,作者将最佳的模型在一个100帧的视频上运行了2分钟,使其能够随着时间顺序跟踪自身的运动,最终表现出了良好的实用潜力。与提出方法作为对比的是,IP formulation仅仅在跟踪上就使用了几十分钟,即使使用了最好的优化方法。
▌方法简介
Stage 1: Spatiotemporal pose estimation over clips.
类似地,从普通的(vanilla)Mask R-CNN模型出发,将二维卷积转化为三维。注意:这些3D内核的接受域跨越了空间和时间维度,并以一种端到端可学习的方式集成了时空线索。模型的输入不再是单个帧,而是由视频中的相邻帧组成的长度T的片段。将区域提议网络(region proposal network (RPN))[44]进行扩展,以预测跟踪输入片段框架内每个假设的候选对象。这些tube proposals用于通过spatiotemporal RoIAlign运算来提取特定实例的特征。然后将这些特征输入负责姿态估计的the 3D CNN head。这个姿态估计head输出所有关键点的热图激活值。因此,3D Mask R-CNN的输出是一组带有KeyPoint估计的tube hypotheses。
本文的算法流程如下所示:



(后二张是版本一的模型,辅助理解)
上图是本文提出的3D Mask R-CNN网络结构:包含三个主要部分。
-
基本的网络是一个标准的ResNet,拓展到了3D。它生成了一个3D feature blob,被用来通过Tube Proposal Network (TPN)生成proposal tubes。(RPN生成2D姿态建议框,TPN生成3D的姿态建议tube)
-
这些 tubes被用来从3D feature blob中提取区域特征,其使用了一个时空的RoIAlign机制来运算。
-
然后将这些proposal送入到一个分类/回归器(头部)中,另外使用一个关键点检测器来预测关键点的热度图。
Base network:将标准的ResNet结构扩展到3D ResNet体系结构,用3D卷积代替所有2d卷积。设定了内核(Kt)的时间范围来匹配空间宽度,除了第一卷积层,它使用了3×7×7的滤波器。对于空间维数,在时间上进行了修正:kt=3的padding为1,kt=1的padding为0。将时间步幅temporal strides设为1,因为经验发现,较大的步幅值会导致性能下降。使用预先训练的2d ResNet初始化了3D ResNet..
除了他们提出的“均值”初始化(临时复制2d滤波器,并将系数除以重复次数)之外,还实验了一种“中心”初始化方法,该初始化方法之前已经用于动作识别任务。在这个设置中,用2d滤波器权值初始化3D内核的central 2D slice,并将所有其他2d切片(对应于时间位移)设置为零。中心初始化方案提高了性能。对于T×H×W输入,the base 3D network的最终特征图输出为T×H/8×W/8,因为在第四个residual block之后裁剪网络,并且no temporal striding。
Tube proposal network:在Faster R-CNN中设计了一个tube proposal network,(由 region proposal network RPN)。上一步得到了base 3D network的特征图,将一个小的3D-conv网络连接到两个同级的全连接层-tube classification (cls) and regression (reg).。CLS和REG标签是针对tube anchors定义的。设计的tube anchors类似于Faster R-CNN中使用的bounding box anchors,但在这里及时地复制了它们。在每个滑动位置、不同的规模和/或纵横比,使用A(通常12)不同的anchors。因此,总共有H/8×W/8×A个anchors。对于每个这些anchors,CLS预测一个二进制值,显示来自该空间位置的foreground tube与proposal tube是否有很高的重叠。类似地,reg为每个anchor输出4T-dimensional矢量编码位移,该位移是根据tube中每个box的anchor坐标得来。
用Softmax分类损失来训练CLS层,对REG层使用the smoothed L1 loss。我们用T1来标度REG损失,以保持它的值与2d情况下的损失值相当。我们将这些损失定义为跟踪损失 tracking loss。
3D Mask R-CNN heads: 由上步tube proposal network产生的tube candidates,下一步将其分类,并将其归为关于人体追踪的a tight tube(around a person track.)。设计一个3D 区域转换算子来计算此tube的区域特征。扩展了旋转对齐运算(the RoIAlign operation),来从base network的输出中提取时空特征图(spatiotemporal featuremap)。 由于特征图与tube候选点的时态性temporal是相同的(维数t),将tube分割成T 2D box,并使用RoIAlign从特征图中的每个T时态切片中提取一个区域。
The regions are then concatenated in time (将这些区域及时连接起来)to produce a T × R × R feature map, where R is the output resolution of RoIAlign operation, which is kept 7 for the cls/reg head, and 14 for the keypoint head.
The classification head consists of a 3D ResNet block, similar to the design of the 3D ResNet blocks from the base network;and the keypoint head consists of 8 3D conv layers, followed by 2 deconvolution layers,to生成每个时间帧输入的KeyPoint的热图输出。 The classification head is trained with a softmax loss for the cls output and a smoothed L1 loss for the reg output, while the keypoint head is trained with a spatial softmax loss, similar to Mask R-CNN。
Stage 2: Linking keypoint predictions into tracks.
Given these keypoint predictions grouped in space by person identity (i.e., pose estimation), we need to link them in time to obtain keypoint tracks. Tracking can be seen as a data association problem over these detections.
关键点预测按人的身份在空间中分组(即姿态估计),我们需要及时地将它们联系起来,以获得关键点轨迹。在这些检测中,跟踪可以看作是一个数据关联问题。.在测试时,我们在每个帧上运行模型,并存储边界框和关键点预测,这些预测在跟踪阶段会随着时间的推移而链接起来
Previous approaches, such as [41], have formulated this task as a bipartite matching problem, which can be solved using the Hungarian algorithm [33] or greedy approaches. More recent work has incorporated deep recurrent neural networks (RNN), such as an LSTM [19], to model the temporal evolutions of features along the tracks [39,45].
We use a similar strategy, and represent these detections in a graph, where each detected bounding box (representing a person) in a frame becomes a node. We define edges to connect each box in a frame to every box in the next frame.
其中一帧每个检测到的边框(代表一个人)成为一个节点。边缘定义为将一帧中的每个框连接到下一个帧中的每个框(检测到的bbox是一个节点,边是帧间bbox的关联。)。
The cost of each edge is defined as the negative likelihood of the two boxes linked on that edge to belong to the same person.
该边缘的损失定义为连接的两个box属于同一个人边缘的负似然估计。
Given these likelihood values, we compute tracks by simplifying the problem to bipartite matching between each pair of adjacent frames.
有了似然估计,相邻帧之间的双向匹配来计算轨迹。
We initialize tracks on the first frame and propagate the labels forward using the matches, one frame at a time.Any boxes that do not get matched to an existing track instantiate a new track.
我们初始化第一个帧上的轨迹,每次一个帧,用matches前向传播标签。 任何与现有轨迹不匹配的框都会实例化一个新的轨迹。
As we show in Sec. 4.2, this simple approach is very effective in getting good tracks, is highly scalable, is able to deal with a varying number of person hypotheses, and can run on videos of arbitrary length.
Likelihood metrics: We experiment with a variety of handcrafted and learned likelihood metrics for linking the tracks. In terms of hand-crafted features, we specifically experiment with: 1) Visual similarity, defined as the cosine distance between CNN features extracted from the image patch represented by the detection; 2) Location similarity, defined as the box intersection over union (IoU) of the two detection boxes;and 3) Pose similarity, defined as the PCKh [53] distance between the poses in the two frames. We also experiment with a learned distance metric based on a LSTM model that incorporates track history in predicting whether a new detection is part of the track or not. At test time, the predicted confidence values are used in the matching algorithm, and the matched detection is used to update the LSTM hidden state. Similar ideas have also shown good performance for traditional tracking tasks [45].
似然估计的衡量有手工设计的和学习到的,手工设计的有余弦距离、IoU、姿态相似度。学习的使用LSTM模型。
PoseTrack数据集介绍:
1.for human body keypoint estimation and tracking in diverse, in-the-wild videos.
2.It consists of a total of 514 video sequences with 66,374 frames, split into 300, 50 and 208 videos for training, validation and testing, respectively.
3.The training videos come with the middle 30 frames densely labeled with human body keypoints. The validation and test videos are labeled at every fourth frame, apart from the middle 30 frames.
训练视频的中间30帧密集地标记着人体的关键点。除了中间的30帧之外,验证和测试视频每第四帧都有标记。
4.In total, the dataset contains 23,000 labeled frames and 153,615 poses.
5.The annotations consist of human head bounding boxes and 15 body joint keypoint locations per labeled person.
6.we compute a bounding box by taking the min and max extents of labeled keypoints, and dilating that box by 20%.
7.Also, to make the dataset compatible with COCO ,we permute(序列改变) the keypoint labels to match the closest equivalent labels in COCO. This allows us to pretrain our models on COCO, augmenting the PoseTrack dataset significantly and giving a large improvement in performance
8.evaluate methods: 1) Single-frame pose estimation; 2) Pose estimation in video; 3) Pose tracking in the wild. Task 1) and 2) are evaluated at a frame level, using the mean average precision (mAP平均精度) metric.Task 3) is evaluated using a multi-object tracking metric (MOT多目标跟踪度量). Both evaluations require first computing the distance of each prediction from each ground truth labeled pose. This is done using the PCKh metric,which computes the probability of correct keypoints normalized by the head size.
▌实验结果
图3 训练和测试数据中轨迹的数量和长度归一化后的直方图,注意由于训练数据的只有中间的30帧才有标签,训练数据中标注过的轨迹长度的最大值为30。另一方面,验证集和测试集中每4帧标注了一次(除了中间的30帧),因此可以用来评估模型进行长期跟踪的能力。并且,大部分的训练视频含有少于20个明显的轨迹标注,然而验证集有大约50个。
4.2. Baseline(泛读论文时候,此部分完全可以忽略,就是说它的模型、模块、方法怎样怎样好)

表1检测截止阈值的影响。将他们与计算轨迹匹配之前阈值化了Mask R-CNN计算出的检测结果。在关键点mAP下降时,由于更少的虚假检测,跟踪MOTA的效果上升。第一行展示了随机的baseline,模型的表现被随机分配为一个对于每个检测结果在0到1000之间的轨迹 ID。Since we primarily focus on the tracking task, we threshold our detections at 0.95 for our final experiments.
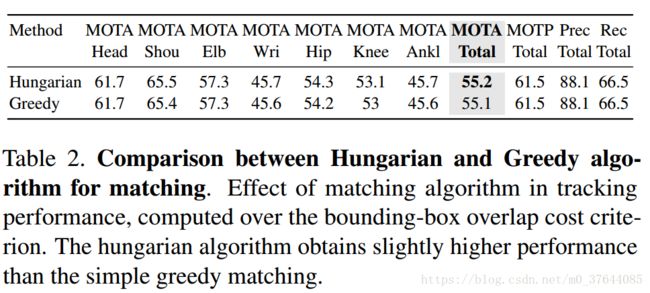
表2 Matching algorithm:在Hungarian算法和贪心匹配算法之间的比较。跟踪中匹配算法的影响。在bounding-box上计算重叠的损失标准.Hungarian算法比简单的贪心算法有轻微的提升。Hungarian算法在计算给定边缘代价矩阵的最优匹配时,贪婪算法从目标检测和跟踪的评价算法中得到启发。我们从最高置信度匹配开始,选择该边缘并删除两个连接节点。将当前帧中的每个预测框与前一个帧连接的过程从视频的第一帧重复应用到最后一帧。

表3Tracking cost criterion:box overlap。与不同的相似度损失度量的比较。在生成轨迹的匹配阶段,本文比较了多种不同的手工和学习到的损失标准。有趣的是,简单的手工方法在这个任务中表现的更好。由于更低的复杂度和更好的表现,本文选择使用简单的边界框重叠率。

表4,Upper bounds:在测试集上的最终表现。本文将提出的方法和现存的方法在这个数据集上的一个子集上进行比较。注意[22]给出了在PCKh0.34的结果;一个可比较的结果PCKh0.5结果通过私人方式得到。方法的表现通过递交其预测结果到评测服务器上得到。提出的模型是一个在训练集+验证集上训练得到的ResNet-101,跟踪在0.95的初始化检测阈值下进行hungarian匹配和边界框重叠率损失度量。这个模型目前超过ICCV’17 PoseTrack challenge中所有的方法。
图4采样结果。可视化两阶段模型在PoseTrack 验证集上的预测结果。作者展示了每段视频中的5帧,每帧都标记有检测框和关键点。根据预测后的 track id对检测框进行彩色编码。注意提出的模型能够在高度杂乱的环境下成功地跟踪行人。提出的模型一个失败的情况,在上述的视频片段中进行了阐述,由于遮挡无法进行跟踪。当这名滑板运动员走到钢管后面时,模型将无法跟踪但会在他重新出现时分配给一个新的track ID。

表5,将提出的3D Mask R-CNN与 baseline 2D模型进行比较,在PoseTrack challenge上取得了先进的的效果。由于GPU显存的限制,在两种模型上本文使用了基本的ResNet-18结构并且将图片转换为256pixels,(相比于使用Res-Net50和800px这将会导致表现下降)提出的3D模型在tracking任务上在MOTA and mAP度量上比2D帧层次的模型要好。作者也发现使用提出的“center” 初始化会有轻微的提升,(与 [5]中提出的 “mean” 初始化相反 )。
▌结论
本文提出了一种简单高效的方法进行视频中人体关键点的跟踪。提出的方法联合了state-of-the-art 的帧层次姿态估计方法和快速高效的人体层次跟踪模块,使得在整个时间段内可以连接关键点。通过大量的对比实验,本文探索了不同的模型设计选择,并在PoseTrack challenge benchmark上取得了极佳的效果。这表明了简单的Hungarian匹配算法能够在关键点跟踪中拥有极佳的表现,并且可以作为在这个问题和数据集上的一个有效的基准方法。
对于帧层次的姿态估计作者在一个Mask R-CNN和提出模型的3D 扩展上进行了实验,使用了小片段上的时序信息来生成更加鲁棒的预测。给出一个相同的基本结构和输入分辨率,作者发现提出的3DMask R-CNN相比于2D baseline取得了更好的效果。然而,2D R-CNN需要更少的GPU显存所以可以在高容量的模型(ResNet-101)上处理更高分辨率的图像(800pixels),使得这种简单的2D baseline在PoseTrack benchmark上的表现可以达到先进水平。作者相信随着GPU显存的提升,系统将有能力通过多个GPU来切分和训练模型,这是基于3D Mask R-CNN方法潜在的优势,特别是在高分辨率的图像和高容量的模型上。作者计划将这些方向作为未来的工作。
参考链接:
https://arxiv.org/abs/1712.09184
http://www.360doc.com/content/17/1230/18/45311621_717714479.shtml#
https://blog.csdn.net/cv_family_z/article/details/79864743