python数据分析及可视化(九)pandas数据规整(分组聚合、数据透视表、时间序列、数据分析流程)
作业
- 拼接多个csv文件
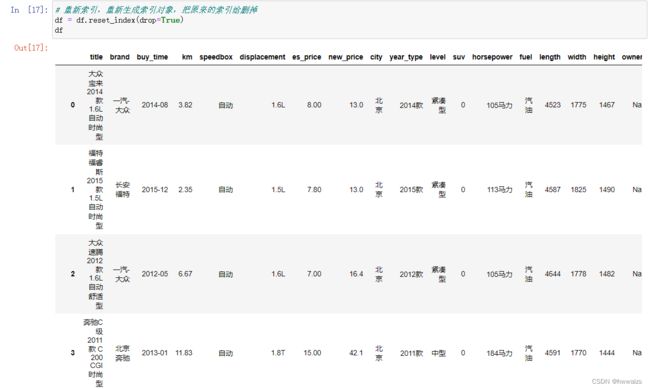
- 去除重复数据,重新索引
- 自动挡和手动挡数目
- 计算每个城市二手车数量
- 统计每个汽车品牌平均售价价格(不是原价)




分组与聚合
如下表所示,5行3列的表格,5种水果分别对应的名称,颜色,价格。求苹果的平均价格,在数据量少的情况下,直接找到相加求平均值即可,实际操作过程中可能会有几十万条数据,可以用布尔索引把符合苹果的数据先提取出来,然后对价格列求和,然后除以筛选出的表的长度;也可以直接对价格列求平均值。

分组与聚合的应用
数据包含在Series、DataFrame数据结构中,可以根据一个或多个键分离到各个组中。分组操作之后,一个函数就可以应用到各个组中,产生新的值。如图所示

原表中有两列数据,可以理解key为前面为课程名称,data为考试分数,可以取求两次分数的最高分、平均分、最低分以及成绩和等,Split为按key列相同的内容进行分组,Apply是聚合按照分组的内容进行求和(sum)。
利用分组的方式来实现求平均值,根据水果列的值进行分组,得到DataFrameGroupBy对象;遍历取出每一个元素,可以得到3个元组(apple,banana,orange),每个元组中有2个元素(水果名称,水果信息);水果信息以表格的形式存放,可以把分组对象先转换成列表,然后转换为字典,再用键值对取出苹果的值,再去求平均。也可以通过水果分组,对价格求平均进行聚合,得到每一种水果的平均值。
这就是分组聚合的操作,先分组,然后对每一列进行聚合的方法。


返回的结果是Series,可以利用语法糖的方法,在聚合的列上多加个[],把结果返回为DataFrame。

按照水果的颜色来分组,得到有层级索引的Series,在聚合的列“price”上多加个[],可以转为DataFrame,在分组的时候可以对表或者列进行分组。

拥有层级索引的Series 转为DataFrame。

求水果的种类,可以用分类聚合的方法,也可以用水果出现的次数进行计算。

自定义聚合函数
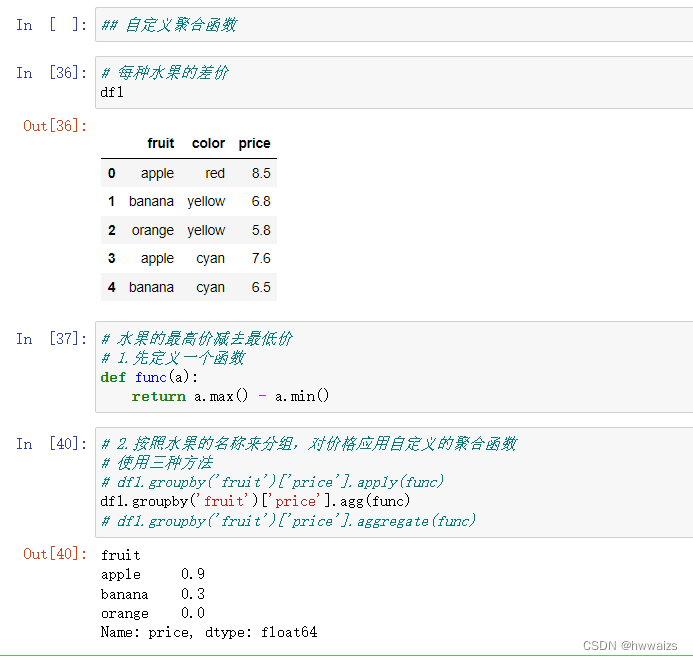
求每一种水果的差价,青苹果和红苹果价格之间的差值。这就要用到自定义聚合函数,从分组开始。自定义一个函数,实现最大值减去最小值的功能;对数据按照水果的名称来分组,对价格应用自定义的聚合函数。
例题1
读取如下图所示的文件,增加“余额”列,此列显示每个人增加存款后的账户余额。
读取文件,从有效列名称开始读取,实现余额是存款数据的累加功能。
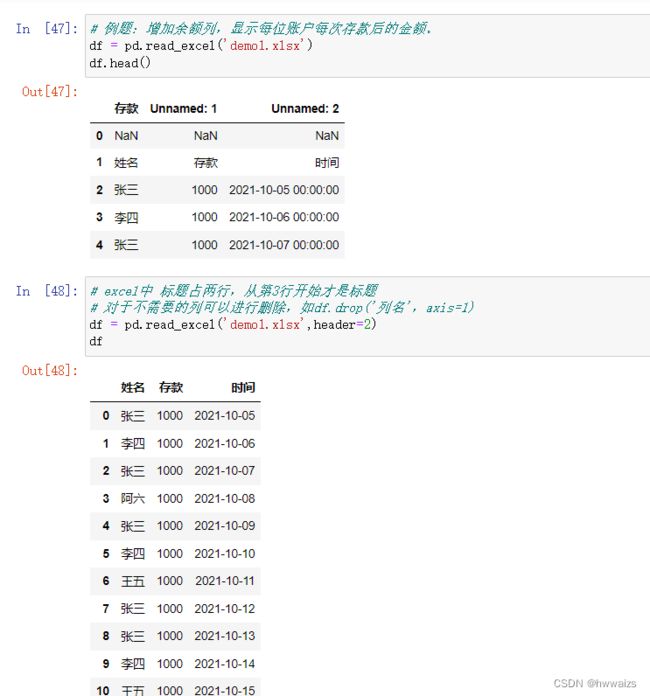
如张三,10月5日存款1000,余额应为1000;10月7日存款1000,余额就应为2000,依次类推。从表的信息来看,只有存款列是数值,聚合的时候不用指定就可以对存款进行聚合,如果有两列是数值,就要指定聚合是在哪一列上的操作。计算时候要以相同的姓名进行分组,然后使用Numpy的sumsum累计求和的方法。

df.to_excel('demo2.xlsx',index=False) # 保存数据
这是分组聚合操作的便利和应用,数据清洗是为了去除不干净的或者是对接下来分析造成影响的数据,得到比较规整的数据;数据规整、合并、连接、分组聚合等等是按照需求来操作数据。
数据透视表
数据透视表是一种可以对数据动态排布并且分类汇总的表格格式,可以通过groupby、分组聚合操作来实现,也可以用特定的方法和函数实现。
例题2
表中显示的是泰坦尼克号乘客的生还概率、船舱、年龄等数据,计算性别跟存活几率的关系,性别、船舱等级与存货几率的关系。


pivot_table(values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True, margins_name=‘All’, observed=False) -> ‘DataFrame’
默认aggfunc='mean’是求平均,dropna=True删除空值,fill_value=None不填充,可以更改参数
Pandas时间序列
Python 内置时间模块
time的延迟sleep,写程序时为了防止爬取的时间过快,每次爬取的时候设置时间间隔。
1.时间戳,给机器看的,每过一秒,时间戳加1,从1970年1月1日0时0分0秒到现在的时间偏移量,单位是秒。
2.结构化时间,用来操作时间,把时间戳转化为时间,返回的是本地时间,gmtime也是结构化时间,得到的是0时区的时间,与我们东八区的时间相差8个小时。


相互转换的关系如下图所示。

日期与实际数据类型
从8:00到现在 过了多长时间了,如现在是9:27,则是过了1个小时27分钟了,计算方法是现在的时间减去开始的时间。计算机进行运算的时候是 只是大数减去小数,用现在的时间戳减去8点时候的时间戳,差值就是偏移,单位是秒,平时我们对于时间的概念是,花了多少小时多少分,而不是多少秒。在新闻网站(如今日头条)中,会有新闻发布的时间,如多少分钟、多少小时前等等,这个是用你看到新闻的时间戳减去新闻发布的时间戳,再转化为结构化时间,得到过了多少小时多少分钟。
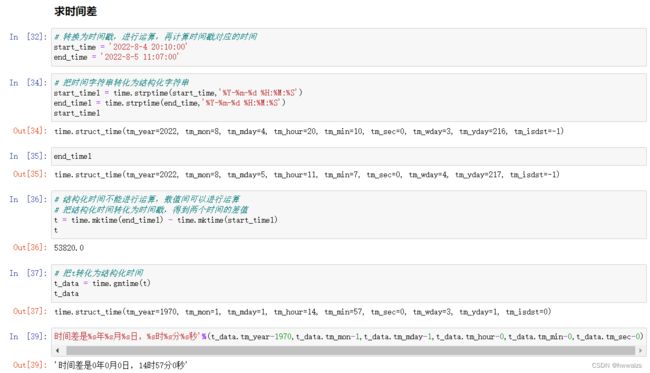

datetime与字符串相互转换

时间序列
时间序列数据在很多领域都是重要的结构化数据形式,比如:金融,神经科学,生态学,物理学。在多个时间点观测的数据形成了时间序列。时间序列可以是固定频率的,也可以是不规则的。
时间序列索引


pd.set_option('display,max_rows',None) # 显示表中所有的数据
从2020年1月1日开始,索引为日期,创建1000条数据,从中选择2021年的数据。时间序列作为索引,在筛选时间范围内的数据时非常方便,不用再去写布尔索引操作,切片等,直接用“表名[‘年份-月份’]”就可以了。
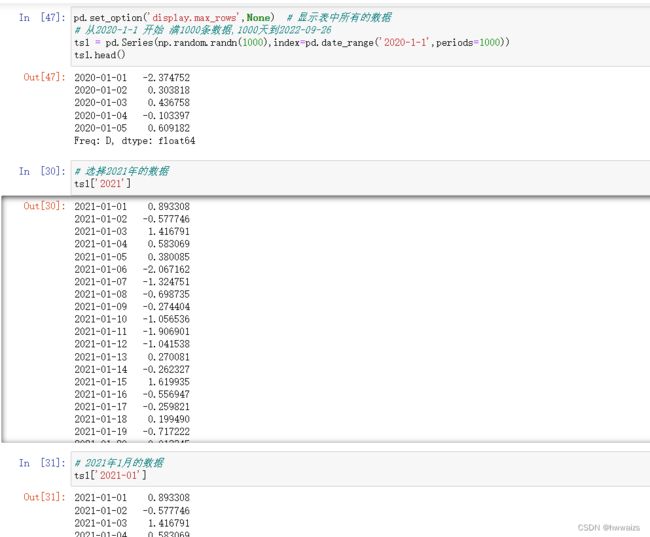


取2020年1月6日之前的数据,after=‘1/6/2020’,取值的结尾是2020-1-6;取2022年9月20日之后的数据,before=‘9/20/2022’,取值的开头是2022-9-20。
带有重复索引的时间序列
列表中字符串内容存在相同的时间值,通过pd.DatetimeIndex把列表转换为时间序列索引对象,进而得出不同学生的报到时间,检查索引值,提取每天报到的数据。groupby通过表在某一列进行分组,在Series对象应用gruopby分组统计的时候,指定参数level=0,会按照索引对象进行分组。

日期范围
生成日期范围的方法:
1.pd.date_range('开始日期','结束日期')
2.pd.date_range('开始日期',periods=天数) ,从开始日期之后天数的日期
3.pd.date_range(end='开始日期',periods=天数) ,从开始日期之前天数的日期

生成数据的时候默认freq='D’指的是频率为天,可以进行更改,如freq=‘M’(H),生成频率为1月(小时)一次
移动数据
指滑动窗口的数据移动,如图是按照月份进行统计的数据,可以利用shift把统计表的数据整体往上或者往下移动,对原数据没有影响,需用返回值接收,保存数据。

重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,
降采样:将高频率数据转化为低频率数据
升采样:低频率数据转化为高频率数据
统计频率从每天的统计转为每个月的统计,从高频到低频,为降采样。


采集频率从一周改为每天一次,采集频率提高为升采样,需要在后面加上asfreq,没有的数据自动填充NaN,可以使用ffill()把NaN值上面的数据往下拉进行填充,使用bfill()把NaN值下面的数据往上拉进行填充。


数据分析流程
1.原始数据。只要有数据(爬取,内部的数据)都可以,相当于做菜的原材料
2.数据清洗和准备(预处理)。相当于把菜进行清洗和切块。
3.数据分析和可视化。分析结果通过可视化的图表来展示,还包括假设验证。相当于做完菜后的摆盘。
4.总结,得出结论。相当于对菜的评价。对分析的问题得出结论,导致营业额下降的原因,营销的策略对顾客有没有帮助,品牌广告的投入对销售额的影响。要给出切实可行的方案。
这是简单的数据分析流程,也称为探索性的数据分析。通过机器学习可以掌握预测型的数据分析,通过算法模型达到预测的效果,如根据现有的数据预测下个月的营销额。
1.读取数据
以公司的招聘信息为例进行数据处理,包含公司的位置,岗位要求,公司定位,招聘岗位,薪资等。如果读取失败,可以设定engine=‘python’,要指定编码格式,encoding=‘utf-8’或者’gbk’,‘gb2312’,'gb18030’等,可以用info()判断一下数据中的问题,看有没有需要清洗的内容,有多少条数据,是否有缺失值,数据的类型等。


2.数据清洗和准备
删除重复的数据,如招聘岗位对应的ID。在这个表中,同一家公司职位对应的ID不应该是相同的,可以对岗位ID进行去重,进行数据清洗。如果缺失值的数据对分析没有影响就可以不用处理,做数据分析可以根据问题进行分析,带着问题去做数据分析,如果接下来的解决问题时,没有对这列相关内容进行使用,就没有必要去做处理。除了数据清洗,还会涉及到数据规整,利用函数进行映射,如薪资是个范围,可以新增两列分别代表最高和最低薪资,然后求平均值。


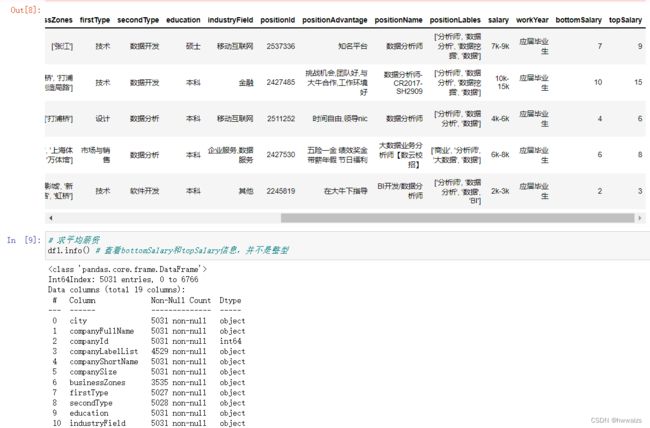

原数据6876 条数据,对positionId删除重复项后,剩下5031条数据,根据 ‘-’ 的位置来取值,滤掉字符串,把得到的取值转为数值型,求平均值。
3.数据分析
求每个城市的招聘信息的数量,看一下哪个城市招聘的人数比较多


通过图表的形式来展示得到的结果,直观的显示出每个城市招聘的数量,绘制饼图、条形图等等
4.得出结论
一线城市对数据分析人员的需求比较大。