torch.nn
torch.nn 与 torch.nn.functional
说起torch.nn,不得不说torch.nn.functional!
这两个库很类似,都涵盖了神经网络的各层操作,只是用法有点不同,比如在损失函数Loss中实现交叉熵! 但是两个库都可以实现神经网络的各层运算。其他包括卷积、池化、padding、激活(非线性层)、线性层、正则化层、其他损失函数Loss,两者都可以实现不过nn.functional毕竟只是nn的子库,nn的功能要多一些,还可以实现如Sequential()这种将多个层弄到一个序列这样复杂的操作。
nn.functional.xxx 是**函数接口**,nn.Xxx 是 .nn.functional.xxx 的**类封装**
nn.Xxx 除了具有 nn.functional.xxx 功能之外,内部附带 nn.Module 相关的属性和方法,eg. train(), eval(), load_state_dict, state_dict
如何看关于torch.nn的 API
首先看左侧,这些都是功能的分类! 比如Containers中就包含了 集合各种神经网络的操作的 容器;
而Convolution Layers则是抱哈了各种卷积操作! 如果我们想要调用的话,不是torch.nn.Containers,而是torch.nn.Moule()、torch.nn.Sequential() 等

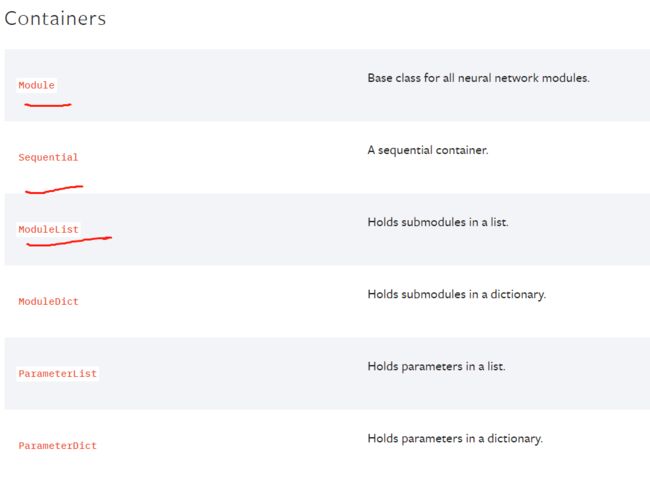
torch.nn中某些函数
1. torch.nn.Parameter()
一种张量,被认为是一个模参数。
Parameter是Tensor的子类,当与Module s一起使用时,它们有一个非常特殊的属性——当它们被分配为模块属性时,它们会自动添加到参数列表中,并将出现在Parameters()迭代器中(可以通过nn.Moudle.Parameter()获得)。
赋值一个张量没有这样的效果。这是因为人们可能想要在模型中缓存一些临时状态,比如RNN的最后一个隐藏状态。如果没有Parameter这样的类,这些临时对象也会被注册。
参数:
- data(张量)–parameter tensor。
- Requires_grad (bool,optional)—如果参数需要渐变。有关更多细节,请参阅局部禁用梯度计算。默认值:True
Parameter Vs Tensor:
首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
所以如果只是单纯的线性层or卷积层,是可以使用tensor的;
但是如果是在模型中,也就是Containers容器中的,那么就必须是Parameter类型

在concat注意力机制中,权值V是不断学习的所以要是parameter类型。
通过做下面的实验发现,linear里面的weight和bias就是parameter类型,且不能够使用tensor类型替换,还有linear里面的weight甚至可能通过指定一个不同于初始化时候的形状进行模型的更改。

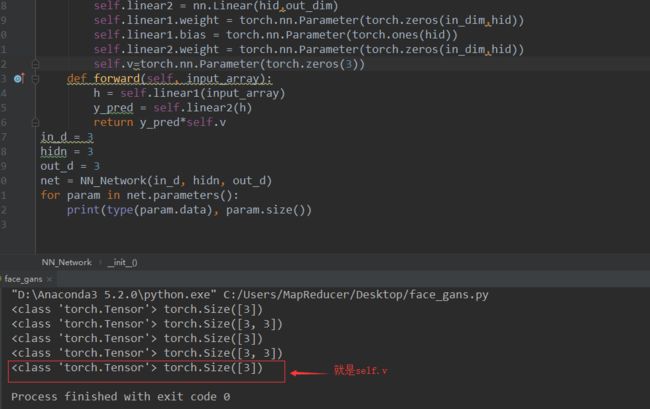
与torch.tensor([1,2,3],requires_grad=True)的区别,这个只是将参数变成可训练的,并没有绑定在module的parameter列表中。
Containers()
2. torch.nn.Module()
所有神经网络模块的基类。
可以看博客
3. torch.nn.Sequential()
顺序容器。
顺序容器。Modules将按照它们在构造函数中传递的顺序添加到它中。另外,Modules的OrderedDict可以被传入。Sequential的forward()方法接受任何输入并将其转发到它包含的第一个Module。然后,它将输出按顺序链接到每个后续Module的输入,最后返回最后一个Module的输出。
一个Sequential通过手动调用模块序列提供的值是,它允许将整个容器视为单个Module,这样在Sequential上执行转换将应用于它存储的每个Module(每个Module都是Sequential的注册subModule)。
Sequential和torch.nn.ModuleList的区别是什么?ModuleList就是一个用来存储Module的列表!另一方面,Sequential中的各层以级联方式连接。
举例:
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
4. torch.nn.ModuleDict()
在字典中保存子模块。
ModuleDict可以像普通的Python字典一样被索引,但它包含的Module是正确注册的,所有Module方法都可以看到它。
ModuleDict是一个有序字典,它反映了
- 插入的顺序,和
- 在update()中,合并的OrderedDict、dict(从Python 3.6开始)或另一个ModuleDict (**update()**的参数)的顺序。
注意,对于其他无序映射类型的update()(例如,Python 3.6版之前的普通dict)不会保留合并映射的顺序。
参数:
Modules (iterable, optional)——(string: module)的映射(字典)或键值对类型的可迭代对象(string, module)
实例:
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict([
['lrelu', nn.LeakyReLU()],
['prelu', nn.PReLU()]
])
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
项目中的实例:
self.conv_filters = nn.ModuleDict({
str(x): nn.Conv2d(3 if self.config.use_context else 2,
self.config.num_filters,
(x, self.config.word_embedding_dim))
for x in self.config.window_sizes
})
方法:
1、 clear()
从ModuleDict中删除所有项。
2、items()
返回ModuleDict键/值对的可迭代对象。
3、keys()
返回ModuleDict键的可迭代对象。
4、pop(key)
从ModuleDict中移除key并返回它的模块。
参数:key (string) -从ModuleDict中弹出的键
5、update(modules)
使用映射或可迭代对象的键值对更新ModuleDict,覆盖现有的键。
如果modules是OrderedDict、ModuleDict或键值对的可迭代对象,则其中新元素的顺序将保留。
参数: modules (iterable)——一个从字符串到模块的映射(字典),或者一个键值对类型的可迭代对象(string, Module)
6、values()
返回ModuleDict值的可迭代对象。
Convolution Layers
5. torch.nn.Conv1d
6. torch.nn.Conv2d
方法:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
参数:
-
in_channels (int) -输入图像中的通道数
-
out_channels (int) -由卷积产生的信道数
-
kernel_size (int或tuple) -卷积内核的大小
-
stride (int或tuple,optional)——卷积的stride。默认值:1
-
padding (int, tuple或str,optional)-添加到输入所有四方的padding。默认值:0
-
Padding_mode (string,optional)- ‘zeros’, ‘reflect’, ’ replication ‘或’circular’。默认值:“0”
-
dilation(int或tuple,optional)-内核元素之间的间距。默认值:1
-
groups (int,optional)-从输入通道到输出通道的阻塞连接数。默认值:1
-
bias (bool,optional)-如果为True,则在输出中添加一个可学习的偏差。默认值:True

变量:
- ~Conv2d.weight (Tensor):(out_channels, i n − c h a n n e l s g r o u p s \frac{ in-channels}{groups} groupsin−channels , kernel_size[0], kernel_size[1]). 这些权重的值是从 U ( − k , k ) \mathcal{U}(-\sqrt{k}, \sqrt{k}) U(−k,k)取样,其中 k = groups C in ∗ ∏ i = 0 1 kernel-size [ i ] k=\frac{\text { groups }}{C_{\text {in }} * \prod_{i=0}^{1} \text { kernel-size }[i]} k=Cin ∗∏i=01 kernel-size [i] groups
- ~Conv2d.bias (Tensor) : 可学习bias的形状(out_channels)。如果偏差是True, 那么这些权重的值将从从 U ( − k , k ) \mathcal{U}(-\sqrt{k}, \sqrt{k}) U(−k,k)取样,其中 k = groups C in ∗ ∏ i = 0 1 kernel-size [ i ] k=\frac{\text { groups }}{C_{\text {in }} * \prod_{i=0}^{1} \text { kernel-size }[i]} k=Cin ∗∏i=01 kernel-size [i] groups 。
举例:
>>> # 正方形的核和相同的步长
>>> m = nn.Conv2d(16, 33, 3, stride=2)
>>> # 非正方形的核和不一样的步长和填充
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> # non-square kernels and unequal stride and with padding and dilation
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)