使用Fairseq进行机器翻译
前言
一、文件存放位置
二、数据预处理
1.对中文进行分词操作
2.对英文数据操作
2.1 Normalize punctuation
2.2 Tokenizer
三、Train Test Valid 文件的划分
四、Sub-BEP处理
五、二值化处理
六、进入训练
七、使用tensorbord查看训练的结果
八、使用模型预测
1.生成式翻译
2.交互式翻译
九、译文处理
总结
前言
使用fairseq工具以及简单的中英文语料使用transfomer进行翻译任务。详细的方法参照文档 https://fairseq.readthedocs.io/en/latest/command_line_tools.html
一、文件存放位置
将中英文对照文件放入源文件位置:/root/Fairseq_Data/Origianl_Data/下的zh.txt与en.txt
二、数据预处理
1.对中文进行分词操作
- 在/root/Fairseq_Data目录下新建文件夹ZH_EN_Token,此文件存放经过plt分词后的中文与经过normal与Token之后的英文。
- 在/root/fairseq/examples/translation/utils 文件夹中的Tokener.py 是对中文进行分词的python程序。
- 示例代码如下:
cd /root/fairseq/examples/translation/utils
python Tokener.py3.执行完毕之后会在 /root/Fairseq_Data/ZH_EN_Token 目录下生成zh_Token.txt。
2.对英文数据操作
2.1 Normalize punctuation
1.进入到 /root/fairseq/examples/translation 目录下使用mosesdecoder文件中的脚本对英文数据进行处理
#进入到指定目录
cd /root/fairseq/examples/translation
2.使用/normalize-punctuation.perl 脚本对数据操作
perl /root/fairseq/example/translation/mosesdecoder/scripts/tokenizer/normalize-punctuation.perl -l en /root/Fairseq_Data/ZH_EN_Token/norm.en3.处理完成后会在/root/Fairseq_Data/ZH_EN_Token/的目录下生成norm.en文件
2.2 Tokenizer
1.进入到 /root/fairseq/examples/translation 目录下使用mosesdecoder文件中的脚本对英文数据进行处理
#进入到指定目录
cd /root/fairseq/examples/translation
2.使用tokenizer.perl -a -l 命令对已经noemalize好的英文数据进行分词梳处理
perl /root/fairseq/examples/translation/mosesdecoder/scripts/tokenizer/tokenizer.perl -a -l en /root/Fairseq_Data/ZH_EN_Token/norm.tok.en
3.处理完毕之后会在/root/Fairseq_Data/ZH_EN_Token文件下生成norm.tok.en文件

三、Train Test Valid 文件的划分
因为用到的工具类都存放为/root/fairseq/examples/translation/utils位置,所以需要进到/root/fairseq/examples/translation/utils目录下
#进入到指定位置
/root/fairseq/examples/translation/utils
#执行文件划分程序
python prepare_6_files.py执行完毕之后会在 /root/Fairseq_Data/Split_Train_Test_Valid 文件夹下生成六个文件。
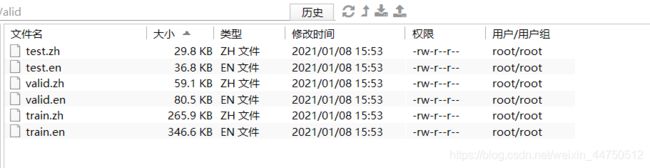
四、Sub-BEP处理
1.将/root/fairseq/examples/translation/下 subword-nmt文件的路径变为动态路径方便后续使用
export PYTHONPATH=$(pwd)/subword-nmt:$PYTHONPATH2.对/root/Fairseq_Data/Split_Train_Test_Valid 文件下的 train.zh和train.en进行处理,创建词汇表
#进入指定目录
cd /root/Fairseq_Data/Split_Train_Test_Valid
#创建词汇表
python -m learn_joint_bpe_and_vocab --input train.zh train.en -s 32000 -o bpe.codes --write-vocabulary bpe.vocab.zh bpe.vocab.en3.运行成功后会在/root/Fairseq_Data/Split_Train_Test_Valid文件夹下生成三个文件
1.bpe.vocab.zh 2.bpe.vocab.en 3.bpe.codes
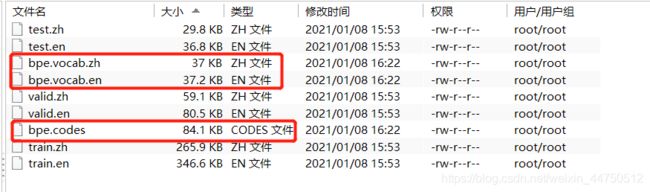
4.将字节对编码应用于我们的训练、开发和测试数据
mkdir ne_WIPO_BPE_zh_en
python -m apply_bpe -c bpe.codes --vocabulary bpe.vocab.zh --vocabulary-threshold 50 < train.zh > ne_WIPO_BPE_zh_en/train.zh
python -m apply_bpe -c bpe.codes --vocabulary bpe.vocab.en --vocabulary-threshold 50 < train.en > ne_WIPO_BPE_zh_en/train.en
python -m apply_bpe -c bpe.codes --vocabulary bpe.vocab.zh --vocabulary-threshold 50 < valid.zh > ne_WIPO_BPE_zh_en/valid.zh
python -m apply_bpe -c bpe.codes --vocabulary bpe.vocab.en --vocabulary-threshold 50 < valid.en > ne_WIPO_BPE_zh_en/valid.en
python -m apply_bpe -c bpe.codes --vocabulary bpe.vocab.zh --vocabulary-threshold 50 < test.zh > ne_WIPO_BPE_zh_en/test.zh
python -m apply_bpe -c bpe.codes --vocabulary bpe.vocab.en --vocabulary-threshold 50 < test.en > ne_WIPO_BPE_zh_en/test.en5.运行结束后会在 /root/Fairseq_Data/Split_Train_Test_Valid 文件夹下生成ne_WIPO_BPE_zh_en 文件,其中生成六个文件
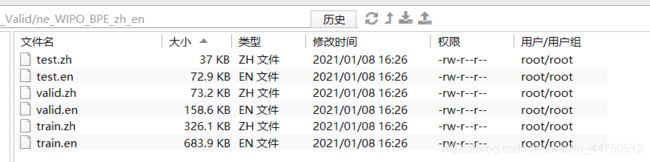
五、二值化处理
1.退回到需要退到fairseq文件夹下
cd /root/fairseq2.执行命令行
TEXT=/root/Fairseq_Data/Split_Train_Test_Valid/ne_WIPO_BPE_zh_en
fairseq-preprocess --source-lang zh --target-lang en --trainpref $TEXT/train --validpref $TEXT/valid --testpref $TEXT/test --destdir data-bin/ne_WIPO.tokenized.zh-en --workers 20
3.运行成功之后会在在data-bin下会生成文件夹ne_WIPO.tokenized.zh-en文件夹下存放生成的二值化数据
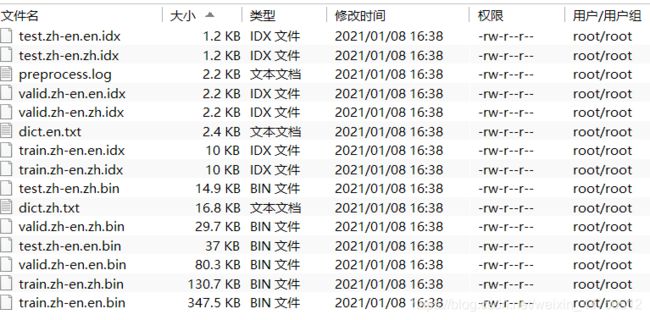
六、进入训练
1.新建screen 并进入
screen -S train
screen -r train2.激活建立的fairseq虚拟环境
conda activate fairseq3.进入到fairseq目录下
cd /root/fairseq4.开始训练
CUDA_VISIBLE_DEVICES=7 fairseq-train data-bin/ne_WIPO.tokenized.zh-en --arch transformer --optimizer adam --adam-betas '(0.9, 0.98)' --clip-norm 0.0 --lr 5e-4 --lr-scheduler inverse_sqrt --warmup-updates 4000 --dropout 0.3 --weight-decay 0.0001 --criterion label_smoothed_cross_entropy --label-smoothing 0.1 --max-tokens 4096 --eval-bleu --eval-bleu-args '{"beam": 5, "max_len_a": 1.2, "max_len_b": 10}' --eval-bleu-detok moses --eval-bleu-remove-bpe --eval-bleu-print-samples --best-checkpoint-metric bleu --maximize-best-checkpoint-metric --no-progress-bar --log-interval 20 --save-dir checkpoints_WIPO --keep-interval-updates 20 --tensorboard-logdir Fairseq_Data-transformer | tee Fairseq_Data-transformer.log
5.Transfomer的结构
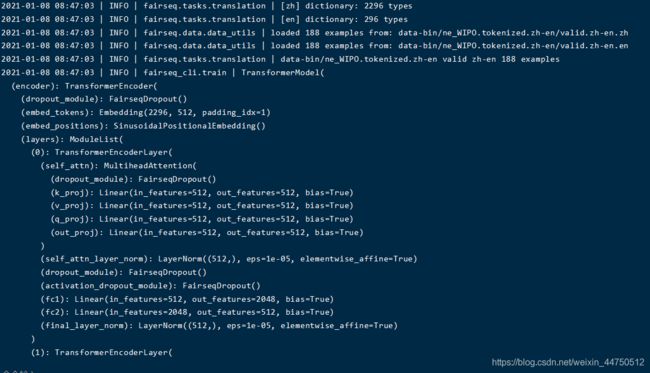

6.训练过程
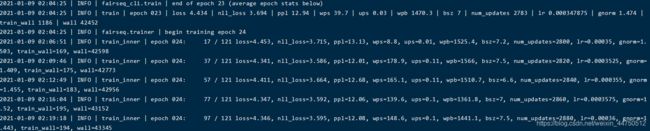
七、使用tensorbord查看训练的结果
1.进入到指定好的保存到日志保存的上级目录
cd /root/fairseq
2.输入查看命令
tensorboard --logdir=./Fairseq_Data-transformer3.控制台输出
![]()
4.tensorbord监控
在浏览器中输入 http://localhost:6006/ 查看

详细指标变化
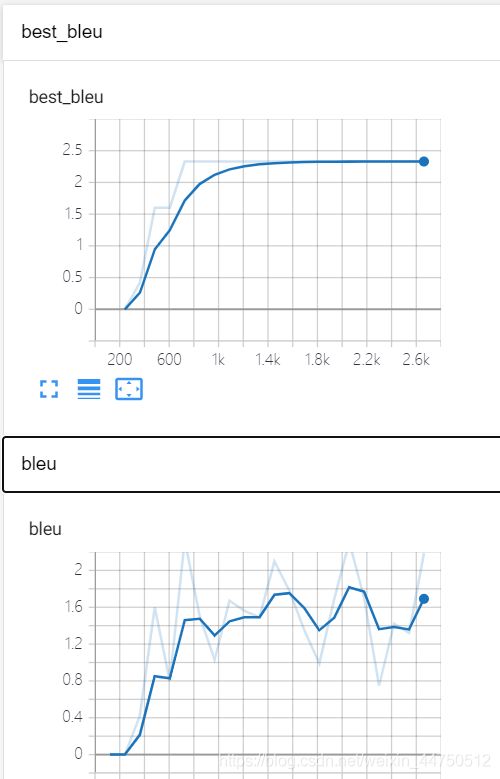
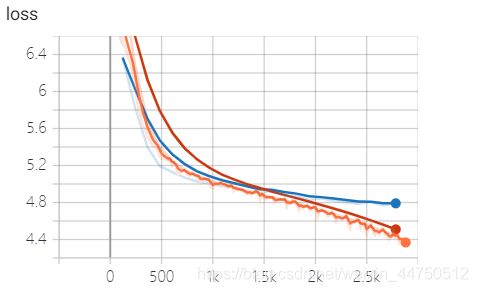
blue不断上升 loss不断下降 模型训练正常。
八、使用模型预测
训练好模型后,可以使用fairseq-generate(用于二进制数据)或fairseq-interactive(用于原始文本)生成翻译
1.生成式翻译
1.使用生成式翻译需要用到fairseq-generate,翻译的语料是之前已经准备好在 /root/fairseq/data-bin/ne_WIPO.tokenized.zh-en 下的文件
#进入fairseq目录下
cd /root/fairseq
#使用fairseq-generate生成翻译
fairseq-generate data-bin/ne_WIPO.tokenized.zh-en --path checkpoints_WIPO/checkpoint_best.pt --skip-invalid-size-inputs-valid-test --beam 5 --remove-bpe > predict_test.txt2.翻译过程

3.翻译好的译文会在只能够的 predict_test.txt中保存
4.查看翻译结果

5.结果分析
S 是经过分词后的源语言。
T 是经过Token之后的目标语言。
H 是模型预测的句子,H前的数字是这个句子的预测概率的log再除总长度
P 是每个单词的预测概率的log,全部相加除句子总长度等于H
2.交互式翻译
1.使用交互式翻译需要用到 fairseq-interactive,翻译的语料是之前已经准备好在 /root/fairseq/data-bin/ne_WIPO.tokenized.zh-en 下的文件
#进入fairseq目录下
cd /root/fairseq
#使用fairseq-generate生成翻译
fairseq-interactive data-bin/ne_WIPO.tokenized.zh-en --path checkpoints_WIPO/checkpoint_best.pt --skip-invalid-size-inputs-valid-test --beam 5 --remove-bpe2.翻译过程

3.交互翻译会在控制台直接输出翻译结果

九、译文处理
1.将得到的译文进行抽取处理
grep ^H predict_test.txt | cut -f3- > predict_test1.txt 2.去除bpe符号,将处理好的文件保存在predict_test2.txt中
2.去除bpe符号,将处理好的文件保存在predict_test2.txt中
sed -r 's/(@@ )| (@@ ?$)//g' < predict_test1.txt > predict_test2.txt3.计算bleu值,对比标准是用tokenized后的文件:
使用mosesdecoder工具中的multi-bleu.perl进行计算
perl /root/fairseq/examples/translation/mosesdecoder/scripts/generic/multi-bleu.perl /root/Fairseq_Data/Split_Train_Test_Valid/test.en < /root/fairseq/predict_test2.txt4.计算结果

总结
使用fairseq以及其中的命令行进行简单的机器翻译任务。