图解自注意力机制-通俗易通篇
BERT、RoBERTa、ALBERT、SpanBERT、DistilBERT、SesameBERT、SemBERT、MobileBERT、TinyBERT和CamemBERT的共同点是什么?答案并不是“ BERT”。
而是“自注意力”。我们不仅在讨论承载“ BERT” 的架构,更准确地说是基于 Transformer 的架构。基于 Transformer 的架构主要用于对语言理解任务进行建模,避免使用神经网络中的递归,而是完全信任自注意力在输入和输出之间绘制全局依赖性的机制。但是,这背后的数学原理是什么?
这就是我们今天要探讨的。这篇文章的主要内容是带你了解自注意力模块中涉及的数学运算。读完这篇文章,你应该就能够从零开始编写一个自注意力模块了。
本文的目的不是要解释自注意力模块中的不同数字表示形式和数学运算,也不是为了证明Transfomer 中自注意的原因和精确程度(我相信已经有很多相关资料了)。请注意,本文也没有详细介绍注意力和自注意力之间的区别。
内容大纲
- 图解
- 代码
- 拓展到 Transformer
1. 什么是自注意力?
你可能会想,自注意力是否类似于注意力,答案是肯定的!它们从根本上来说概念和数学运算很多都是相通的。
自注意模块接收 n 个输入,并返回 n 个输出。这个模块会发生什么?用外行的话说,自注意力机制让每个输入都会彼此交互(自),然后找到它们应该更加关注的输入(注意力)。自注意力模块的输出是这些交互的聚合和注意力分数。
2. 图解
图解分为以下步骤:
-
准备输入
-
初始化权重
-
推导键(key)、查询(query)和值(value)
-
计算输入 1 的注意力得分
-
计算 softmax
-
将分数与值相乘
-
总和加权值以获得输出 1
-
对输入 2 和输入 3 重复步骤4–7
注意:实际上,数学运算是矢量化的,即所有输入都经过数学运算(即,变为embedding)。我们稍后会在“代码”部分中看到这一点。
步骤1:准备输入
 图 1.1:准备输入
图 1.1:准备输入
在本教程中,我们从 3 个输入开始,每个输入的尺寸为 4。
输入1:[1,0,1,0]
输入2:[0,2,0,2]
输入3:[1,1,1,1]步骤2:初始化权重
每个输入必须具有三个表示形式(请参见下图)。这些表示形式称为键(橙色),查询(红色)和值(紫色)。对于此示例,让我们假设这些表示的尺寸为 3。因为每个输入的尺寸为 4,这意味着每组权重都必须为 4×3。
注意:我们稍后将看到值的维数也是输出的维数。
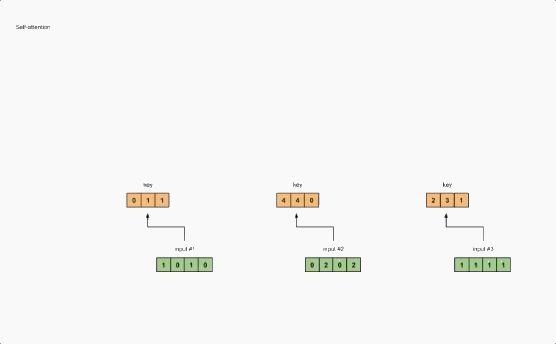 图 1.2:从每个输入得出键,查询和值表示
图 1.2:从每个输入得出键,查询和值表示
为了获得这些表示形式,每个输入(绿色)都将与一组键的权重,一组查询的权重(我知道这不是正确的拼写)和一组值的权重相乘。在我们的示例中,我们如下“初始化”三组权重。
键的权重:
[[0,0,1],
[1,1,0],
[0,1,0],
[1,1,0]]查询权重:
[[1,0,1],
[1,0,0],
[0,0,1],
[0,1,1]]值的权重:
[[0,2,0],
[0,3,0],
[1,0,3],
[1,1,0]]注意:在神经网络设置中,这些权重通常是小数,使用适当的随机分布(如高斯,Xavier和Kaiming分布)随机初始化。
步骤3:派生键、查询和值
现在我们有了三组权重,让我们实际获取每个输入的键、查询和值表示形式。
输入 1 的键表示:
[0,0,1]
[1,0,1,0] x [1,1,0] = [0,1,1]
[0,1,0]
[1,1,0]使用相同的权重集获取输入 2 的键表示:
[0,0,1]
[0,2,0,2] x [1,1,0] = [4,4,0]
[0,1,0]
[1,1,0]使用相同的权重集获取输入 3 的键表示:
[0,0,1]
[1,1,1,1] x [1,1,0] = [2,3,1]
[0,1,0]
[1,1,0]一种更快的方法是对上述操作进行矢量化处理:
[0,0,1]
[1,0,1,0] [1,1,0] [0,1,1]
[0,2,0,2] x [0,1,0] = [4 ,4,0]
[1,1,1,1] [1,1,0] [2,3,1] 图 1.3a:每个输入的派生键表示
图 1.3a:每个输入的派生键表示
进行同样的操作,以获取每个输入的值表示形式:
[0,2,0]
[1,0,1,0] [0,3,0] [1,2,3]
[0,2,0,2] x [1,0,3] = [2 ,8,0]
[1,1,1,1] [1,1,0] [2,6,3]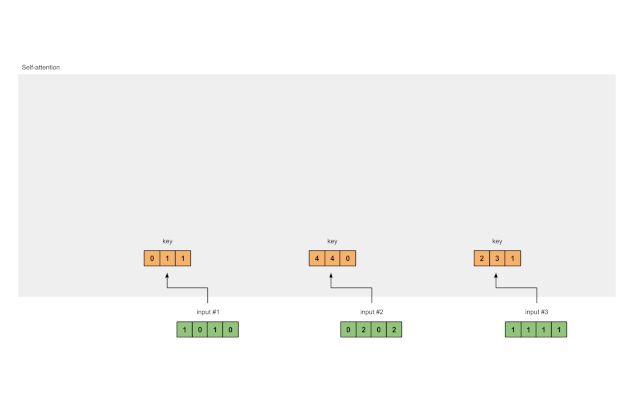 图 1.3b:每个输入的派生值表示
图 1.3b:每个输入的派生值表示
最后是查询表示形式:
[1,0,1]
[1,0,1,0] [1,0,0] [1,0,2]
[0,2,0,2] x [0,0,1] = [2 ,2,2]
[1,1,1,1] [0,1,1] [2,1,3] 图 1.3c:从每个输入中派生查询表示
图 1.3c:从每个输入中派生查询表示
注意:实际上,可以将偏差向量添加到矩阵乘法的乘积中。
步骤4:计算输入 1 的注意力得分
 图 1.4:根据查询 1 计算注意力得分(蓝色)
图 1.4:根据查询 1 计算注意力得分(蓝色)
为了获得注意力得分,我们首先在输入 1 的查询(红色)与所有键(橙色)(包括其自身)之间取一个点积。由于有 3 个关键表示(因为我们有3个输入),因此我们获得 3 个注意力得分(蓝色)。
[0,4,2]
[1,0,2] x [1,4,3] = [2,4,4]
[1,0,1]注意,我们仅使用输入 1 的查询。稍后,我们将对其他查询重复相同的步骤。
注意:以上操作被称为点积注意力(dot product attention),这是众多评分函数中的一个,其它评分函数还包括扩展式点积和 additive/concat,请参阅《图解神经机器翻译中的注意力机制》。
步骤 5:计算 softmax
 图 1.5:Softmax 注意分数(蓝色)
图 1.5:Softmax 注意分数(蓝色)
在所有注意力得分中使用 softmax(蓝色)。
softmax([2,4,4])= [0.0,0.5,0.5]步骤6:将分数乘以值
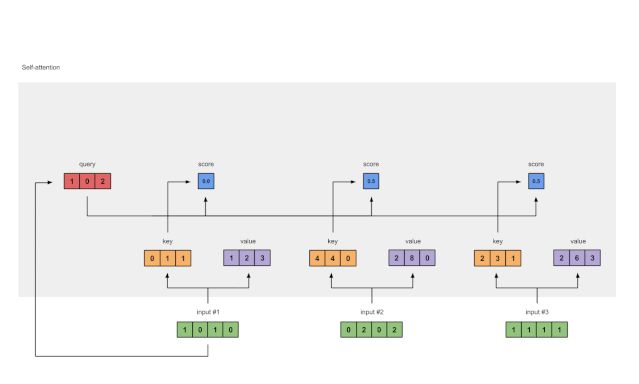 图 1.6:从乘数值(紫色)和分数(蓝色)得出的加权值表示(黄色)
图 1.6:从乘数值(紫色)和分数(蓝色)得出的加权值表示(黄色)
每个经过 softmax 的输入的最大注意力得分(蓝色)乘以其相应的值(紫色),得到 3 个对齐向量(alignment vector, 黄色)。在本教程中,我们将它们称为加权值(weighted value)。
1:0.0 * [1、2、3] = [0.0、0.0、0.0]
2:0.5 * [2、8、0] = [1.0、4.0、0.0]
3:0.5 * [2、6、3] = [1.0、3.0、1.5]步骤7:求和加权值以获得输出 1
 图 1.7:将所有加权值相加(黄色)以得出输出 1(深绿色)
图 1.7:将所有加权值相加(黄色)以得出输出 1(深绿色)
取所有加权值(黄色)并将它们按元素求和:
[0.0,0.0,0.0]
+ [1.0,4.0,0.0]
+ [1.0,3.0,1.5]
-----------------
= [2.0,7.0,1.5]所得向量[2.0、7.0、1.5](深绿色)为输出1,该输出基于输入1与所有其他键(包括其自身)交互的查询表示形式。
步骤 8:重复输入 2 和输入 3
既然我们已经完成了输出 1,我们将对输出 2 和输出 3 重复步骤 4 至 7。我相信你自己就可以操作。
 图 1.8:对输入 2 和输入 3 重复前面的步骤
图 1.8:对输入 2 和输入 3 重复前面的步骤
注意:由于点积分数功能,查询和键的维必须始终相同。但是,值的维数可能不同于 查询和键。结果输出将遵循值的维度。
3. 代码
这是PyTorch代码(https://pytorch.org/),PyTorch是流行的 Python 深度学习框架。为了方便使用在以下代码段中索引中的@operator API、.T 和 None,请确保你使用的是Python≥3.6 和 PyTorch 1.3.1。只需将它们复制并粘贴到 Python / IPython REPL 或 Jupyter Notebook 中即可。
步骤1:准备输入
import torch
x = [
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1] # Input 3
]
x = torch.tensor(x, dtype=torch.float32)步骤2:初始化权重
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)步骤3:派生键,查询和值
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
print(keys)
# tensor([[0., 1., 1.],
# [4., 4., 0.],
# [2., 3., 1.]])
print(querys)
# tensor([[1., 0., 2.],
# [2., 2., 2.],
# [2., 1., 3.]])
print(values)
# tensor([[1., 2., 3.],
# [2., 8., 0.],
# [2., 6., 3.]
步骤4:计算注意力分数
attn_scores = querys @ keys.T
# tensor([[ 2., 4., 4.], # attention scores from Query 1
# [ 4., 16., 12.], # attention scores from Query 2
# [ 4., 12., 10.]]) # attention scores from Query 3步骤5:计算softmax
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1)
# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],
# [6.0337e-06, 9.8201e-01, 1.7986e-02],
# [2.9539e-04, 8.8054e-01, 1.1917e-01]])
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
步骤6:将分数乘以值
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
# tensor([[[0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000]],
#
# [[1.0000, 4.0000, 0.0000],
# [2.0000, 8.0000, 0.0000],
# [1.8000, 7.2000, 0.0000]],
#
# [[1.0000, 3.0000, 1.5000],
# [0.0000, 0.0000, 0.0000],
# [0.2000, 0.6000, 0.3000]]])步骤7:求和加权值
outputs = weighted_values.sum(dim=0)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1
# [2.0000, 8.0000, 0.0000], # Output 2
# [2.0000, 7.8000, 0.3000]]) # Output 3注意:PyTorch 为此提供了一个 API nn.MultiheadAttention。但是,此 API 要求你输入键、查询并估算 PyTorch 张量。此外,该模块的输出经过线性变换。