Scikit-learn代码运行
文章参考:使用scikit-learn进行机器学习的简易教程_风度78的博客-CSDN博客
scikit-learn 的介绍:针对Python 编程语言的免费软件机器学习库。它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
scikit-learn 的重要性:提供最先进的机器学习算法。
scikit-learn 的局限性:这些算法不能直接用于原始数据。 原始数据需要事先进行预处理。
因此,除了机器学习算法之外,scikit-learn还提供了一套预处理方法。此外,scikit-learn 提供用于流水线化这些估计器的连接器(即转换器,回归器,分类器,聚类器等)。
训练和测试分类器
digits数据集:手写数字的数据集
获取手写数据集
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits #导入digits数据集
X, y = load_digits(return_X_y=True)#获得手写数字数据
X.shape
结果表示:我们有 1,797 个数据样本,每个样本由 64 个维度组成。
打印图像
plt.imshow(X[0].reshape(8, 8), cmap='gray');# 下面完成灰度图的绘制
# 灰度显示图像
plt.axis('off')# 关闭坐标轴
print('The digit in the image is {}'.format(y[0]))# 格式化打印图表显示:

灰度图:灰度图每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255,灰度图像通常在单个电磁波频谱(如可见光)内测量每个像素的亮度得到的。用于显示的灰度图像通常用每个采样像素8位的非线性尺度来保存,这样可以有256级灰度。这种精度刚刚能够避免可见的条带失真,易于编程。
拆分数据集
y
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, stratify=y, test_size=0.25, random_state=42)
# 划分数据为训练集与测试集,添加stratify参数,以使得训练和测试数据集的类分布与整个数据集的类分布相同。使用fit方法学习机器学习模型
from sklearn.linear_model import LogisticRegression # 求出Logistic回归的精确度得分
clf = LogisticRegression(
solver='lbfgs', multi_class='ovr', max_iter=5000, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.4f}'.format(clf.__class__.__name__,
accuracy))结果显示:Logistic回归的准确度得分为0.96。
通过RandomForestClassifier替换LogisticRegression分类器
# ?clf.score
from sklearn.ensemble import RandomForestClassifier
# RandomForestClassifier轻松替换LogisticRegression分类器
clf = RandomForestClassifier(n_estimators=1000, n_jobs=-1, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))结果显示:RandomForestClassifier(随机森林)的准确度得分为0.97。
可以看出,LogisticRegression和RandomForestClassifier两个分类器的准确度得分相差很小,仅与分类器实例的创建有关。
from xgboost import XGBClassifier
clf = XGBClassifier(n_estimators=1000)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier(n_estimators=100, random_state=0)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))from sklearn.metrics import balanced_accuracy_score
y_pred = clf.predict(X_test)
accuracy = balanced_accuracy_score(y_pred, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))from sklearn.svm import SVC, LinearSVC
clf = SVC()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))结果显示:XGBClassifier、GradientBoostingClassifier的准确度分数为0.96,SVC的准确度分数为0.99。
clf = LinearSVC()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))结果显示:LinearSVC的准确度分数为0.94。
标准化数据
在学习模型之前预处理数据。线性模型使用的求解器期望数据被规范化。因此,我们需要在训练模型之前标准化数据。为了观察这个必要条件,我们将检查训练模型所需的迭代次数。
变换器的适用范围:
MinMaxScaler:归一化数据
StandardScaler:标准化数据
from sklearn.preprocessing import MinMaxScaler,StandardScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)clf = LinearSVC()
clf.fit(X_train_scaled, y_train)#拟合训练集
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,accuracy))#进行预测结果显示:LinearSVC的准确度分数为0.97。
from sklearn.preprocessing import MinMaxScaler,StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
clf = LinearSVC()
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,accuracy))结果显示:LinearSVC的准确度分数为0.95。
from sklearn.metrics import confusion_matrix, classification_report
y_pred = clf.predict(X_test_scaled)
print(confusion_matrix(y_pred, y_test))
结果显示:

import pandas as pd
#创建数据表
pd.DataFrame(
(confusion_matrix(y_pred, y_test)),#创建混淆矩阵(误差矩阵)
columns=range(10),
index=range(10))结果显示:

print(classification_report(y_pred, y_test))#输出模型评估报告相关链接:python机器学习classification_report()函数 输出模型评估报告_侯小啾的博客-CSDN博客_classification_report函数
结果显示:

交叉验证
使用交叉验证函数,我们可以快速检查训练和测试分数,并使用pandas快速绘图。
from sklearn.model_selection import cross_validate
clf = LogisticRegression(
solver='lbfgs', multi_class='auto', max_iter=1000, random_state=42)
scores = cross_validate(
clf, X_train_scaled, y_train, cv=3, return_train_score=True)
clf.get_params() #检查所有管道参数结果显示:

import pandas as pd
df_scores = pd.DataFrame(scores)
df_scores结果显示:

网格搜索调参
优化LogisticRegression分类器的C和penalty参数:
from sklearn.model_selection import GridSearchCV
clf = LogisticRegression(
solver='saga', multi_class='auto', random_state=42, max_iter=5000)
param_grid = {
'logisticregression__C': [0.01, 0.1, 1],
'logisticregression__penalty': ['l2', 'l1']
}
tuned_parameters = [{
'C': [0.01, 0.1, 1, 10],
'penalty': ['l2', 'l1'],
}]
grid = GridSearchCV(
clf, tuned_parameters, cv=3, n_jobs=-1, return_train_score=True)
grid.fit(X_train_scaled, y_train)结果显示:
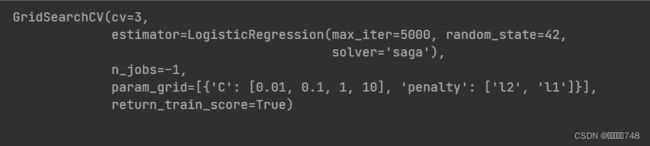
grid.get_params()结果显示:

df_grid = pd.DataFrame(grid.cv_results_)#访问属性cv_results_来得到网格搜索的结果。通过这个属性允许我们可以检查参数对模型性能的影响。
df_grid结果显示:

流水线操作
当必须手动进行预处理数据时,容易数据泄漏。因此引入Pipeline对象。它依次连接多个变压器和分类器(或回归器)。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_validate
X = X_train
y = y_train
pipe = make_pipeline(
MinMaxScaler(),
LogisticRegression(
solver='saga', multi_class='auto', random_state=42, max_iter=5000))
param_grid = {
'logisticregression__C': [0.1, 1.0, 10],
'logisticregression__penalty': ['l2', 'l1']
}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3, n_jobs=-1)
scores = pd.DataFrame(
cross_validate(grid, X, y, cv=3, n_jobs=-1, return_train_score=True))
scores[['train_score', 'test_score']].boxplot()结果显示:

pipe.fit(X_train, y_train)#使用fit来训练分类器
accuracy = pipe.score(X_test, y_test)#使用socre来检查准确性。
print('Accuracy score of the {} is {:.2f}'.format(pipe.__class__.__name__, accuracy))结果显示:Pipeline的准确度分数为0.96。
pipe.get_params()结果显示:

练习 异构数据
import os
data = pd.read_csv('data/titanic_openml.csv', na_values='?')
data.head()#查看前五行数据结果显示:

泰坦尼克号数据集包含分类,文本和数字特征。 我们将使用此数据集来预测乘客是否在泰坦尼克号中幸存下来。
让我们将数据拆分为训练和测试集,并将幸存列用作目标。
y = data['survived']
X = data.drop(columns='survived')
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
#使用OneHotEncoder对每个分类特征进行读热编码
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
ohe = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder())
X_encoded = ohe.fit_transform(X_train[['sex', 'embarked']])
X_encoded.toarray()结果显示:

标准化数字特征:将原始数据分成2个子组并应用不同的预处理:(i)分类数据的独热编;(ii)数值数据的标准缩放(归一化)。
col_cat = ['sex', 'embarked']
col_num = ['age', 'sibsp', 'parch', 'fare']
X_train_cat = X_train[col_cat]
X_train_num = X_train[col_num]
X_test_cat = X_test[col_cat]
X_test_num = X_test[col_num]
from sklearn.preprocessing import StandardScaler
scaler_cat = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder())
X_train_cat_enc = scaler_cat.fit_transform(X_train_cat)
X_test_cat_enc = scaler_cat.transform(X_test_cat)
scaler_num = make_pipeline(SimpleImputer(strategy='mean'), StandardScaler())
X_train_num_scaled = scaler_num.fit_transform(X_train_num)
X_test_num_scaled = scaler_num.transform(X_test_num)
import numpy as np
from scipy import sparse
#转为稀疏矩阵
X_train_scaled = sparse.hstack((X_train_cat_enc,
sparse.csr_matrix(X_train_num_scaled)))
X_test_scaled = sparse.hstack((X_test_cat_enc,
sparse.csr_matrix(X_test_num_scaled)))使用LogisticRegression分类器
clf = LogisticRegression(solver='lbfgs')
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.4f}'.format(clf.__class__.__name__, accuracy))结果显示:LogisticRegression的准确度分数为0.7866。