论文阅读|点云3D目标检测之PointPillars

源码:https://github.com/nutonomy/second.pytorch
PointPillars是对VoxelNet的改进,将VoxelNet中体素z轴的离散单位变成了整个z轴——柱,也就是说原来VoxelNet中体素是一个个格子,长宽高各有若干个,提取每个体素特征后得到一个3D特征tensor,而PointPillar的离散后单位是一个个立在x,y平面的柱,高为整个z轴,提取每个柱的特征后得到的是一个2Dtensor。于是,和VoxelNet相比,PointPillars就只需要用2DCNN对编码的tensor卷积,而不是计算量极大的3DCNN,从而极大的节约了时间。此外,作者在编码的适合增强每个点特征,除了有原来坐标信息外,还增加了 每个点相对柱中所有点中心点的位置(与其他点相关),以及相对柱的位置(与其它点无关)。使他既有局部特征又具有鲁棒性,不会因为采样时选取体素内不同点而得到不同结果。
VoxelNet中应用PointNet提取体素特征,然后将特征传入一系列3D卷积层,接着用2D骨干网处理,最后将骨干网输出的特征图传入检测头做最终的任务。这也实现了end-to-end学习,但是严重依赖3D卷积,速度很慢,推断时需要225ms,即4.4HZ。而其改进版本SECOND应用了稀疏卷积后速度仍然只有20Hz。PointPillars在速度和精度上都超过了他们,达到了62Hz,更快的版本能达到105Hz。
该工作的重要贡献就是编码部分,提出柱的编码方式,使得所有柱上的操作都能被变为密集的2D卷积从而加速计算。具体而言,这种方式的好处如下:
- 不用考虑每个bin的垂直单位;
- 基于柱提取得到的特征最后使用2D卷积计算,从而能够在GPU上高效计算;
- 不许多余调参来适应不同设备的点云。
PointPillars Network

PointPillars以点云为输入,能够预测有方向的3D边框。由3各部分组成(如上图所示):
- 一个特征编码网络,能够将点云转换为稀疏伪图像。
- 一个2D卷积骨干网将上一步编码得到的伪图像处理成一个高维度表示。
- 一个检测头,检测和回归3D边框。
下面分别介绍这三部分。
Pointcloud to Pseudo-Image
用 l l l指代点云中每个点,它有x,y,z三个维度。首先将点云在x,y平面上离散化为等距的格子,得到一个柱子的集合P。一个柱实际上就是一个z轴高度无限的体素,所以不需要参数限制z维。点云中每个点增强得到 r , x c , y c , z c , x p , y p r, x_c, y_c, z_c, x_p, y_p r,xc,yc,zc,xp,yp,对应反射强度,柱中所有点x,y,z的几何均值 x c , y c , z c , x_c, y_c, z_c, xc,yc,zc,,以及每个点相对柱中心的偏移 x p , y p x_p, y_p xp,yp 。装饰(增强)后的点云就有9个维度,D=9。由于点云稀疏性,大部分柱都不含点,并且非空的柱中的点也很少。
每个Pillar (栅格柱子) 的大小为 0.16 ∗ 0.16 0.16*0.16 0.16∗0.16, 可以理解为图像里的一个像素, 那么伪图像的尺寸就是 440 ∗ 500 440*500 440∗500. 因为~97% 的Pillar都很稀疏, 所以需要筛选出稠密(dense)的Pillar做卷积,选出的 Stacked Pillars的尺度为(D, P, N) 分别代表特长度D=9, Pillar的个数P=2847(假设), 点的数量N=100(假设), 这里用了一个简单的PointNet提取每个点特征, 然后应用一个后跟BN和ReLU的线性层得到尺度为(C, P, N) 的Tensor, 然后经过max操作得到尺寸为(C, P)的Tensor, 然后在反投影回伪图像上, 因为反投影的Pillar个数只有2847, 剩下的将被填充为0.由于选择Pillar而不是体素,能够跳过VoxelNet中3D卷积这一部分。
Backbone
骨干网由两个分支,一个是top-down的网络,生成分辨率越来越小的特征;还有一个在第一个分支生成特征图上做上采样然后做拼接。top-down分支框可以被分类一系列的block(S,L,F),对应于相对原始输入的stride S,3×3的输出F通道的2D卷积层数量L,每一个卷积后都跟有BN和ReLU。Block 的第一个卷积stride为 S / S i n S/S_{in} S/Sin,从而整个Block的stride为S。最终输出特征图是各个Block的特征图通过上采样和拼接得到的。即使用DeConv+BN+ReLU让每个分支的特征图空间尺寸和通道一样,然后concatenate得到骨干网输出。
Detection Head
我们使用SSD的设置执行3D目标检测,如果要用于其它任务,可以简单的交换网络头即可。和SSD相似,这里使用的是先眼眶和真实框的2DIoU来分配标签。边框的高度和海拔通过回归得到。
loss
损失函数和SECOND中一样,真实框和anchor都定义为(x, y, z, w, l, h, θ).位置回归定义为:

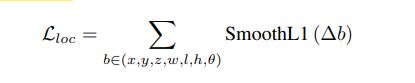
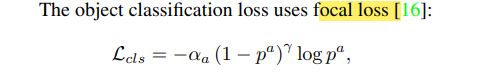
总损失如下:
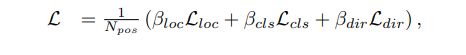
其中 L d i r L_{dir} Ldir是一个方向损失。
Experiments
