【项目实战一】基于人工神经网络ANN的车牌识别
前言:车牌识别技术的发展与推广有利于加强对道路交通的管理,与人民出行安全息息相关。该项目实战非常适合各位读者作为本科毕业设计、课程设计或者其它进行学习,相信对大家会有很大帮助,如果需要完整源码,大家可以在评论区留言,小编会在第一时间提供给你们。最后,非常欢迎大家对本文内容批评指正!
目录
1、车牌识别系统的设计方案
2、车牌识别系统的代码实现
2.1 图像预处理
2.2 车牌分割
2.3 字符分割
2.4 字符识别
3、车牌识别系统的功能展示
1、车牌识别系统的设计方案
本文的车牌识别系统是基于Matlab编程语言具体实现的,主要包括图像预处理,车牌分割,字符分割,字符识别4个模块,其中字符识别是基于ANN完成的,所以还需要先训练好ANN人工神经网络,具体流程如图1所示。另外,为了方便更好得将系统功能展示出来,小编特意设计了一个人机交互界面,如图2所示,使项目看起来更加完整。

图1
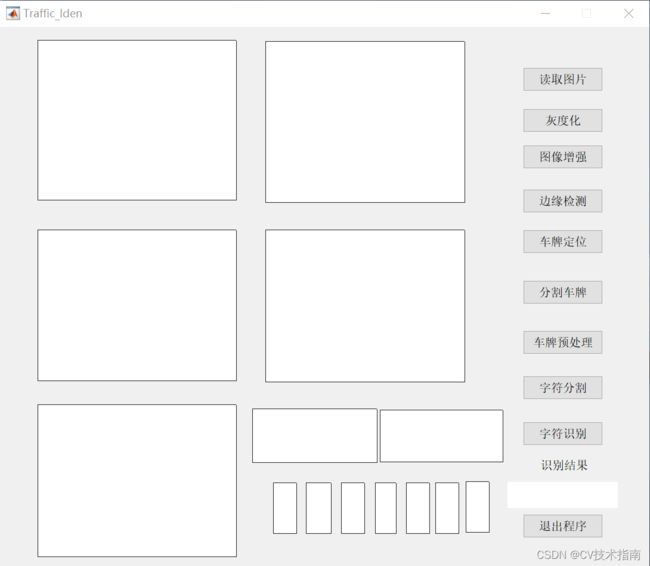
图2
2、车牌识别系统的代码实现
2.1 图像预处理
在图像识别任务中,图像前期的预处理工作十分重要,它有可能会直接影响图像的识别效果,所以必须根据各自的项目特点做出正确的图像预处理。在本文的车牌识别项目前期工作中主要对输入图像进行了灰度化处理和直方图均衡化两项操作。因为直方图均衡化处理之后,原来占比较少的像素灰度会被分配到别的灰度去,像素相对集中,提高了图像的局部对比度和清晰度,可以有效增强图像。
现在用一个例子来详细介绍一下直方图均衡化的原理,假设原图像像素值分布为:
| 255 | 128 | 200 | 50 |
| 50 | 200 | 255 | 50 |
| 255 | 200 | 128 | 128 |
| 200 | 200 | 255 | 50 |
均衡化操作过程:
| 灰度值 | 像素个数 | 概率 | 累积概率 | 根据函数映射后的灰度值 | 取整 |
| 50 | 4 | 0.25 | 0.25 | 0.25×(255-0)=63.75 | 64 |
| 128 | 3 | 0.1875 | 0.4375 | 0.4375×(255-0)=111.56 | 112 |
| 200 | 5 | 0.3125 | 0.75 | 0.75×(255-0)=191.25 | 191 |
| 255 | 4 | 0.25 | 1 | 1×(255-0)=255 | 255 |
均衡化后的像素值分布:
| 255 | 112 | 191 | 64 |
| 64 | 191 | 255 | 64 |
| 255 | 191 | 112 | 112 |
| 191 | 191 | 255 | 64 |
项目中图像预处理的代码如下:
function pushbutton8_Callback(hObject, eventdata, handles)
%图像增强
image = handles.I;
gray = rgb2gray(image);
new_gray = histeq(gray); % 直方图均衡 ,图像增强
axes(handles.axes3);
imshow(new_gray);2.2 车牌分割
一幅图像中往往由很多元素组成,我们必须根据元素的特点,比如形状,颜色等,筛选出感兴趣域。由于小编做的是车牌识别,所以必须先从图像中确定车牌的所在位置,并且将车牌区域从图像中分割出来。因为车牌的背景颜色是蓝色,如图3所示,本项目就是根据颜色这一特点先确定车牌所在区域的大概位置,再通过Canny边缘检测和形态学将车牌的准确位置从图像中分割出来,如图4所示。

图3

图4
这部分代码实现如下:
function pushbutton9_Callback(hObject, eventdata, handles)
%边缘检测
image = handles.I;
gray = rgb2gray(image);
new_gray = histeq(gray);
if size(new_gray,1)>1000
new_gray_1 = imresize(new_gray,0.1);
else
new_gray_1 =new_gray;
end
bw = edge(new_gray_1,'canny');
axes(handles.axes4);
imshow(bw);
% --- Executes on button press in pushbutton2.
function pushbutton2_Callback(hObject, eventdata, handles)
%% 车牌定位
Color = 2; % 颜色标记 蓝
handles.Color = Color;
Image = handles.I;
DI = Image(:,:,3);
GI = (Image(:,:,1)<100 & Image(:,:,2)<150 & Image(:,:,3)>120 ...
& abs(double(Image(:,:,2))-double(Image(:,:,3)))>30);
axes(handles.axes5);
imshow(GI);
handles.GI = GI;
guidata(hObject, handles);
% --- Executes on button press in pushbutton3.
function pushbutton3_Callback(hObject, eventdata, handles)
%% 分割车牌
d = handles.GI;
se = ones(40); % 腐蚀膨胀模版
d = imdilate(d,se);% 再做膨胀运算
d = imerode(d,se); % 先做腐蚀运算
% 先膨胀后腐蚀的过程称为开运算。用来填充物体内细小空洞、连接邻近物体、平滑其边界的同时并不明显改变其面积。
d = bwareaopen(d,100); % 移除小对象 小区域肯定是噪声
STATS = regionprops(d);
area = [];
for i = 1:size(STATS,1)
area = [area;STATS(i).Area];
end
[value,index] = max(area);
Bound = round(STATS(index).BoundingBox);
xmin = Bound(2);
xmax = Bound(2)+Bound(4);
ymin = Bound(1);
ymax = Bound(1)+Bound(3);
II = handles.I(xmin:xmax,ymin:ymax,:);
axes(handles.axes6);
imshow(II);
handles.Divice = II;
guidata(hObject, handles);2.3 字符分割
将车牌所在区域从图像中准确分割出来后,我们就要开始车牌识别的准备工作了,就是将车牌中的所有字符单独分割开,从而方便后续的字符识别工作,这部分代码如下:
function pushbutton11_Callback(hObject, eventdata, handles)
%% 字符分割
I_VER_JZ_S = handles.chepaiyu;
thresh = handles.chepaiyuT;
I_1=rgb2gray(I_VER_JZ_S);
K=im2bw(I_1,thresh);
[kuan,chang]=size(K);
% STATS = regionprops(K);
%
%
% for i = 1:size(STATS,1)
% STATS(i).Area>
% rectangle('Position',STATS(4).BoundingBox,'EdgeColor','r');
%
[x,y]=find(K==1)
a1=length(x);
[x,y]=find(K==0)
b1=length(y);
if a1>b1
K1=~K;
else
K1=K;
end
[a b] = size(K1);
sumK = sum(K1);
%寻找阈值
T=1;
myb = find(sumK>=T); %所在的列为myb
myf = zeros(1,length(myb)); %大于阈值的列的数目
for ii = 2:length(myb)
if myb(ii)-myb(ii-1)<=2
myb(ii-1) = 0; %myb不为0的点位跳变的前边缘_index
else
myf(ii) = myb(ii); %myf不为0的点对应跳变的后边缘_index
end
end
myd = find(myb~=0); %找到跳变的前边缘
MYE = myb(myd); %对应列号
myh = find(myf~=0); %找到跳变的后边缘
myi = myf(myh);
MYB = [1 myi];
for ii = 1:length(MYE)
part=sumK(1,MYB(ii):MYE(ii))
sumP=sum(part,2)
end
% 面积最大的前7个
for ii = 1:length(MYE)
part1=sumK(1,MYB(ii):MYE(ii))
sumP1=sum(part1,2)
ss(ii) = sumP1;
end
[value index] = sort(ss,'descend');
if length(MYE)>7
nnnn = index(1:7);
else
nnnn = index;
end
count = 1;
[value index] = sort(nnnn);
for num = 1:length(nnnn)
% if sumP1(1)> (chang*kuan)*0.0126
switch count
case 1
axes(handles.axes8);
case 2
axes(handles.axes9);
case 3
axes(handles.axes10);
case 4
axes(handles.axes11);
case 5
axes(handles.axes12);
case 6
axes(handles.axes13);
otherwise
axes(handles.axes14);
end
ii = value(num);
imshow(K1(:,MYB(ii):MYE(ii)));
images_test1 = imresize(K1(:,MYB(ii):MYE(ii)),[24 12]);
imwrite(images_test1,strcat(num2str(ii),'.jpg'));
images_test(:,count) = double(reshape(images_test1,288,1));
count = count+1;
end
handles.testnum = images_test;
guidata(hObject, handles);
2.4 字符识别
字符识别是车牌识别项目的最后一步,也是最重要的一步,有很多方法都可以实现字符识别,比如基于模板匹配的方法等,而本文采用的是一种基于人工神经网络(ANN)模型的方法。该ANN模型有3层神经网络,第一层(输入层)包含288个神经元,因为输入图像的尺寸固定是12×24;第二层(隐含层)包含30个神经元;第三层(输出层)包含44个神经元,之所以是44个神经元,是因为数据集中的车牌一共可能出现44种字符,分别是10个数字“0-9”、24个大写英文字母“A-Z"、10个各省的简称:”鄂“,”赣“,”沪“,”京“,”辽“,”苏“,”皖“,”豫“,”粤“,”浙“。
模型创建的代码:
%% 读取样本数据
DATADIR='.\sample\'; % 待处理图像目录
dirinfo=dir(DATADIR); % 获取图像目录所有文件信息
Name={dirinfo.name}; % 获取文件名
Name(1:2)=[]; % 去除文件夹固有信息
[nouse num_of_char]=size(Name); % 获取类别数量
count = 1;
images = [];
labels = [];
for cnt=1 :num_of_char % for 循环读取所有文件夹
pathname=horzcat(DATADIR, Name{cnt},'\'); % 把路径和名字融合一起
sub_dirinfo=dir(pathname); % 获取图像目录所有文件信息
sub_Name={sub_dirinfo.name}; % 获取文件名
sub_Name(1:2)=[];
[nouse num_of_image]=size(sub_Name);
for i = 1: num_of_image
image = imread(horzcat(pathname,sub_Name{i}));
if size(image,3) >1
image = rgb2gray(image);
end
bw = im2bw(image,graythresh(image));
bw1 = double(reshape(bw,288,1));
images = [images,bw1];
labels(count) = cnt;
count = count +1;
end
end
%% 设置神经网络参数并训练
input_layer_size = 288; % 12x24 输入图像大小
hidden_layer_size = 30; % 隐含层个数
num_labels = num_of_char; % 标签个数
X = images';
y = labels';
initial_Theta1 = randInitializeWeights(input_layer_size, hidden_layer_size); %初始化神经网络参数
initial_Theta2 = randInitializeWeights(hidden_layer_size, num_labels); %初始化神经网络参数
initial_nn_params = [initial_Theta1(:) ; initial_Theta2(:)];
options = optimset('MaxIter', 1200);
lambda = 1;
costFunction = @(p) nnCostFunction(p, ... % 用训练样本计算最优参数
input_layer_size, ...
hidden_layer_size, ...
num_labels, X, y, lambda);
[nn_params, cost] = fmincg(costFunction, initial_nn_params, options);
Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), ...
hidden_layer_size, (input_layer_size + 1));
Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), ...
num_labels, (hidden_layer_size + 1));
save model.mat Theta1 Theta2 Name模型训练的代码:
function [X, fX, i] = fmincg(f, X, options, P1, P2, P3, P4, P5)
% 最小值搜索
if exist('options', 'var') && ~isempty(options) && isfield(options, 'MaxIter')
length = options.MaxIter;
else
length = 100;
end
RHO = 0.01; % a bunch of constants for line searches
SIG = 0.5; % RHO and SIG are the constants in the Wolfe-Powell conditions
INT = 0.1; % don't reevaluate within 0.1 of the limit of the current bracket
EXT = 3.0; % extrapolate maximum 3 times the current bracket
MAX = 20; % max 20 function evaluations per line search
RATIO = 100; % maximum allowed slope ratio
argstr = ['feval(f, X']; % compose string used to call function
for i = 1:(nargin - 3)
argstr = [argstr, ',P', int2str(i)];
end
argstr = [argstr, ')'];
if max(size(length)) == 2, red=length(2); length=length(1); else red=1; end
S=['Iteration '];
i = 0; % zero the run length counter
ls_failed = 0; % no previous line search has failed
fX = [];
[f1 df1] = eval(argstr); % get function value and gradient
i = i + (length<0); % count epochs?!
s = -df1; % search direction is steepest
d1 = -s'*s; % this is the slope
z1 = red/(1-d1); % initial step is red/(|s|+1)
while i < abs(length) % while not finished
i = i + (length>0); % count iterations?!
X0 = X; f0 = f1; df0 = df1; % make a copy of current values
X = X + z1*s; % begin line search
[f2 df2] = eval(argstr);
i = i + (length<0); % count epochs?!
d2 = df2'*s;
f3 = f1; d3 = d1; z3 = -z1; % initialize point 3 equal to point 1
if length>0, M = MAX; else M = min(MAX, -length-i); end
success = 0; limit = -1; % initialize quanteties
while 1
while ((f2 > f1+z1*RHO*d1) | (d2 > -SIG*d1)) & (M > 0)
limit = z1; % tighten the bracket
if f2 > f1
z2 = z3 - (0.5*d3*z3*z3)/(d3*z3+f2-f3); % quadratic fit
else
A = 6*(f2-f3)/z3+3*(d2+d3); % cubic fit
B = 3*(f3-f2)-z3*(d3+2*d2);
z2 = (sqrt(B*B-A*d2*z3*z3)-B)/A; % numerical error possible - ok!
end
if isnan(z2) | isinf(z2)
z2 = z3/2; % if we had a numerical problem then bisect
end
z2 = max(min(z2, INT*z3),(1-INT)*z3); % don't accept too close to limits
z1 = z1 + z2; % update the step
X = X + z2*s;
[f2 df2] = eval(argstr);
M = M - 1; i = i + (length<0); % count epochs?!
d2 = df2'*s;
z3 = z3-z2; % z3 is now relative to the location of z2
end
if f2 > f1+z1*RHO*d1 | d2 > -SIG*d1
break; % this is a failure
elseif d2 > SIG*d1
success = 1; break; % success
elseif M == 0
break; % failure
end
A = 6*(f2-f3)/z3+3*(d2+d3); % make cubic extrapolation
B = 3*(f3-f2)-z3*(d3+2*d2);
z2 = -d2*z3*z3/(B+sqrt(B*B-A*d2*z3*z3)); % num. error possible - ok!
if ~isreal(z2) | isnan(z2) | isinf(z2) | z2 < 0 % num prob or wrong sign?
if limit < -0.5 % if we have no upper limit
z2 = z1 * (EXT-1); % the extrapolate the maximum amount
else
z2 = (limit-z1)/2; % otherwise bisect
end
elseif (limit > -0.5) & (z2+z1 > limit) % extraplation beyond max?
z2 = (limit-z1)/2; % bisect
elseif (limit < -0.5) & (z2+z1 > z1*EXT) % extrapolation beyond limit
z2 = z1*(EXT-1.0); % set to extrapolation limit
elseif z2 < -z3*INT
z2 = -z3*INT;
elseif (limit > -0.5) & (z2 < (limit-z1)*(1.0-INT)) % too close to limit?
z2 = (limit-z1)*(1.0-INT);
end
f3 = f2; d3 = d2; z3 = -z2; % set point 3 equal to point 2
z1 = z1 + z2; X = X + z2*s; % update current estimates
[f2 df2] = eval(argstr);
M = M - 1; i = i + (length<0); % count epochs?!
d2 = df2'*s;
end % end of line search
if success % if line search succeeded
f1 = f2; fX = [fX' f1]';
fprintf('%s %4i | Cost: %4.6e\r', S, i, f1);
s = (df2'*df2-df1'*df2)/(df1'*df1)*s - df2; % Polack-Ribiere direction
tmp = df1; df1 = df2; df2 = tmp; % swap derivatives
d2 = df1'*s;
if d2 > 0 % new slope must be negative
s = -df1; % otherwise use steepest direction
d2 = -s'*s;
end
z1 = z1 * min(RATIO, d1/(d2-realmin)); % slope ratio but max RATIO
d1 = d2;
ls_failed = 0; % this line search did not fail
else
X = X0; f1 = f0; df1 = df0; % restore point from before failed line search
if ls_failed | i > abs(length) % line search failed twice in a row
break; % or we ran out of time, so we give up
end
tmp = df1; df1 = df2; df2 = tmp; % swap derivatives
s = -df1; % try steepest
d1 = -s'*s;
z1 = 1/(1-d1);
ls_failed = 1; % this line search failed
end
if exist('OCTAVE_VERSION')
fflush(stdout);
end
end
fprintf('\n');
训练完模型后,模型参数被保存在model.mat文件中,然后只要加载保存的模型参数就能实现字符识别,其代码实现如下:
function pushbutton5_Callback(hObject, eventdata, handles)
%% 字符识别
images_test_all = handles.testnum;
load model.mat
for i = 1:size(images_test_all,2)
images_test = double(images_test_all(:,i));
pred(i) = predict(Theta1, Theta2, images_test');
end
chepai = [];
for i = 1:size(pred,2)
if pred(i)>0
chepai = [chepai,Name{pred(i)}];
end
end
set(handles.text2,'string',chepai);3、车牌识别系统的功能展示
