阅读笔记:《机器学习》西瓜书(7)——贝叶斯分类
贝叶斯分类
- 贝叶斯决策论
- 极大似然估计
- 朴素贝叶斯分类器
- 半朴素贝叶斯分类器
- 贝叶斯网
-
- 贝叶斯网的结构
- 贝叶斯网络的推断
- EM算法
- 本文参考
贝叶斯分类最核心的概念来源于贝叶斯公式,即对于随机事件A和B:
P ( A i ∣ B ) = P ( B ∣ A i ) P ( A i ) ∑ j P ( B ∣ A j ) P ( A j ) P(A_i|B)=\frac{P(B|A_i)P(A_i)}{\sum_j{P(B|A_j)P(A_j)}} P(Ai∣B)=∑jP(B∣Aj)P(Aj)P(B∣Ai)P(Ai)
因此,在知道了先验概率 P ( A i ) P(A_i) P(Ai)和传递概率 P ( B ∣ A i ) P(B|A_i) P(B∣Ai)后,可以求得后验概率 P ( A i ∣ B ) P(A_i|B) P(Ai∣B),其中传递概率也被称为“似然”。
贝叶斯决策论
在所有的相关概率都已知的情况下,以多分类为例,假设有 N N N种可能的类别 Y = c 1 , c 2 , … , c N Y={c_1,c_2,\dots,c_N} Y=c1,c2,…,cN。其中将 c j c_j cj错误识别为 c i c_i ci的损失为 λ i j \lambda_{ij} λij,可以得到将样本 x \boldsymbol{x} x识别为 c i c_i ci所产生的损失的期望为:
R ( c i ∣ x ) = ∑ j = 1 N λ i j P ( c j ∣ x ) R(c_i|\boldsymbol{x})=\sum^N_{j=1}{\lambda_{ij}P(c_j|\boldsymbol{x})} R(ci∣x)=j=1∑NλijP(cj∣x)
为做出尽可能正确的分类,需要找到一个 h : X → Y h:X\rightarrow Y h:X→Y使得总的损失期望最小。而总的损失期望等于样本空间 X X X中所有样本在映射 h h h下的损失期望之和,由于样本空间一般具有无穷性,我们很难例举并依次求和得到结果。因此,考虑使用贝叶斯判定准则:为最小化总体损失期望,只需要找到这样的映射 h h h,使得对于每个已知样本及其通过 h h h所确定的类别的期望损失最小,即:
h ∗ ( x ) = arg min c ∈ Y R ( c ∣ x ) h^*(\boldsymbol{x})=\mathop{\arg \min}\limits_{c\in Y}{R(c|\boldsymbol{x})} h∗(x)=c∈YargminR(c∣x)
其中 h ∗ h^* h∗称为贝叶斯最优分类器,对应的总体风险 R ( h ∗ ) R(h^*) R(h∗)称为贝叶斯风险, 1 − R ( h ∗ ) 1-R(h^*) 1−R(h∗)反映了机器学习模型精度的理论上限(从信息的角度分析机器学习的理论上限)。
λ i j \lambda_{ij} λij的一般形式:(是否有可以使用的其他形式?)
λ i j = { 0 , i f i = j 1 , o t h e r w i s e \lambda_{ij}=\left\{ \begin{aligned} 0,&if i=j \\ 1,&otherwise \end{aligned} \right. λij={0,1,ifi=jotherwise
则有:

这样,只要选择 h h h使后验概率 P ( c ∣ x ) P(c|\boldsymbol{x}) P(c∣x)尽可能大即可。(从信息传递的角度理解即为信息尽可能不失真)
但后验概率并不是已知的,为估计后验概率:

(判别式模型和生成式模型,前者直接建模得到后验概率,后者通过联合概率再得到后验概率)
这时贝叶斯公式即可派上用场:
P ( c ∣ x ) = P ( x ∣ c ) P ( c ) P ( x ) P(c|\boldsymbol{x})=\frac{P(\boldsymbol{x}|c)P(c)}{P(\boldsymbol{x})} P(c∣x)=P(x)P(x∣c)P(c)
那么只要知道先验概率和条件概率“似然”,就可以得到后验概率。先验概率可以根据大数定律从有足够样本的训练集中用频率进行估计得到。但条件概率 P ( x ∣ c ) P(\boldsymbol{x}|c) P(x∣c)是所有属性上的联合概率,难以从有限的训练样本直接估计而得。因此需要使用一些其他的方法进行估计。
极大似然估计
极大似然估计是一种常用的参数估计方法,用于估计某事件在假定了固定的概率分布形式后的概率分布参数,进而得到事件的概率分布。
因此,可以通过极大似然估计得到每个种类 c c c对应事件的概率分布 p ( x ∣ c ) p(\boldsymbol{x}|c) p(x∣c),从而很简单地求得条件概率。但该方法极依赖于概率分布模型的选取。
朴素贝叶斯分类器
为避开这个障碍,朴素贝叶斯分类器(naÏve Bayes classifier) 采用了"属性条件独立性假设":对已知类别,假设所有属性相互独立。即:


另外,常用拉普拉斯修正以保证条件概率不为0:

半朴素贝叶斯分类器
朴素贝叶斯分类器假设所有的属性条件( x 1 , x 2 , … , x m x_1,x_2,\dots,x_m x1,x2,…,xm)都相互独立,但事实上这个假设很难成立。半朴素贝叶斯分类器的基本想法是适当考虑一部分属性问的相互依赖信息,从而既不需进行完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。
- 独依赖估计(ODE)
所谓"独依赖"就是假设每个属性在类别之外最多仅依赖于一个其他属性,称为父属性。不同的父属性选取方式会产生不同的ODE。(TAN使用到了条件互信息以建立有向的最大带权生成树)(如何得到最大生成树?有向最大生成树?)
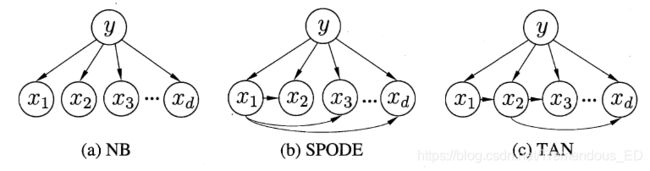
- kDE
随着条件概率属性的依赖属性个数的增加,模型的泛化性能将越来越好,但也会带来需要大量训练集的困扰。
贝叶斯网

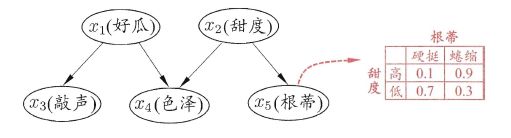
因此,贝叶斯网络的联合概率分布可以定义为:
P ( x 1 , … , x m ) = ∏ i = 1 m P B ( x i ∣ π i ) = ∏ i = 1 m θ x i ∣ π i P(x_1,\dots,x_m)=\prod _{i=1}^m{P_B(x_i|\pi _i)}=\prod _{i=1}^m{\theta_{x_i|\pi _i}} P(x1,…,xm)=i=1∏mPB(xi∣πi)=i=1∏mθxi∣πi
贝叶斯网的结构
贝叶斯网络的结构单元主要包括一下三种:
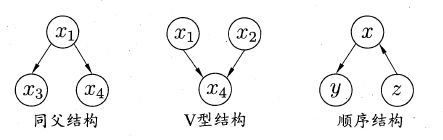
在同父结构中,给定 x 1 x_1 x1的值, x 3 , x 4 x_3,x_4 x3,x4条件独立,记作 x 3 ⊥ x 4 ∣ x 1 x_3\perp x_4\mid x_1 x3⊥x4∣x1;
在顺序结构中,给定 x x x的值, y , z y,z y,z条件独立,记作 y ⊥ z ∣ x y\perp z\mid x y⊥z∣x;
在V型结构中,给定 x 4 x_4 x4的值, x 1 , x 2 x_1,x_2 x1,x2不条件独立,只有当 x 4 x_4 x4的值未知, x 1 , x 2 x_1,x_2 x1,x2才条件独立,这样的独立性被称为边际独立性,记作 x 1 ⊥ ⊥ x 2 x_1\perp\!\!\!\!\perp x_2 x1⊥⊥x2。
为判断贝叶斯图这一有向图中的条件独立性,一般把其改为无向图:
- 找出图中的V型结构,在两个父节点之间加上无向边,称为“道德化”,得到的无向图为”道德图“。
- 将所有的有向边改为无向边。
- 若变量 x , y x,y x,y在图上被变量集合 z \boldsymbol{z} z分开,但是去掉变量集合 z \boldsymbol{z} z之后, x , y x,y x,y分属两个连通分支,则称 x , y x,y x,y被 z \boldsymbol{z} z有向分离,即有 x ⊥ y ∣ z x\perp y\mid z x⊥y∣z。
若网络结构己知,即属性间的依赖关系己知,则贝叶斯网的构建过程将十分简单。但实际上往往并不知道网络结构。因此需要根据训练集来找到一个比较好的贝叶斯网结构。
通常的做法是基于信息论准则,将学习问题看作一个数据压缩任务,学习的目标是找到一个能以最短编码长度描述训练数据的模型,这种方法被称作**“最小描述长度(MDL)”**准则。对于给定的训练集 D D D和贝叶斯网 B B B来说,这种编码一般包括:
- 网络描述编码(这种编码具有什么样的意义?)
这种编码用来描述贝叶斯网模型自身,其编码长度表示为:
f ( θ ) ∣ B ∣ f(\theta)|B| f(θ)∣B∣
其中, ∣ B ∣ |B| ∣B∣是贝叶斯网的参数个数, f ( θ ) f(\theta) f(θ)表示描述每个参数 θ \theta θ所需的字节数。 - 数据编码(这种编码又具有什么样的意义?)
这种编码用于描述事件 x \boldsymbol{x} x的概率分布,其编码长度表示为:
L L ( B ∣ D ) = − ∑ i = 1 m log P B ( x i ) LL(B|D)=-\sum _{i=1}^m{\log {P_B(x_i)}} LL(B∣D)=−i=1∑mlogPB(xi)
编码总长度(评分函数)为:
s ( B ∣ D ) = f ( θ ) ∣ B ∣ − ∑ i = 1 m log P B ( x i ) s(B|D)=f(\theta)|B|-\sum _{i=1}^m{\log {P_B(x_i)}} s(B∣D)=f(θ)∣B∣−i=1∑mlogPB(xi)
若贝叶斯网的网络结构固定,则评分函数的第一项为常数。此时,最小化 s ( B ∣ D ) s(B|D) s(B∣D)等价于对参数 Θ \Theta Θ的极大似然估计,而这些参数可以直接在训练数据 D D D上通过经验估计获得。因此,只需要搜索贝叶斯网所有的可能结构并计算其评分函数,选择其中评分函数最小的结构即可。
然而,搜索所有的网络结构是一个NP难问题。只能通过贪心法或限制网络结构的方法求得较优解。
贝叶斯网络的推断
利用已知变量推断未知变量的分布称为“推断”,其核心是基于可观测变量推测出未知变量的条件分布。
贝叶斯网络的推断使用吉布斯采样策略进行近似推断。对于任意事件 x = e , \boldsymbol{x}=\boldsymbol{e}, x=e,令 Q \boldsymbol{Q} Q表示待查询变量空间, q \boldsymbol{q} q为待查询变量可能的取值, E \boldsymbol{E} E表示证据变量空间, e \boldsymbol{e} e为证据变量确定的取值,目标是计算 P ( Q = q ∣ E = e ) P(\boldsymbol{Q}=\boldsymbol{q}\mid \boldsymbol{E}=\boldsymbol{e}) P(Q=q∣E=e),吉布斯采样算法如下图所示:

这种方法事实上是在贝叶斯网所有变量构成的空间在 E = e \boldsymbol{E}=\boldsymbol{e} E=e的子空间内进行“随机漫步”的过程。这种每一步依赖于前一步的过程实际上是一个马尔可夫链随机漫步。当 t → ∞ t\rightarrow \infty t→∞时,该过程收敛于一个平稳分布。
通常马尔科夫链需要较长时间才能区域平稳,因此此算法收敛速度慢。此外若贝叶斯网中存在极端概率,马尔科夫链将不能保证平稳分布(有点迷糊)。
EM算法
由于训练样本不一定完整,不一定能够含有所有的证据变量。当遇到存在不完整的训练样本时(即某些证据变量值未知,称为隐变量),可以使用EM算法对模型参数进行估计。它是一种迭代式的方法,其基本想法是:若参数 Θ \Theta Θ己知,则可根据训练数据推断出最优隐变量 Z Z Z的值(E 步);反之,若 Z Z Z的值已知,则可方便地对参数 Θ \Theta Θ做极大似然估计(M 步)。
(书上介绍的太笼统有点看不懂。。。。查查资料再补。。。。)
本文参考
贝叶斯网