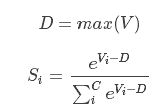Tensorflow (6) Attention 注意力机制
参考:
细讲 | Attention Is All You Need
关于注意力机制(《Attention is all you need》)
一步步解析Attention is All You Need! - 简书(代码)
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. The Illustrated Transformer【译】
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) – Jay Alammar – Visualizing machine learning one concept at a time. 一文读懂「Attention is All You Need」| 附代码实现
度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。(https://kexue.fm/archives/4765)

第一个思路是RNN层,递归进行,但是RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
![]()
第二个思路是CNN层,其实CNN的方案也是很自然的,窗口式遍历,比如尺寸为3的卷积,就是
![]()
在FaceBook的论文中,纯粹使用卷积也完成了Seq2Seq的学习,是卷积的一个精致且极致的使用案例,CNN方便并行,而且容易捕捉到一些全局的结构信息,
Google的大作提供了第三个思路:纯Attention!单靠注意力就可以!RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息,是通过层叠来增大感受野;Attention的思路最为粗暴,它一步到位获取了全局信息!它的解决方案是:

Attention顾名思义,是由人类观察环境的习惯规律总结出来的,人类在观察环境时,大脑往往只关注某几个特别重要的局部,获取需要的信息,构建出关于环境的某种描述,而Attention机制正是如此,去学习不同局部的重要性,再结合起来。
把Attention的定义给了出来:

其中Q∈R^n×dk,K∈R^m×dk,V∈R^m×dv。如果忽略激活函数softmax的话,那么事实上它就是三个n×dk,dk×m,m×dv的矩阵相乘,最后的结果就是一个n×dvn×dv的矩阵。于是我们可以认为:这是一个Attention层,将n×dkn×dk的序列Q编码成了一个新的n×dv的序列。
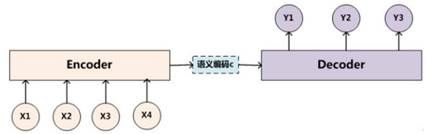
对于传统的机器翻译,我们可以使用sequence to sequence(encoder-decoder)模型来进行翻译,如下图所示。

输入序列{x1, x2, x3, x4},传入编码器(encoder)中进行编码,得到语义编码c,然后通过解码器(decoder)进行解码,得到输出序列{y1, y2, y3},输入与输出的个数可以不相等。对于句子
Source=
Target=
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
C=F(x1,x2,...xm)
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息y1,y2,..yi-1,来生成i时刻要生成的单词yi:
yi=g(C,y1,y2,y3,..yi-1).
这种方式会有一个问题:对于长句子的翻译会造成一定的困难,而attention机制的引入可以解决这个问题。(为什么引入注意力模型?因为没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入的句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多的细节信息,所以要引入注意力机制)如下图所示:

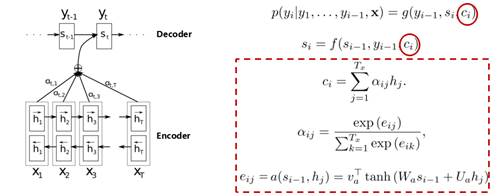
我们可以看到,decoder中有几个输出序列,对应的语义编码c则有相同的数量,即一个语义编码ci对应一个输出yi。而每个ci就是由attention机制得到,具体公式如下:
google翻译团队对attention模型的高度抽取概况。他们将其映射为一个query和一系列
下图揭示了Attention机制的本质:将Source中的构成元素想象成是由一系列的
理解Attention模型的关键就是,由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci.而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布。

上面提到的query与key之间计算相似度有许多方法,如dot、general、concat和MLP等方式,具体公式如下所示。而attention模型抽象为query、key和value之间的相似度计算,总共有3个阶段。第一阶段:query与keyi使用特定的相似度函数计算相似度,得到si;第二阶段:对si进行softmax()归一化得到ai;第三阶段,将ai与valuei对应相乘再求和,得到最终的attention value。其实对比传统的attention公式,我们可以看出,这两套公式还是很像的。

最近研究了一下transformer,看到The Illustrated Transformer这篇博客讲得非常清楚,从上至下,层层解剖。
1、transformer全貌

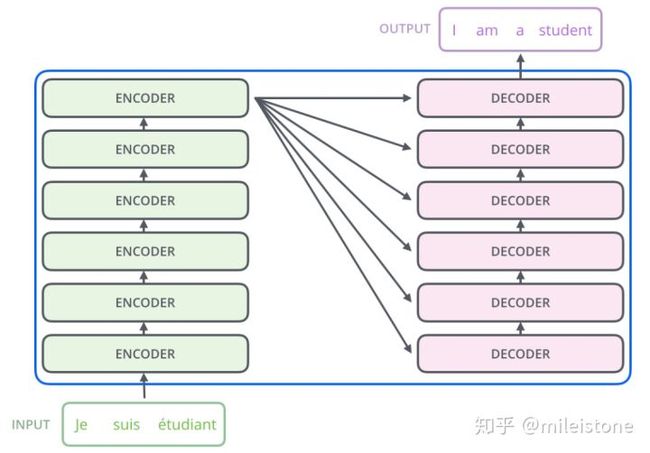
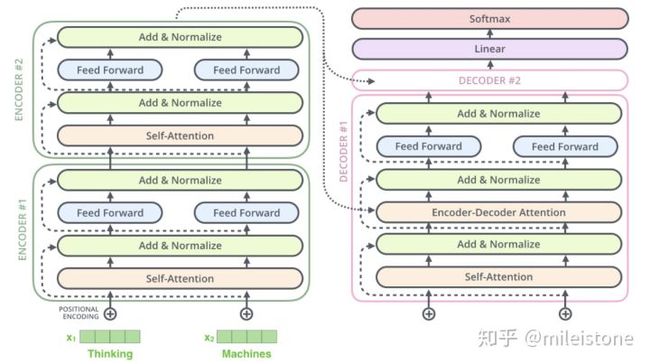
2、transformer是encoder decoder结构

3、encoder decoder内部结构
encoder部分有多个encoder单元,decoder部分也有多个decoder单元
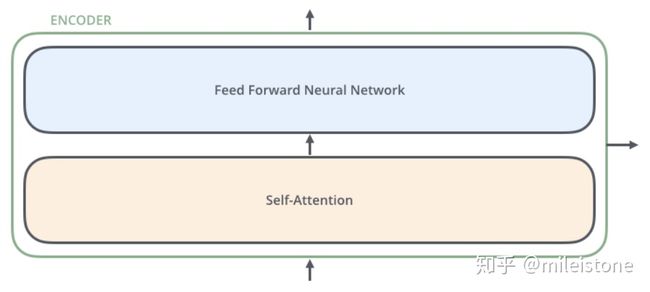
4、encoder单元内部
一个encoder单元由self attention和feed forward neural network两部分构成

5、decoder单元内部

6、self attention结构内部
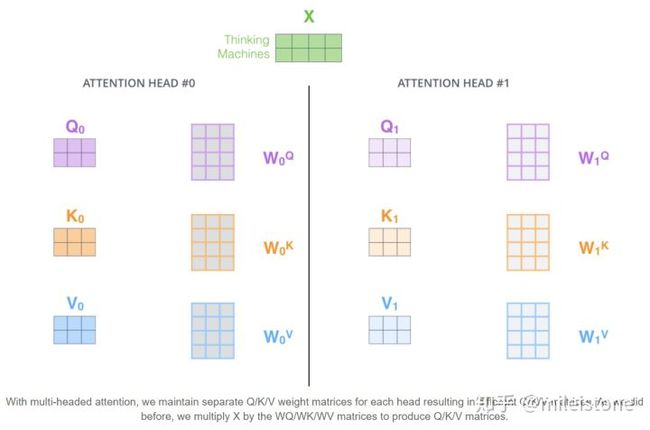
6.1、输入乘以权重WQ 得到Q ,乘以权重WK 得到K ,乘以权重WV 得到V (WQ, WK, WV)
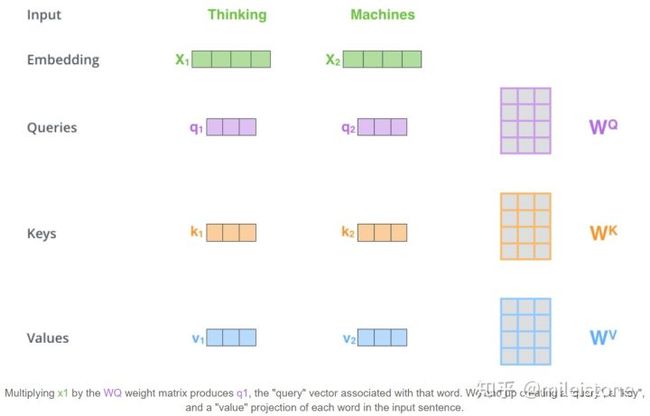
两个单词,Thinking, Machines. 通过嵌入变换会X1,X2两个向量[1 x 4]。分别与Wq,Wk,Wv三个矩阵[4x3]想做点乘得到,{q1,q2},{k1,k2},{v1,v2} 6个向量[1x3]。
6.2、通过前述计算得到的 q 、k 、v ,可以进一步计算得到self attention的输出 z

向量{q1,k1}做点乘得到得分(Score) 112, {q1,k2}做点乘得到得分96。
对该得分进行规范,除以8。这个在论文中的解释是为了使得梯度更稳定。之后对得分[14,12]做softmax得到比例 [0.88,0.12]。
用得分比例[0.88,0.12] 乘以[v1,v2]值(Values)得到一个加权后的值。将这些值加起来得到z1。这就是这一层的输出。仔细感受一下,用Q,K去计算一个thinking对与thinking, machine的权重,用权重乘以thinking,machine的V得到加权后的thinking,machine的V,最后求和得到针对各单词的输出Z。
6.3、self attention模块的矩阵计算形式

之前的例子是单个向量的运算例子。这张图展示的是矩阵运算的例子。输入是一个[2x4]的矩阵(单词嵌入),每个运算是[4x3]的矩阵,求得Q,K,V。
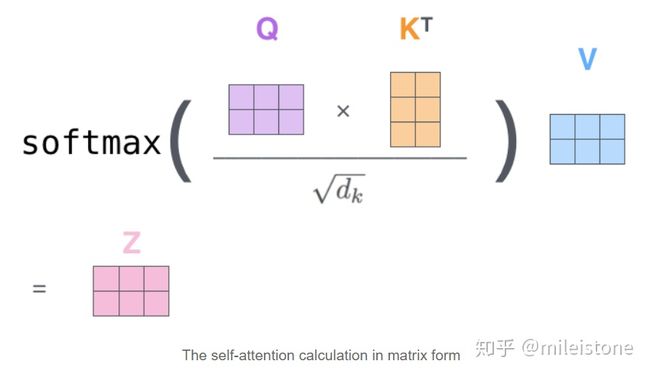
Q对K转制做点乘,除以dk的平方根。做一个softmax得到合为1的比例,对V做点乘得到输出Z。那么这个Z就是一个考虑过thinking周围单词(machine)的输出。
注意看这个公式,
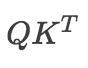
其实就会组成一个word2word的attention map!(加了softmax之后就是一个合为1的权重了)。
比如说你的输入是一句话 "i have a dream" 总共4个单词,这里就会形成一张4x4的注意力机制的图:

这样一来,每一个单词就对应每一个单词有一个权重
注意encoder里面是叫self-attention,decoder里面是叫masked self-attention。
这里的masked就是要在做language modelling(或者像翻译)的时候,不给模型看到未来的信息。

mask就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息。
详细来说,i作为第一个单词,只能有和i自己的attention。have作为第二个单词,有和i, have 两个attention。 a 作为第三个单词,有和i,have,a 前面三个单词的attention。到了最后一个单词dream的时候,才有对整个句子4个单词的attention。

做完softmax后就像这样,横轴合为1
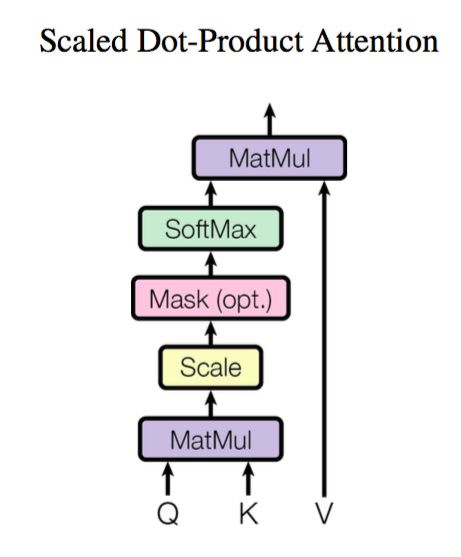
6.4、self attention的多head策略
Multi-Head Attention就是把Scaled Dot-Product Attention的过程做H次,然后把输出Z合起来。论文中,它的结构图如下:
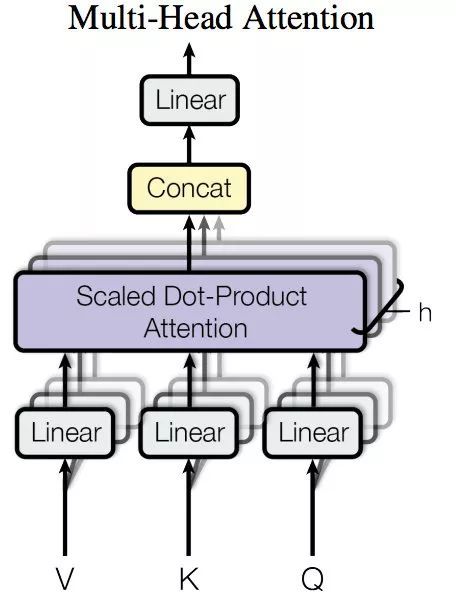
我们还是以上面的形式来解释:


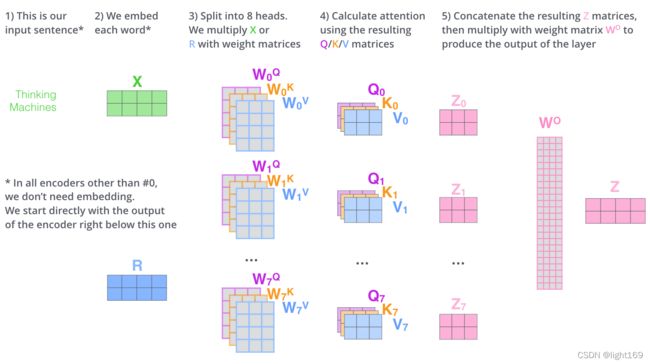
6.5、整个self attention的计算流程
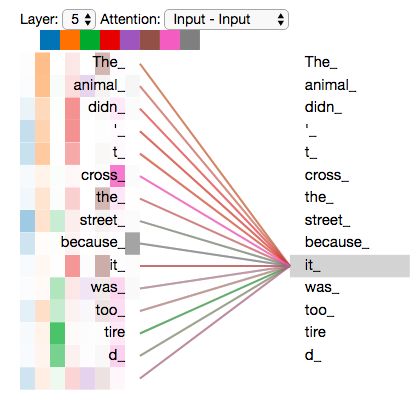
Now that we have touched upon attention heads, let’s revisit our example from before to see where the different attention heads are focusing as we encode the word “it” in our example sentence:

As we encode the word "it", one attention head is focusing most on "the animal", while another is focusing on "tired" -- in a sense, the model's representation of the word "it" bakes in some of the representation of both "animal" and "tired".
If we add all the attention heads to the picture, however, things can be harder to interpret:

7、decoder流程
8: The Final Linear and Softmax Layer
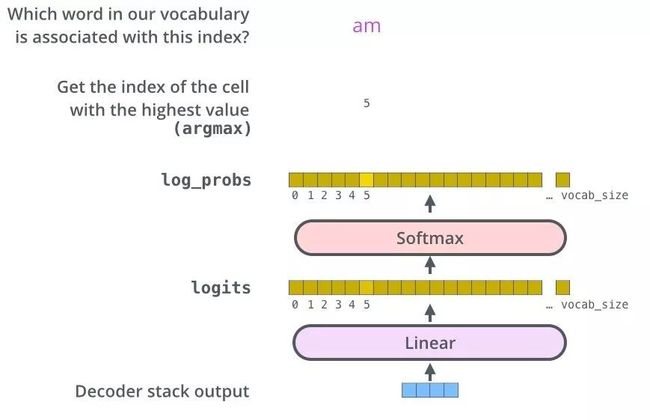
解码器最后输出浮点向量,如何将它转成词?这是最后的线性层和softmax层的主要工作。
线性层是个简单的全连接层,将解码器的最后输出映射到一个非常大的logits向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层将这些分数转换成概率值(都是正值,且加和为1),最高值对应的维上的词就是这一步的输出单词。
将Decoder的堆栈输出作为输入,从底部开始,最终进行word预测。
9、模型训练
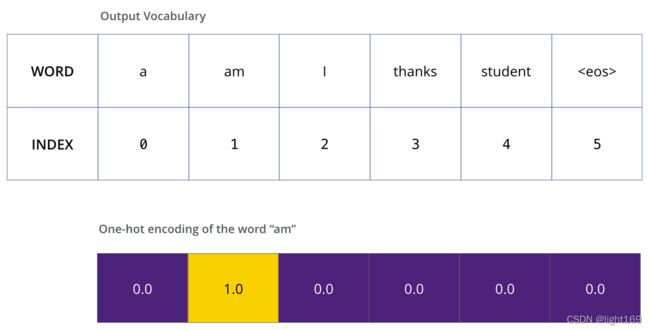
假设我们的字典有六个单词(“a”, “am”, “i”, “thanks”, “student”, and “

字典在训练之前已经建立好啦。
然后定义one-hot编码
假设翻译“merci” into “thanks”
没有训练之前的模型如下:

Since the model's parameters (weights) are all initialized randomly, the (untrained) model produces a probability distribution with arbitrary values for each cell/word. We can compare it with the actual output, then tweak all the model's weights using backpropagation to make the output closer to the desired output.
假设输入input: “je suis étudiant” 预计输出output: “i am a student”
在这个例子下,我们期望模型输出连续的概率分布满足如下条件:
- 1 每个概率分布都与词表同维度。
2 第一个概率分布对“i”具有最高的预测概率值。
3 第二个概率分布对“am”具有最高的预测概率值。
4 一直到第五个输出指向""标记。

上图是我们希望的模型输出
在足够大的训练集上训练足够时间之后,我们期望产生的概率分布如下所示:
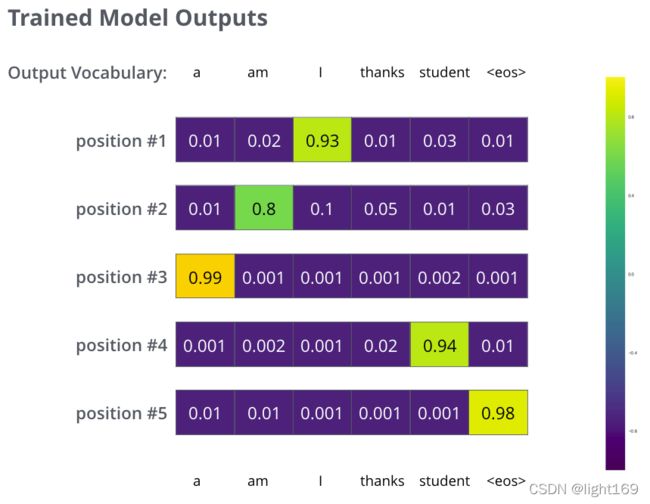
现在,因为模型每步只产生一组输出,假设模型选择最高概率,扔掉其他的部分,这是种产生预测结果的方法,叫做greedy 解码。另外一种方法是beam search,每一步仅保留最头部高概率的两个输出,根据这俩输出再预测下一步,再保留头部高概率的两个输出,重复直到预测结束。top_beams是超参可试验调整
什么是Softmax?Softmax在机器学习和深度学习中有着非常广泛的应用。尤其在处理多类(C>2)问题,分类器最后的输出单元需要Softmax函数进行数值处理。
关于Softmax函数的定义如下:
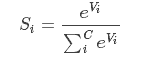
其中,Vi 是分类器前级输出单元的输出。i 表示类别索引,总的类别个数为 C。Si 表示的是当前元素的指数与所有元素指数和的比值。Softmax 将多分类的输出数值转化为相对概率,更容易理解和比较。我们来看下面这个例子。
一个多分类问题,C = 4。线性分类器模型最后输出层包含了四个输出值,分别是:
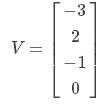
经过Softmax处理后,数值转化为相对概率:

很明显,Softmax 的输出表征了不同类别之间的相对概率。我们可以清晰地看出,S1 = 0.8390,对应的概率最大,则更清晰地可以判断预测为第1类的可能性更大。Softmax 将连续数值转化成相对概率,更有利于我们理解。
实际应用中,使用 Softmax 需要注意数值溢出的问题。因为有指数运算,如果 V 数值很大,经过指数运算后的数值往往可能有溢出的可能。所以,需要对 V 进行一些数值处理:即 V 中的每个元素减去 V 中的最大值。