opencv_python 深度估计与图像分割
opencv_python 深度估计与图像分割
半全局块匹配(Semi-Global Block Matching)算法
- 计算每个像素点的代价
原论文使用的方法是利用互信息熵,而OpenCV使用的是Birchfield和Tomasi的方法(参照《Depth Discontinuities by Pixel-to-Pixel Stereo》)。
1.1 利用互信息熵
所谓的熵,是用来表示随机变量的不确定性,熵的值越大,信息的不确定性也越大。熵H和互信息MI的定义分别如下:

![]()
其中,PI代表某个点i的概率分布,也就是灰度直方图为i的点出现的概率;对应地,PI1,I2就是两个图对应点i1和i2的联合概率分布,也就是:
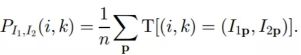
Kim等人将上式做了一个改进:利用泰勒展开把HI1,I2的计算转化为求和问题参见论文《Visual Correspondence Using Energy Minimization and Mutual Information》)。

其中圈中带叉表示卷积运算,g(i,k)为高斯卷积核。
相应地,边缘熵以及边缘概率的计算如下:
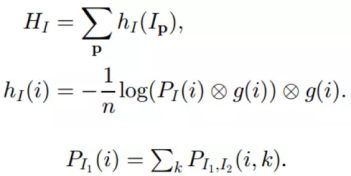
这样的话,互信息的定义为:
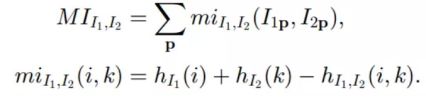
MI匹配代价CMI为:
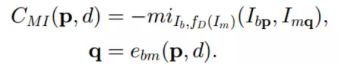
其中q是点p在视差为d的情况下的对应校正点。

原作者使用分层互信息(HMI)进行计算,每一层尺寸减少一半。单次计算的时间复杂度是O(WHD),即width×height×disparity range,所以上次迭代将会是当前迭代速度的1/8。

这里1/163要乘3的原因是小尺寸的随机视差图不靠谱,需要迭代3次。我们可以看到,相比于后文的BT方法仅仅慢了14%
1.2 Birchfield和Tomasi的方法(简称BT方法)
对于一个匹配序列M,其代价函数γ(M)表示匹配结果不准确的程度,其值越小越好。

其中,κocc表示未匹配的惩罚项(constant occlusion penalty),κr表示匹配的奖励项,Nocc和Nr分别表示未匹配和匹配的点数。
- 损失聚合
我们为视差设置一个能量函数E(D)
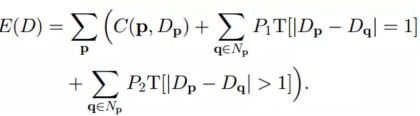
其中P1和P2分别表示视差差值为1和视差差值大于1的惩罚系数,一般P1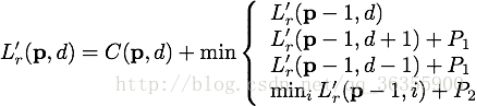
代价聚合公式(向量中的一个元素的成本等于当前位置的成本加上先前像素位置的所有可能视差集合的最低总和成本。)
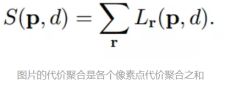
选取使代价聚合最小的视差值mindS[emb(q,d),d]即可。
普通摄像头进行深度估计
使用普通摄像头进行深度估计主要用到的方法是几何学中的极几何,它属于立体视觉(stereo vision)几何学。立体视觉几何学是计算机视觉的一个分支,从同一物体的两张不同图像提取三维信息
视差:从一定距离的两个点上观察同一目标所产生的方向差异(百度百科),使用视差角来衡量
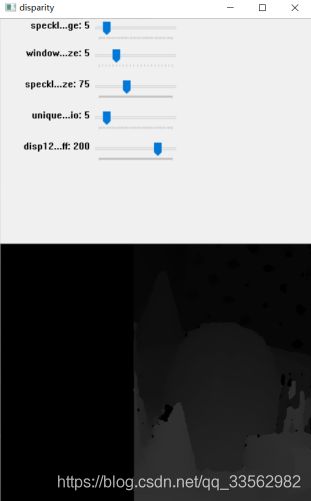
下面为使用OpenCV 如何使用极几何计算视差图,它是对图像中检测到的不同深度的基本表示。这样就能提取出一张图片的前景部分而抛弃其他部分。
首先需要同一物体在不同视角下拍摄两幅图像,但是要注意的是这两幅图像是距物体相同距离拍摄的,否则计算将会失败,视差图也就没有了意义.

代码实现:
import numpy as np
import cv2
def update(val=0):
stereo.setBlockSize(cv2.getTrackbarPos('window_size', 'disparity'))
stereo.setUniquenessRatio(cv2.getTrackbarPos('uniquenessRatio', 'disparity'))
stereo.setSpeckleWindowSize(cv2.getTrackbarPos('speckleWindowSize', 'disparity'))
stereo.setSpeckleRange(cv2.getTrackbarPos('speckleRange', 'disparity'))
stereo.setDisp12MaxDiff(cv2.getTrackbarPos('disp12MaxDiff', 'disparity'))
print ('computing disparity...')
disp = stereo.compute(imgL,imgR).astype(np.float32) / 16.0
cv2.imshow('left', imgL)
cv2.imshow('disparity', (disp - min_disp) / num_disp)
if __name__ == "__main__":
window_size = 5
min_disp = 16
num_disp = 192 - min_disp
blockSize = window_size
uniquenessRatio = 1
speckleRange = 3
speckleWindowSize = 3
disp12MaxDiff = 200
P1 = 600
P2 = 2400
imgL = cv2.imread('img/left.png')
imgR = cv2.imread('img/right.png')
cv2.namedWindow('disparity')
# 最后一个参数为回调函数
cv2.createTrackbar('speckleRange', 'disparity', speckleRange, 50, update)
cv2.createTrackbar('window_size', 'disparity', window_size, 21, update)
cv2.createTrackbar('speckleWindowSize', 'disparity', speckleWindowSize, 200, update)
cv2.createTrackbar('uniquenessRatio', 'disparity', uniquenessRatio, 50, update)
cv2.createTrackbar('disp12MaxDiff', 'disparity', disp12MaxDiff, 250, update)
stereo = cv2.StereoSGBM_create(
minDisparity=min_disp,
numDisparities=num_disp,
blockSize=window_size,
uniquenessRatio=uniquenessRatio,
speckleRange=speckleRange,
speckleWindowSize=speckleWindowSize,
disp12MaxDiff=disp12MaxDiff,
P1=P1,
P2=P2
)
update()
cv2.waitKey()
使用GrabCut进行前景检测:
视差图对检测图片前景部分很有用,StereoSGBM 是很好的一种方法,但是它主要是从二维图片中获取三维信息。真正的实现前景检测和显示还是需要 grabCut() 实现,算法的实现步骤:
1.预定以一个含有(一个或多个)物体的矩形(必须包含想要分割的物体)
2.矩形外的区域都会被认为是背景部分
3.对于预定义的矩形部分,会通过背景部分区分其中的背景和前景区域。
4.用高斯混合模型(Gaussians Mixture Model, GMM)来对背景和前景建模,未定义部分标记为可能的前景或背景(可能是前景,可能是背景)
5.图像中的每一个像素点都被看作通过一条虚拟边与周围像素点相连接,每条边都有一个属于前景或背景的概率,这基于它与周围像素颜色的相似性(一般同一物体的像素点具有连续性和相似性)
6.每一个像素点会与前景或背景节点连接
7.在节点连接完成后会存在,若节点之间的边属于不同终端则将他们分离出来了
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread("img/lena.jpg")
# 创建与图像大小相同的黑色掩膜
mask = np.zeros(img.shape[:2], np.uint8)
# 定义前景和背景模型
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
# 预定义包含想分割出来前景的矩形
rect = (50, 20, 210, 270)
# 调用GrabCut方法
# 第6个参数为迭代次数
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5, cv2.GC_INIT_WITH_RECT)
# 调用GrabCut后掩膜mask只有0~3的值,0-背景,1-前景,2-可能的背景,3-可能的前景
# 使用no.where方法将0和2转为0,1和3转为1,然后保存在mask2中
mask2 = np.where((mask==2)|(mask==0), 0, 1).astype('uint8')
# 使用mask2将背景与前景部分区分开来
img = img*mask2[:, :, np.newaxis]
plt.subplot(121), plt.imshow(img)
plt.title('grabcut'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(cv2.cvtColor((cv2.imread('img/lena.jpg')), cv2.COLOR_BGR2RGB))
plt.title('original'), plt.xticks([]), plt.yticks([])
plt.show()

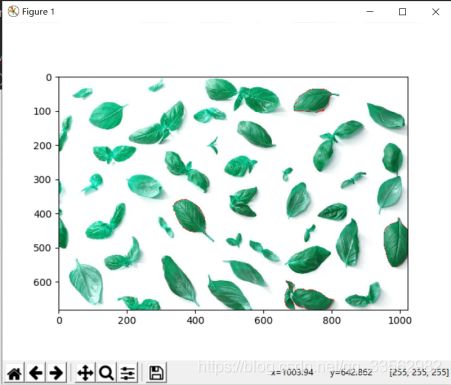
用分水岭算法进行图像分割:
算法叫做分水岭是因为有水的概念。把图像中低密度的区域(变化很少)想象成山谷,图像中高密度的区域(变化很多)想象成山峰。开始向山谷中注入水知道不同的山谷中的水开始汇聚。为了阻止不同山谷的水汇聚,可以设置一些栅栏,最后得到的栅栏就是图像分割。
算法过程:
1.将图像二值化
2.形态学开变换 morphologyEX去除图像中的小白点
3.膨胀获取绝大部分为背景的图像
4.使用distanceTransform 获取前景部分
5.重合部分利用背景和前景相减获取(一般为边界处)
6.使用connectedComponents 获得标记(将背景标记为0,其他对象用从1开始的整数标记)
7.将标记加一(防止背景部分被当作unknown),将unknown 部分置0
8.最后打开门,让水漫起来并把栅栏设置为红色
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('img/basil.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 设置一个阈值,将图像分成两部分:黑色部分和白色部分
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
# 通过morphologyEx变换来去除噪声数据,这是一种对图像膨胀之后再腐蚀的操作,可以提取图像特征
kernal = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernal, iterations=2)
# 通过对morphologyEx变换后的图像进行膨胀操作,可以得到大部分都是背景的区域
sure_bg = cv2.dilate(opening, kernal, iterations=3)
# 反之,通过distanceTransform来获取确定的前景区域。(越是远离背景区域的边界的点越可能属于前景)
# 在得到distanceTransform操作的结果后用一个阈值来决定哪些区域是前景。
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
ret, sure_fg = cv2.threshold(dist_transform, 0.7*dist_transform.max(), 255, 0)
# 处理前景与背景的重合区域(相减)
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg, sure_fg)
# 设置“栅栏”阻止水的汇聚,
ret, markers = cv2.connectedComponents(sure_fg)
# 在背景区域上加1,这会将unknown区域设为0
markers = markers+1
markers[unknown==255] = 0
# 打开门,让水漫起来并把栅栏绘成红色
markers = cv2.watershed(img, markers)
img[markers==-1] = [255, 0, 0]
plt.imshow(img)
plt.show()
参考文章:
https://blog.csdn.net/qq_36754767/article/details/90906105
https://www.jianshu.com/p/cbe50ede70aa