ssd\融合代码\faster rcn\yolov5错误和笔记总结
融合代码bug改进:
dataset必须得改进对。
ssd:
1、问题: for obj in data["object"]: KeyError: 'object'
解决:数据集中的图片object为空,需删除
调试:print(data[“filename”])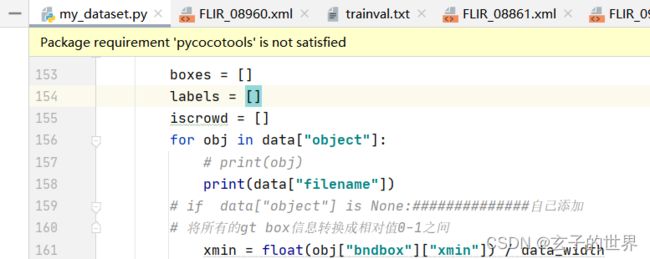

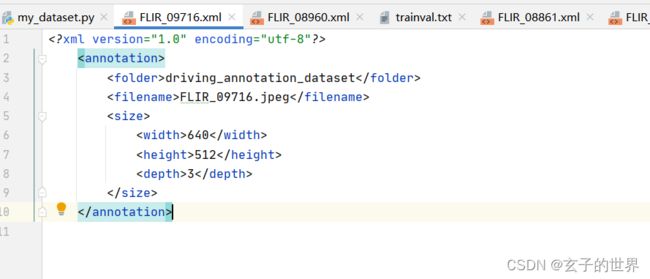
查看9716图片 、空的,替换或删除、解决。**注意:**是看9716不是9715
2、File "src/lxml/etree.pyx", line 3252, in lxml.etree.fromstring File "src/lxml/parser.pxi", line 1908, in lxml.etree._parseMemoryDocument ValueError: Unicode strings with encoding declaration are not supported. Please use bytes input or XML fragments without declaration. 添加encode(utf-8)![]()
3、灰度图像转为三通道
# -*- codeing = uft-8 -*-
# @Time : 2022/5/7 11:15
# @Author : 袁子玄
# @File : gray_GRB.py
# @Software: PyCharm
from PIL import Image
import os
import numpy as np
import cv2
from torchvision import transforms
path=r'D:\LenovoSoftstore\otherfile\deep-learning-for-image-processing-master\pytorch_object_detection\ssd\my_dataset\flir\VOCdevkit\VOC2012\JPEGImages'
path1 = r'D:\LenovoSoftstore\otherfile\deep-learning-for-image-processing-master\pytorch_object_detection\ssd\my_dataset\flir\VOCdevkit\VOC2012\JPEGImages1'
files=os.listdir(path)
for file in files:
Inimgpath = path+'\\'+file
src = cv2.imread(Inimgpath, 0)#注意,这里的 Inimgpath 要写在上面,避免不必要的bug
src_RGB = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
outimagepath = path1 + '\\' + file
cv2.imwrite(outimagepath, src_RGB)
# imgpath = path+'\\'+'FLIR_00001.jpeg'
# src=cv2.imread(imgpath,0)
#
# src_RGB = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
#
# cv2.imshow("input", src)
# cv2.imshow("output", src_RGB)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# # print(I.shape)
# outimagepath = path1+'\\'+'FLIR_00001.jpeg'
# cv2.imwrite(outimagepath,src_RGB)
# print(I.shape)
4、检查数据集标注文件有没有问题(目标为空或者其它问题)
# -*- codeing = uft-8 -*-
# @Time : 2022/5/7 14:58
# @Author : 袁子玄
# @File : noobgectpicture.py
# @Software: PyCharm
import argparse
import sys
import cv2
import os
import os.path as osp
import numpy as np
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--root',default=r'D:\LenovoSoftstore\otherfile\deep-learning-for-image-processing-master\pytorch_object_detection\ssd\my_dataset\flir\VOCdevkit\VOC2012', help='Dataset root directory path')
args = parser.parse_args()
CLASSES = ('persion', 'bicycle', 'car')
annopath = osp.join('%s', 'Annotations', '%s.{}'.format("xml"))
imgpath = osp.join('%s', 'JPEGImages', '%s.{}'.format("jpeg"))
def vocChecker(image_id, width, height, keep_difficult = False):
target = ET.parse(annopath % image_id).getroot()
res = []
for obj in target.iter('object'):
difficult = int(obj.find('difficult').text) == 1
if not keep_difficult and difficult:
continue
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# scale height or width
cur_pt = float(cur_pt) / width if i % 2 == 0 else float(cur_pt) / height
bndbox.append(cur_pt)
print(name)
label_idx = dict(zip(CLASSES, range(len(CLASSES))))[name]
bndbox.append(label_idx)
res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
print(res)
try :
print(np.array(res)[:,4])
print(np.array(res)[:,:4])
except IndexError:
print("\nINDEX ERROR HERE !\n")
exit(0)
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
if __name__ == '__main__':
i = 0
for name in sorted(os.listdir(osp.join(args.root,'Annotations'))):
#?as we have only one annotations file per image
i += 1
# img = cv2.imread(imgpath % (args.root,name.split('.')[0]))
img = cv2.imread(imgpath % (args.root, name.split('.')[0]))
height, width, channels = img.shape
print("path : {}".format(annopath % (args.root,name.split('.')[0])))
res = vocChecker((args.root, name.split('.')[0]), height, width)
print("Total of annotations : {}".format(i))
5、YOLO转xml
# -*- codeing = uft-8 -*-
# @Time : 2022/7/3 8:53
# @Author : 袁子玄
# @File : YOLO_XML.py
# @Software: PyCharm
# -*- codeing = uft-8 -*-
# @Time : 2022/5/5 15:22
# @Author : 袁子玄
# @File : YOLO_xml.py
# @Software: PyCharm
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {'4': "orange", # 创建字典用来对类型进行转换
'5': "damaged_orange", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name.split('.')[0]+ ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name.split('.')[0] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight+1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int((float(oneline[3])*Pwidth*0.5)+int(((float(oneline[1])) * Pwidth) - (float(oneline[3])) * 0.5 * Pwidth))
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int((float(oneline[4])*Pheight*0.5)+int(((float(oneline[2])) * Pheight+1) - (float(oneline[4])) * 0.5 * Pheight))
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name.split('.')[0] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = r"D:/LenovoSoftstore/otherfile/Firl/train_orange/images/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = r"D:/LenovoSoftstore/otherfile/Firl/train_orange/labels/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = r"D:/LenovoSoftstore/otherfile/Firl/train_orange/xml/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
6、VOC数据集制作列表
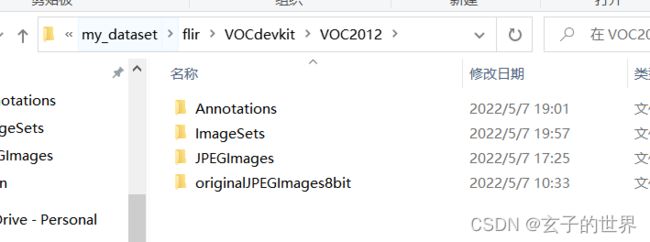
7、train中不是空的标签下载的数据集中没有写的
![]()

8、
json文件没用用对,要把里面的类别写对
9、
![]()
解决办法,在tmp前面加/
10、
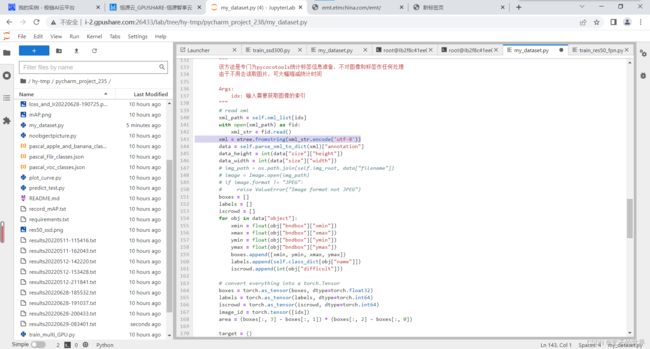
File "src/lxml/etree.pyx", line 3252, in lxml.etree.fromstring
File "src/lxml/parser.pxi", line 1908, in lxml.etree._parseMemoryDocument
ValueError: Unicode strings with encoding declaration are not supported. Please use bytes input or XML fragments without declaration
具体语句为将xml = etree.fromstring(xml_str)改为xml = etree.fromstring(xml_str.encode(‘utf-8’))
11、【报错】cannot write mode RGBA as JPEG
图片里面有些格式不对,利用下面代码找出并转换
# -*- codeing = uft-8 -*-
# @Time : 2022/6/29 15:52
# @Author : 袁子玄
# @File : RGB format.py
# @Software: PyCharm
import os
from PIL import Image
from tqdm import tqdm
import numpy as np
img_path = r'C:\Users\玄子\Desktop\apple_banba\坏的橘子' # 填入图片所在文件夹的路径
img_Topath = r'C:\Users\玄子\Desktop\apple_banba\转换' # 填入图片转换后的文件夹路径
for item in tqdm(os.listdir(img_path)):
arr = item.strip().split('*')
img_name = arr[0]
image_path = os.path.join(img_path, img_name)
img = Image.open(image_path)
if (img.mode != 'RGB'):
img = img.convert("RGB")
img.save(img_Topath + '/' + img_name)
12、修改图片名字的代码
# -*- codeing = uft-8 -*-
# @Time : 2022/6/24 21:21
# @Author : 袁子玄
# @File : Modify_picture_name.py
# @Software: PyCharm
import os
# apple (364)
# damaged_apple (270)
1
path = r"C:\Users\玄子\Desktop\apple_banba\坏的橘子"
prefix = r"damage_orange"
suffix = ".jpg"
# 获取该目录下所有文件,存入列表中
fileList = os.listdir(path)
m = int(input('请输入开始数:')) # python中input函数默认返回一个字符串,需强制转化为整数
n = m
for inner_file in fileList:
# 获取旧文件名(就是路径+文件名)
old_name = path + os.sep + inner_file # os.sep添加系统分隔符
if os.path.isdir(old_name): # 如果是目录则跳过
continue
# 设置新文件名
new_name = path + os.sep + prefix + str(n) + suffix
os.rename(old_name, new_name) # 用os模块中的rename方法对文件改名
n += 1
print("共修改了", n - m, "个文件。")
13、增加图片代码
# -*- codeing = uft-8 -*-
# @Time : 2022/6/26 8:54
# @Author : 袁子玄
# @File : Picture amplification.py
# @Software: PyCharm
#import utils.autoanchor as autoAC
# 对数据集重新计算 anchors
#new_anchors = autoAC.kmean_anchors('./mark/data.yaml', 9, 640, 5.0, 1000, True)
#print(new_anchors)
from PIL import ImageEnhance
import os
import numpy as np
from PIL import Image
def brightnessEnhancement(root_path,img_name):#亮度增强
image = Image.open(os.path.join(root_path, img_name))
enh_bri = ImageEnhance.Brightness(image)
# brightness = 1.1+0.4*np.random.random()#取值范围1.1-1.5
brightness = 1.5
image_brightened = enh_bri.enhance(brightness)
return image_brightened
def contrastEnhancement(root_path, img_name): # 对比度增强
image = Image.open(os.path.join(root_path, img_name))
enh_con = ImageEnhance.Contrast(image)
# contrast = 1.1+0.4*np.random.random()#取值范围1.1-1.5
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
return image_contrasted
def rotation(root_path, img_name):
img = Image.open(os.path.join(root_path, img_name))
random_angle = np.random.randint(-2, 2)*90 #随机产生一个数然后乘以90度后旋转
if random_angle==0:
rotation_img = img.rotate(-90) #旋转角度
else:
rotation_img = img.rotate( random_angle) # 旋转角度
# rotation_img.save(os.path.join(root_path,img_name.split('.')[0] + '_rotation.jpg'))
return rotation_img
def flip(root_path,img_name): #翻转图像
img = Image.open(os.path.join(root_path, img_name))
filp_img = img.transpose(Image.FLIP_LEFT_RIGHT)
# filp_img.save(os.path.join(root_path,img_name.split('.')[0] + '_flip.jpg'))
return filp_img
def createImage(imageDir,saveDir):
i=0
for name in os.listdir(imageDir):
i=i+1
saveName="cesun"+str(i)+".jpg" #对比度增强
saveImage=contrastEnhancement(imageDir,name)
saveImage.save(os.path.join(saveDir,saveName))
saveName1 = "flip" + str(i) + ".jpg" #翻转图像
saveImage1 = flip(imageDir,name)
saveImage1.save(os.path.join(saveDir, saveName1))
saveName2 = "brightnessE" + str(i) + ".jpg" #亮度增强
saveImage2 = brightnessEnhancement(imageDir, name)
saveImage2.save(os.path.join(saveDir, saveName2))
saveName3 = "rotate" + str(i) + ".jpg" #旋转角度
saveImage = rotation(imageDir, name)
saveImage.save(os.path.join(saveDir, saveName3))
if __name__=='__main__':
imageDir = r"C:\Users\玄子\Desktop\apple_banba\坏的橘子" # 要改变的图片的路径文件夹
saveDir = r"C:\Users\玄子\Desktop\apple_banba\原始和增强后腐烂的橘子" # 数据增强生成图片的路径文件夹
createImage(imageDir, saveDir)
#添加椒盐噪声和高斯噪声
from PIL import Image
from skimage import util, img_as_float, io # 导入所需要的 skimage 库
import os
old_path = "D:/标准尺寸处理/竖裂缝/images" # 原始文件路径
save_path = "D:/标准尺寸处理/竖裂缝/bianhuan" # 需要存储的文件路径
file_list = os.walk(old_path)
for root, dirs, files in file_list:
for file in files:
pic_path = os.path.join(root, file) # 每一个图片的绝对路径
# 读取图像
img_org = Image.open(pic_path)
# 转换为 skimage 可操作的格式
img = img_as_float(img_org)
image_gaussian = util.random_noise(img, mode="gaussian") # 加高斯噪声
#image_sp = util.random_noise(img, mode="s&p") # 加椒盐噪声
# 存储文件到新的路径中,并修改文件名
io.imsave(os.path.join(save_path, file[:-4] + "-guassian.jpg"), image_gaussian)
#io.imsave(os.path.join(save_path, file[:-4] + "-sp.jpg"), image_sp)
13、把文件夹里图片的名字保存在.txt里面
# -*- codeing = uft-8 -*-
# @Time : 2022/5/5 19:16
# @Author : 袁子玄
# @File : list_txt.py
# @Software: PyCharm
import os
# readInfo函数,根据文件夹路径读取文件夹下所有文件名
def readInfo():
# filePath = 'D:\\LenovoSoftstore\\otherfile\\Firl\\train\\noinversionimages1\\'
# filePath = 'D:\\LenovoSoftstore\\otherfile\\Firl\\train\\labels2_fix_after\\'
filePath = 'C:\\Users\\玄子\\Desktop\\apple_banba\\apple_detection_dataset\\apple_banana_dataset\\validation_apple_dataset\\image\\'
name = os.listdir(filePath) # os.listdir方法返回一个列表对象
return name
# 程序入口
if __name__ == "__main__":
fileList = readInfo() # 读取文件夹下所有的文件名,返回一个列表
print(fileList)
# file = open(r'D:\LenovoSoftstore\otherfile\Firl\train\ImageSets\Main\val.txt', 'w') # 创建文件,权限为写入
file = open(r'C:\Users\玄子\Desktop\apple_banba\apple_detection_dataset\apple_banana_dataset\validation_apple_dataset\val.txt', 'w') # 创建文件,权限为写入
for i in fileList:
imageDir = i.split('.')[0]
# annotationDir = 'Annotations/' + i
# rowInfo = imageDir + ' ' + annotationDir + '\n'
rowInfo = imageDir+'\n'
print(rowInfo)
file.write(rowInfo)
14、xml转txt
# -*- codeing = uft-8 -*-
# @Time : 2022/6/24 15:16
# @Author : 袁子玄
# @File : xml_txt.py
# @Software: PyCharm
import os
import xml.etree.ElementTree as ET
classes = ["apple", "damaged_apple"]
# 将x1, y1, x2, y2转换成yolov5所需要的x, y, w, h格式
def xyxy2xywh(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[2]) / 2 * dw
y = (box[1] + box[3]) / 2 * dh
w = (box[2] - box[0]) * dw
h = (box[3] - box[1]) * dh
return (x, y, w, h) # 返回的都是标准化后的值
def voc2yolo(path):
# 可以打印看看该路径是否正确
print(len(os.listdir(path)))
# 遍历每一个xml文件
for file in os.listdir(path):
# xml文件的完整路径, 注意:因为是路径所以要确保准确,我是直接使用了字符串拼接, 为了保险可以用os.path.join(path, file)
label_file = path + file
# 最终要改成的txt格式文件,这里我是放在voc2007/labels/下面
# 注意: labels文件夹必须存在,没有就先创建,不然会报错
out_file = open(path.replace('Annotations', 'labels') + file.replace('xml', 'txt'), 'w')
# print(label_file)
# 开始解析xml文件
tree = ET.parse(label_file)
root = tree.getroot()
size = root.find('size') # 图片的shape值
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
# 将名称转换为id下标
cls_id = classes.index(cls)
# 获取整个bounding box框
bndbox = obj.find('bndbox')
# xml给出的是x1, y1, x2, y2
box = [float(bndbox.find('xmin').text), float(bndbox.find('ymin').text), float(bndbox.find('xmax').text),
float(bndbox.find('ymax').text)]
# 将x1, y1, x2, y2转换成yolov5所需要的x_center, y_center, w, h格式
bbox = xyxy2xywh((w, h), box)
# 写入目标文件中,格式为 id x y w h
out_file.write(str(cls_id) + " " + " ".join(str(x) for x in bbox) + '\n')
if __name__ == '__main__':
# 这里要改成自己数据集路径的格式
# path = 'E:/VOC2007/Annotations/'
path = 'F:/apple_dataset/validation/Annotations/'
voc2yolo(path)
15、txt转xml
# -*- codeing = uft-8 -*-
# @Time : 2022/5/5 15:22
# @Author : 袁子玄
# @File : YOLO_xml.py
# @Software: PyCharm
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {'0': "apple", # 创建字典用来对类型进行转换
'1': "damaged_apple", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
'2':'banana',
'3':'damaged_banana'
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
# img = cv2.imread(picPath + name[0:10]+ ".jpg")
img = cv2.imread(picPath + name.split('.')[0] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
# filenamecontent = xmlBuilder.createTextNode(name[0:10] + ".jpg")
filenamecontent = xmlBuilder.createTextNode(name.split('.')[0] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight+1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int((float(oneline[3])*Pwidth)+int(((float(oneline[1])) * Pwidth) - (float(oneline[3])) * 0.5 * Pwidth))
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int((float(oneline[4])*Pheight)+int(((float(oneline[2])) * Pheight+1) - (float(oneline[4])) * 0.5 * Pheight))
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
# f = open(xmlPath + name[0:10] + ".xml", 'w')
f = open(xmlPath + name.split('.')[0] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
# picPath = "D:/LenovoSoftstore/otherfile/Firl/val/images/" # 图片所在文件夹路径,后面的/一定要带上
# txtPath = "D:/LenovoSoftstore/otherfile/Firl/val/labels/" # txt所在文件夹路径,后面的/一定要带上
# xmlPath = "D:/LenovoSoftstore/otherfile/Firl/val/annotations/" # xml文件保存路径,后面的/一定要带上
# makexml(picPath, txtPath, xmlPath)
picPath = r"D:/LenovoSoftstore/otherfile/deep-learning-for-image-processing-master/pytorch_object_detection/ssd/my_dataset/flir/VOCdevkit/VOC2012/JPEGImages/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = r"D:/LenovoSoftstore/otherfile/deep-learning-for-image-processing-master/pytorch_object_detection/ssd/my_dataset/flir/VOCdevkit/VOC2012/label/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = r"D:/LenovoSoftstore/otherfile/deep-learning-for-image-processing-master/pytorch_object_detection/ssd/my_dataset/flir/VOCdevkit/VOC2012/xml_train/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
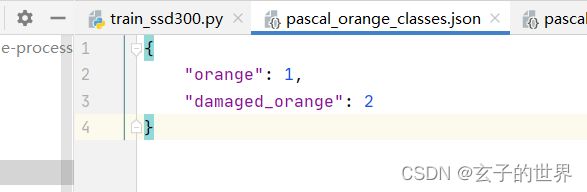
16,ssd图片问题

解决:
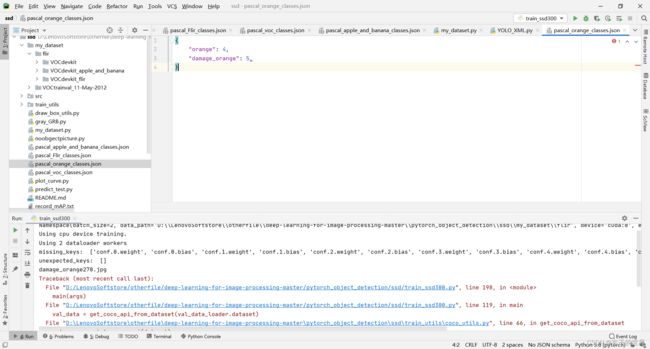
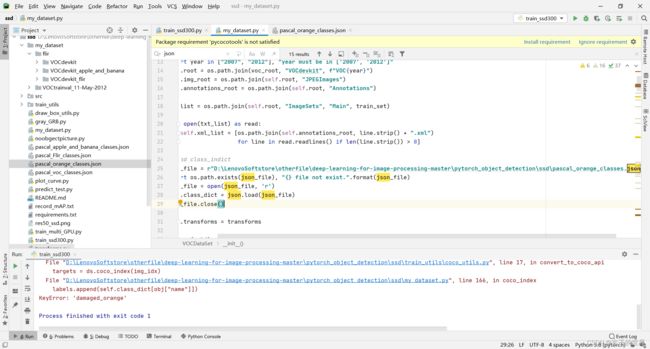
下面的damaged_orange 一定要加d,因为我自己标注文件里面是damaged_banana,只是标签文件名是damage_banana

以上有的代码时自己写的,有的是参考别人的代码改了,有的是抄的,如有不当之处,请联系我删除
17、

transforms.Normalize()
18、视频转图片
# -*- codeing = uft-8 -*-
# @Time : 2022/8/10 16:05
# @Author : 袁子玄
# @File : 视频转图片.py
# @Software: PyCharm
#coding=utf-8
# import os
# import cv2
#
#
# videos_src_path = r'D:/LenovoSoftstore/otherfile/video/'
# videos_save_path = r'D:/LenovoSoftstore/otherfile/picture/'
#
# videos = os.listdir(videos_src_path)
# #videos = filter(lambda x: x.endswith('MP4'), videos)
#
# for each_video in videos:
# print('Video Name :', each_video)
# # get the name of each video, and make the directory to save frames
# each_video_name, _ = each_video.split('.')
# os.mkdir(videos_save_path + '/' + each_video_name)
#
# each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/'
#
# # get the full path of each video, which will open the video tp extract frames
# each_video_full_path = os.path.join(videos_src_path, each_video)
#
# cap = cv2.VideoCapture(each_video_full_path)
# frame_count = 1
# success = True
# while (success):
# success, frame = cap.read()
# if success == True:
# cv2.imwrite(each_video_save_full_path + "%06d.jpg" % frame_count, frame)
#
# frame_count = frame_count + 1
# print('Final frame:', frame_count)
# coding=utf-8
import cv2
import os
import threading
from threading import Lock, Thread
'''
NotADirectoryError: [WinError 267] 目录名称无效。
例如:
os.listdir(path)
原因:传进去的path是文件路径,就会报错。
检查一下,确保path是文件夹路径就行
'''
video_path = r"D:/LenovoSoftstore/otherfile/picture/2022-11-07-8-20%.avi/"
pic_path = r"D:/LenovoSoftstore/otherfile/picture/2022-11-07-8-20%.avi/picture/"
filelist = os.listdir(video_path)
def video2pic(filename):
# print(filename)
cnt = 0
dnt = 0
if os.path.exists(pic_path + str(filename)):
pass
else:
os.mkdir(pic_path + str(filename))
cap = cv2.VideoCapture(video_path + str(filename)) # 读入视频
while True:
# get a frame
ret, image = cap.read()
if image is None:
break
# show a frame
w = image.shape[1]
h = image.shape[0]
if (cnt % 20) == 0:
cv2.imencode('.jpg', image)[1].tofile(pic_path + str(filename) + '/' + str(dnt) + '.jpg')
print(pic_path + str(filename) + '/' + str(dnt) + '.jpg')
dnt = dnt + 1
cnt = cnt + 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
if __name__ == '__main__':
for filename in filelist:
threading.Thread(target=video2pic, args=(filename,)).start()
19、RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
Yolo训练过程中,出现了RuntimeError: Unable to find a valid cuDNN algorithm to run convolution报错信息,此时将batchsize设置小些即可避免该报错信息产生。
20、删除不是JPEG的图片
# -*- codeing = uft-8 -*-
# @Time : 2022/7/3 23:13
# @Author : 袁子玄
# @File : delete_not_JPEG.py
# @Software: PyCharm
# -*- codeing = uft-8 -*-
# @Time : 2022/6/29 15:52
# @Author : 袁子玄
# @File : RGB format.py
# @Software: PyCharm
import os
from PIL import Image
from tqdm import tqdm
import numpy as np
img_path = r'D:\LenovoSoftstore\otherfile\deep-learning-for-image-processing-master\pytorch_object_detection\ssd\my_dataset\flir\VOCdevkit\VOC2012\JPEGImages' # 填入图片所在文件夹的路径
img_Topath = r'D:\LenovoSoftstore\otherfile\deep-learning-for-image-processing-master\pytorch_object_detection\ssd\my_dataset\flir\VOCdevkit\VOC2012\转换' # 填入图片转换后的文件夹路径
for item in tqdm(os.listdir(img_path)):
arr = item.strip().split('*')
img_name = arr[0]
image_path = os.path.join(img_path, img_name)
img = Image.open(image_path)
if (img.mode != 'RGB'):
img = img.convert("RGB")
img.save(img_Topath + '/' + img_name)
21、Faster R-CNN
Pytorch: "KeyError: Caught KeyError in DataLoader worker process 0."
解决:设置为1,然num_works为1
![]()