Pytorch日常debug记录(一)
(debug到一半才想起要写这么个记录......)
2021/1/12
1. ValueError: At least one stride in the given numpy array is negative, and tensors with negative strides are not currently supported. (You can probably work around this by making a copy of your array with array.copy().)
解决:Pytorch在训练过程中常见的问题
这个原因是因为程序中操作的numpy中有使用负索引的情况:image[…, ::-1]。解决办法比较简单,加入image这个numpy变量引发了错误,返回image.copy()即可。因为copy操作可以在原先的numpy变量中创造一个新的不适用负索引的numpy变量。
所以我在image[…, ::-1]后边加了个.copy()就可以了。
image = cv2.imread(path)
## image = image[:,:,::-1] 这是出错时候写的
image = image[:,:,::-1].copy() ## 加上.copy()之后就没有报这个错误了2. RuntimeError: Given groups=1, weight of size [64, 3, 7, 7], expected input[64, 100, 100, 3] to have 3 channels, but got 100 channels instead
解决:https://blog.csdn.net/qazwsxrx/article/details/103755834
能看出来是输入输出的通道问题,想了想,问题还是出在了上边的image的读取。
cv2.imread() 导入图片时是BGR通道顺序,因此,我们通过image[:,:,::-1]将BGR转换成了RGB,接着加了个.copy()【如上条所示】
具体为什么会出现这样的问题我是不知道的,然后就直接对它进行了替换。使用PIL的Image.open(path)替换了cv2.imread()
替换后的代码如下:
image = Image.open(path).convert('RGB')
3. 然后又遇上问题了:RuntimeError: Given input size: (512x4x4). Calculated output size: (512x0x0). Output size is too small
解决:https://blog.csdn.net/jsk_learner/article/details/103833034,
这个其实是torchvision的版本问题,我的torchvision版本太低了。关于torchvision的版本更新,在我的下一个帖子(链接)
同样困扰着我的版本问题是torchvision里面的transform没有Resize和ToPILImage
【即:在transforms.Compose([])里边】#transforms.ToPILImage(), #transforms.Resize((224, 224)),这俩不能用
所以我就把代码放到服务器上了运行了,这个问题就没出现了。
所以,更新一下版本~
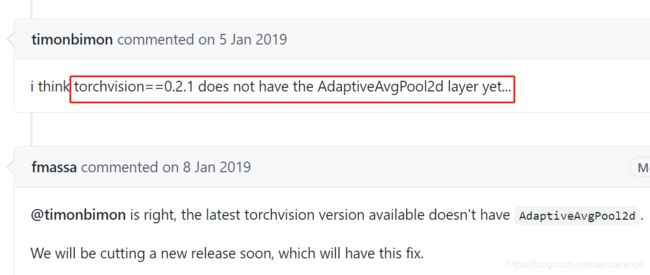
4. Runtime Error: CUDA error: out of memory
这个问题主要是放在服务器上运行的时候代码里面没有指定使用的cuda而使用默认的GPU(在我这里是0号), 默认的GPU正好有其他程序在跑,所以我就直接指定其他的GPU来使用【我没有在代码里面指定,而是直接在终端指定】。
export CUDA_VISIBLE_DEVICES=1指定第一块GPU进行训练,然后再python train.py
5. TypeError: pic should be Tensor or ndarray. Got
检查一圈代码后发现原先在使用cv2之后的部分代码没有改过来。
我在transform.compose()里边使用了transforms.ToPILImage(),所以直接把这句注释掉了就好了。
6. RuntimeError: CUDA error: device-side assert triggered
说是标签(label)越界
使用pytorch报错:RuntimeError: CUDA error: device-side assert triggered里的CUDA_LAUNCH_BLOCKING=1 python train.py输出的错误是RuntimeError: cuda runtime error (59) : device-side assert triggered
然后找到的解决办法是:RuntimeError: cuda runtime error (59) : device-side assert triggered
文章中说异常大概是和计算损失值有关,查阅资料时发现很多道友都遇到过这种cuda runtime error(59),大部分都是索引异常。
然后我特地去代码文件中看了下【这里因为我是跑别人的代码,不是我自己从头写到尾的,而数据集和标签是我自己弄的,就可能跟原作者的代码不是特别匹配。】
数据集标签分为7个类,从0-6,所以我的label标签是从0到6的,但是我发现原作者代码里面,label的值都进行了减1操作,我估计原作者的label是从1到7的,所以导致0标签就变成-1,然后就出错了。
最后我就把这个改过来就可以了。