Pandas-数据操作-数值型(一):统计函数【describe、count、sum、mean、median、max、std、skew(偏度)、kurt(峰度)】【参数:axis、skipna】
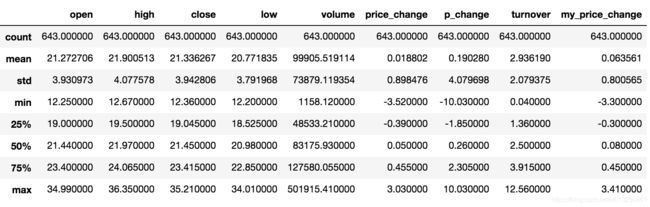
综合分析: 能够直接得出很多统计结果,count, mean, std, min, max 等
# 计算平均值、标准差、最大值、最小值
data.describe()
一、统计函数
| 统计函数 | 描述 |
|---|---|
count |
Number of non-NA observations |
sum |
Sum of values |
mean |
Mean of values |
median |
Arithmetic median of values |
min |
Minimum |
max |
Maximum |
mode |
Mode |
abs |
Absolute Value |
prod |
Product of values |
std |
Bessel-corrected sample standard deviation |
var |
Unbiased variance |
idxmax |
compute the index labels with the maximum |
idxmin |
compute the index labels with the minimum |
对于单个函数去进行统计的时候,坐标轴还是按照默认列“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)
1、Series
import numpy as np
import pandas as pd
# 主要数学计算方法,可用于Series和DataFrame
s = pd.Series(np.random.rand(10) * 10)
print("s = \n", s)
print('-' * 200)
# count统计非Na值的数量
print("count统计非Na值的数量: s.count() = ", s.count())
print('-' * 100)
# min统计最小值
print("min统计最小值: s.min() = ", s.min())
print('-' * 100)
# max统计最大值
print("max统计最大值: s.max() = ", s.max())
print('-' * 100)
# quantile统计分位数,参数q确定位置
print("quantile统计分位数,参数q确定位置: s.quantile(q=0.75) = ", s.quantile(q=0.75))
print('-' * 100)
# sum求和
print("sum求和: s.sum() = ", s.sum())
print('-' * 100)
# mean求平均值
print("mean求平均值: s.mean() = ", s.mean())
print('-' * 100)
# median求算数中位数,50%分位数
print("median求算数中位数,50%分位数: s.median() = ", s.median())
print('-' * 100)
# std求标准差
print("std求标准差: s.std() = ", s.std())
print('-' * 100)
# var求方差
print("var求方差: s.var() = ", s.var())
print('-' * 100)
# skew样本的偏度
print("skew样本的偏度: s.skew() = ", s.skew())
print('-' * 100)
# kurt样本的峰度
print("kurt样本的峰度: s.kurt() = ", s.kurt())
print('-' * 200)
打印结果:
s =
0 1.268546
1 6.385458
2 9.744136
3 0.192000
4 5.736461
5 8.635534
6 2.635359
7 3.042843
8 2.880422
9 5.899908
dtype: float64
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
count统计非Na值的数量: s.count() = 10
----------------------------------------------------------------------------------------------------
min统计最小值: s.min() = 0.19200024578894803
----------------------------------------------------------------------------------------------------
max统计最大值: s.max() = 9.744136205123855
----------------------------------------------------------------------------------------------------
quantile统计分位数,参数q确定位置: s.quantile(q=0.75) = 6.264070647567895
----------------------------------------------------------------------------------------------------
sum求和: s.sum() = 46.42066667909582
----------------------------------------------------------------------------------------------------
mean求平均值: s.mean() = 4.642066667909582
----------------------------------------------------------------------------------------------------
median求算数中位数,50%分位数: s.median() = 4.3896517346977975
----------------------------------------------------------------------------------------------------
std求标准差: s.std() = 3.138819536014843
----------------------------------------------------------------------------------------------------
var求方差: s.var() = 9.852188079668435
----------------------------------------------------------------------------------------------------
skew样本的偏度: s.skew() = 0.2737130849268303
----------------------------------------------------------------------------------------------------
kurt样本的峰度: s.kurt() = -0.9683145338195316
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Process finished with exit code 0
2、DataFrame
DataFrame:统计函数是对每一列的数据进行统计运算。
import numpy as np
import pandas as pd
# 主要数学计算方法,可用于Series和DataFrame(1)
df = pd.DataFrame({'key1': np.arange(10),
'key2': np.random.rand(10) * 10})
print("df = \n", df)
print('-' * 200)
# count统计非Na值的数量
print("count统计非Na值的数量: df.count() = \n", df.count())
print('-' * 50)
# min统计最小值
print("min统计最小值: df.min() = \n", df.min())
print('-' * 50)
# max统计最大值
print("max统计最大值: df.max() = \n", df.max())
print('-' * 50)
# quantile统计分位数,参数q确定位置
print("quantile统计分位数,参数q确定位置: df.quantile(q=0.75) = \n", df.quantile(q=0.75))
print('-' * 50)
# sum求和
print("sum求和: df.sum() = \n", df.sum())
print('-' * 50)
# mean求平均值
print("mean求平均值: df.mean() = \n", df.mean())
print('-' * 50)
# median求算数中位数,50%分位数
print("median求算数中位数,50%分位数: df.median() = \n", df.median())
print('-' * 50)
# std求标准差
print("std求标准差: df.std() = \n", df.std())
print('-' * 50)
# var求方差
print("var求方差: df.var() = \n", df.var())
print('-' * 50)
# skew样本的偏度
print("skew样本的偏度: df.skew() = \n", df.skew())
print('-' * 50)
# kurt样本的峰度
print("kurt样本的峰度: df.kurt() = \n", df.kurt())
print('-' * 200)
打印结果:
df =
key1 key2
0 0 9.132186
1 1 2.324223
2 2 0.151036
3 3 3.802248
4 4 6.358117
5 5 1.051407
6 6 5.322711
7 7 9.895836
8 8 9.511710
9 9 9.260366
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
count统计非Na值的数量: df.count() =
key1 10
key2 10
dtype: int64
--------------------------------------------------
min统计最小值: df.min() =
key1 0.000000
key2 0.151036
dtype: float64
--------------------------------------------------
max统计最大值: df.max() =
key1 9.000000
key2 9.895836
dtype: float64
--------------------------------------------------
quantile统计分位数,参数q确定位置: df.quantile(q=0.75) =
key1 6.750000
key2 9.228321
Name: 0.75, dtype: float64
--------------------------------------------------
sum求和: df.sum() =
key1 45.000000
key2 56.809838
dtype: float64
--------------------------------------------------
mean求平均值: df.mean() =
key1 4.500000
key2 5.680984
dtype: float64
--------------------------------------------------
median求算数中位数,50%分位数: df.median() =
key1 4.500000
key2 5.840414
dtype: float64
--------------------------------------------------
std求标准差: df.std() =
key1 3.027650
key2 3.720213
dtype: float64
--------------------------------------------------
var求方差: df.var() =
key1 9.166667
key2 13.839987
dtype: float64
--------------------------------------------------
skew样本的偏度: df.skew() =
key1 0.000000
key2 -0.254827
dtype: float64
--------------------------------------------------
kurt样本的峰度: df.kurt() =
key1 -1.200000
key2 -1.637533
dtype: float64
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Process finished with exit code 0
二、参数:axis、skipna
import numpy as np
import pandas as pd
# 基本参数:axis、skipna
import numpy as np
import pandas as pd
# np.nan :空值
df = pd.DataFrame({'key1': [4, 5, 3, 1, 2],
'key2': [1, 2, np.nan, 4, 5],
'key3': [1, 2, 3, 'j', 'k']},
index=['a', 'b', 'c', 'd', 'e'])
print("df = \n", df)
print('-' * 50)
print("df['key1'].dtype = {0} \ndf['key2'].dtype = {1} \ndf['key3'].dtype = {2}".format(df['key1'].dtype, df['key2'].dtype, df['key3'].dtype))
print('-' * 200)
# .mean()计算均值【只统计数字列】【可以通过索引单独统计一列】
m1 = df.mean()
print("以列来统计(默认以列,默认忽略NaN): \nm1 = \n{0} \ntype(m1) = {1}".format(m1, type(m1)))
print('-' * 50)
# skipna参数:是否忽略NaN【默认True】,如False,有NaN的列统计结果仍为NaN
m2 = df.mean(skipna=False)
print("以列来统计(不忽略NaN): m2 = \n{0} \ntype(m2) = {1}".format(m2, type(m2)))
print('-' * 200)
# axis参数:默认为0,以列来计算,axis=1,以行来计算,这里就按照行来汇总了
m3 = df.mean(axis=1)
print("以行来统计: \nm3 = \n{0} \ntype(m3) = {1}".format(m3, type(m3)))
print('-' * 200)
# 单独统计一列
m_key2 = df['key2'].mean()
print("单独统计一列: m_key2 = df['key2'].mean() = ", m_key2)
print('-' * 200)
打印结果:
df =
key1 key2 key3
a 4 1.0 1
b 5 2.0 2
c 3 NaN 3
d 1 4.0 j
e 2 5.0 k
--------------------------------------------------
df['key1'].dtype = int64
df['key2'].dtype = float64
df['key3'].dtype = object
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
以列来统计(默认以列,默认忽略NaN):
m1 =
key1 3.0
key2 3.0
dtype: float64
type(m1) = <class 'pandas.core.series.Series'>
--------------------------------------------------
以列来统计(不忽略NaN): m2 =
key1 3.0
key2 NaN
dtype: float64
type(m2) = <class 'pandas.core.series.Series'>
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
以行来统计:
m3 =
a 2.5
b 3.5
c 3.0
d 2.5
e 3.5
dtype: float64
type(m3) = <class 'pandas.core.series.Series'>
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
单独统计一列: m_key2 = df['key2'].mean() = 3.0
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Process finished with exit code 0