《深度学习》读书笔记:第3章 概率与信息论
目录
第3章 概率与信息论
3.1 为什么要使用概率
3.2 随机变量
3.3 概率分布
3.3.1 离散型变量和概率质量函数
3.3.2 连续型变量和概率密度函数
3.4 边缘概率
3.5 条件概率
3.6 条件概率的链式法则
3.7 独立性和条件独立性
3.8 期望、方差和协方差
3.9 常用概率分布
3.9.1 Bernoulli分布
3.9.2 Multinoulli分布
3.9.3 高斯分布
3.9.4 指数分布和Laplace分布
3.9.5 Dirac分布和经验分布
3.9.6 分布的混合
3.10 常用函数的有用性质
3.11 贝叶斯规则
3.12 连续型变量的技术细节
3.13 信息论
3.14 结构化概率模型
第3章 概率与信息论
概率论是用于表示不确定性声明的数学框架。它不仅提供了量化不确定性的方法,也提供了用于导出新的不确定性声明的公理。在人工智能领域,概率论主要有两种用途:首先,概率法则告诉我们AI系统如何推理,据此我们设计一些算法来计算或者估算由概率论导出的表达式;其次,可以用概率和统计从理论上分析我们提出的AI系统的行为。
概率论使我们能够提出不确定的声明以及在不确定性存在的情况下进行推理,而信息论使我们能够量化概率分布中的不确定性总量。
3.1 为什么要使用概率
机器学习通常必须处理不确定量,有时也可能需要处理随机(非确定性的)量。
不确定性有3种可能的来源:
(1)被建模系统内在的随机性。
(2)不完全观测。即使是确定的系统,当我们不能观测到所有驱动系统行为的变量时,该系统也会呈现随机性。
(3)不完全建模。当我们使用一些必须舍弃某些观测信息的模型时,舍弃的信息会导致模型的预测出现不确定性。
在很多情况下,使用一些简单而不确定的规则要比复杂而确定的规则更为实用,即使真正的规则是确定的并且我们建模的系统可以足够精确地容纳复杂的规则。
尽管我们的确需要一种用以对不确定性进行表示和推理的方法,但是概率论并不能明显地提供我们在人工智能领域需要的所有工具。
概率可以被看做处理不确定性的逻辑扩展,逻辑提供了一套形式化的规则,可以在给定某些命题是真或假的假设下,判断另外一些命题是真的还是假的。概率论提供了一套形式化的规则,可以在给定一些命题的似然后,计算其他命题为真的似然。
3.2 随机变量
随机变量是可以随机地取不同值的变量。就其本身而言,一个随机变量只是对可能的状态的描述,它必须伴随着一个概率分布来指定每个状态的可能性。
随机变量可以是离散的或者连续的,离散随机变量拥有有限或者可数无限多的状态。
3.3 概率分布
概率分布用来描述随机变量或一簇随机变量在每一个可能取到的状态的可能性的大小。我们描述概率分布的方式取决于随机变量是离散的还是连续的。
3.3.1 离散型变量和概率质量函数
离散型变量的概率分布可以用概率质量函数来描述,我们通常用大写字母P来表示概率质量函数。概率质量函数将随机变量能够取得的每个状态映射到随机变量取得该状态的概率。
概率质量函数可以同时作用于多个随机变量,这种多个变量的概率分布被称为联合概率分布。
如果一个函数P是随机变量x的PMF,必须满足下面这几个条件:
1.P的定义域必须是x所有可能状态的集合。
2.![]() 不可能发生的事件概率为0,并且不存在比这概率更低的状态。类似地,能够确保一定发生的事件概率为1,而且不存在比这概率更高的状态。
不可能发生的事件概率为0,并且不存在比这概率更低的状态。类似地,能够确保一定发生的事件概率为1,而且不存在比这概率更高的状态。
3.![]() 我们把这条性质称为归一化的。如果没有这条性质,当我们计算很多事件其中之一发生概率时,可能会得到大于1的概率。
我们把这条性质称为归一化的。如果没有这条性质,当我们计算很多事件其中之一发生概率时,可能会得到大于1的概率。
3.3.2 连续型变量和概率密度函数
当研究的对象时连续型随机变量时,我们用概率密度函数而不是概率质量函数来描述它的概率分布。如果一个函数p是概率密度函数,必须满足下面这几个条件:
1.p的定义域必须是x所有可能状态的集合。
2.![]() 注意,我们并不要求
注意,我们并不要求![]() 。
。
3.
概率密度函数p(x)并没有直接对特定的状态给出概率,相对的,它给出了落在面积为![]() 的无限小的区域内的概率为
的无限小的区域内的概率为![]() 。
。
我们可以对概率密度函数求积分来获得点集的真实概率质量。
3.4 边缘概率
有时,我们知道了一组变量的联合概率分布,但想要了解其中一个子集的概率分布。这种定义在子集上的概率分布被称为边缘概率分布。
离散型随机变量可以依据下面的求和法则来计算P(x):

对于连续型变量,我们需要用积分替代求和:

3.5 条件概率
在很多情况下,我们感兴趣的是某个时间在给定其他事件发生时出现的概率,这种概率叫作条件概率。
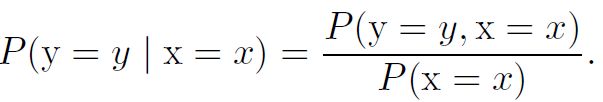
条件概率只在![]() 时有定义,我们不能计算给定永远不会发生的事件上的条件概率。
时有定义,我们不能计算给定永远不会发生的事件上的条件概率。
3.6 条件概率的链式法则
任何多维随机变量的联合概率分布,都可以分解成只有一个变量的条件概率相乘的形式:
![]()
这个规则被称为概率的链式法则或者乘法法则。
3.7 独立性和条件独立性
两个随机变量x和y,如果它们的概率分布可以表示成两个因子的乘积形式,并且一个因子只包含x,另一个因子只包含y,我们就称这两个随机变量是相互独立的:
![]()
如果关于x和y的条件概率分布对于z的每一个值都可以写成乘积的形式,那么这两个随机变量x和y在给定随机变量z时是条件独立的:
3.8 期望、方差和协方差
函数f(x)关于某分布P(x)的期望或者期望值是指,当x由P产生,f作用于x时,f(x)的平均值。
对于离散型随机变量,可以通过求和得到:

对于连续型随机变量,可以通过求积分得到:
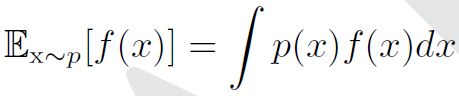
方差衡量的是当我们对x依据它的概率分布进行采样时,随机变量x的函数值会呈现多大的差异:

当方差很小时,f(x)的值形成簇比较接近它们的期望值。方差的平方根被称为标准差。
协方差在某种意义上给出了两个变量线性相关的强度以及这些变量的尺度:
![]()
协方差的绝对值如果很大,则意味着变量值变化很大,并且它们同时距离各自的均值很远。
协方差和相关性是有联系的,但实际上是不同的概念。它们是有联系的:如果两个变量相互独立,那么它们的协方差为零;如果两个变量的协方差不为零,那么它们一定是相关的。
随机向量![]() 的协方差矩阵是一个
的协方差矩阵是一个![]() 的矩阵,并且满足:
的矩阵,并且满足:
![]()
协方差矩阵的对角元是方差:
![]()
3.9 常用概率分布
3.9.1 Bernoulli分布
Bernoulli分布是单个二值随机变量的分布。它由单个参数![]() 控制,
控制,![]() 给出了随机变量等于1的概率。它具有如下的一些性质:
给出了随机变量等于1的概率。它具有如下的一些性质:

3.9.2 Multinoulli分布
Multinoulli分布或者范畴分布是指在具有k个不同状态的单个离散型随机变量上的分布,其中k是一个有限值。
Bernoulli分布和Multinoulli分布足够用来描述在它们领域内的任意分布。它们能够描述这些分布,不是因为它们特别强大,而是因为它们的领域很简单。它们可以对那些能够将所有的状态进行枚举的离散型随机变量进行建模。当处理的是连续型随机变量时,会有不可数无限多的状态,所以任何通过少量参数描述的概率分布都必须在分布上加以严格的限制。
3.9.3 高斯分布
实数上最常用的分布就是正态分布,也称为高斯分布。


当我们由于缺乏关于某个实数上分布的先验知识而不知道该选择怎样的形式时,正态分布是默认的比较好的选择,其中有两个原因。
第一,我们想要建模的很多分布的真实情况是比较接近正态分布的。中心极限定理说明很多独立随机变量的和近似服从正态分布。
第二,在具有相同方差的所有可能的概率分布中,正态分布在实数上具有最大的不确定性。
正态分布可以推广到![]() 空间,这种情况下被称为多维正态分布。它的参数是一个正定对称矩阵
空间,这种情况下被称为多维正态分布。它的参数是一个正定对称矩阵![]()

我们可以使用一个精度矩阵![]() 进行替代:
进行替代:

我们常常把协方差矩阵固定成一个对角阵。一个更简单的版本是各向同性高斯分布,它的协方差矩阵是一个标量乘以单位阵。
3.9.4 指数分布和Laplace分布
在深度学习中,我们经常会需要在x=0点处取得边界点的分布,为了实现这一目的,我们可以使用指数分布:

指数分布用指示函数![]() 来使得当x取得负值时的概率为零。
来使得当x取得负值时的概率为零。
一个联系紧密的概率分布是Laplace分布,它允许我们在任意一点u处设置概率质量的峰值:
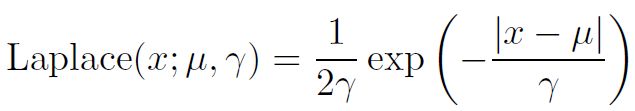
3.9.5 Dirac分布和经验分布
在一些情况下,我们希望概率分布中的所有质量都集中在一个点上。这可以通过Dirac delta函数![]() 定义概率密度函数来实现:
定义概率密度函数来实现:

Dirac分布经常作为经验分布的一个组成部分出现:

3.9.6 分布的混合
通过组合一些简单的概率分布来定义新的概率分布也是很常见的。一种通用的组合方法是构造混合分布。混合分布由一些组件分布构成。每次实验,样本是由哪个组件分布产生的取决于从一个Multinoulli分布中采样的结果:
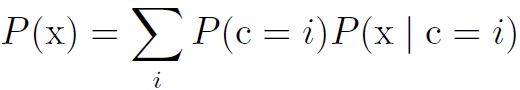
一个非常强大且常见的混合模型是高斯混合模型,它的组件![]() 是高斯分布。
是高斯分布。
3.10 常用函数的有用性质
某些函数在处理概率分布时经常会出现,尤其是深度学习的模型中用到的概率分布。其中一个函数是logisitic sigmoid函数:

sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和现象,意味着函数会变得很平,并且对输入的微小改变会变得不敏感。

另一个经常遇到的函数是softplus函数。

softplus函数名来源于它是另外一个函数的平滑(或“软化”)形式,这个函数是

softplus函数的图示:

3.11 贝叶斯规则
我们经常会需要在已知![]() 计算
计算![]() 。幸运的是,如果还知道
。幸运的是,如果还知道 ,我们可以用贝叶斯规则来实现这一目的:
,我们可以用贝叶斯规则来实现这一目的:

3.12 连续型变量的技术细节
连续型随机变量和概率密度函数的深入理解需要用到数学分支测度论的相关内容来扩展概率论,测度论提供了一种严格的方式来描述那些非常小的点集,这种集合被称为“零测度”的。
另外一个有用的测度论中的术语是“几乎处处”。某个性质如果是几乎处处都成立的,那么它在整个空间中除了一个测度为零的集合以外都是成立的。
3.13 信息论
信息论是应用数学的一个分支,主要研究的是对一个信号包含信息的多少进行量化。
信息论的基本想法是一个不太可能的事件居然发生了,要比一个非常可能的事件发生,能提供更多的信息。我们想要通过这种基本想法来量化信息,特别是:
1.非常可能发生的事件信息量要比较少,并且极端情况下,确保能够发生的事件应该没有信息量;
2.较不可能发生的事件具有更高的信息量;
3.独立事件应具有增量的信息。
为了满足上述3个性质,我们定义一个事件![]() 的自信息为:
的自信息为:

自信息只处理单个的输出,我们可以用香农熵来对整个概率分布中的不确定性总量进行量化:

如果对于同一个随机变量x有两个单独的概率分布P(x)和Q(x),可以使用KL散度来衡量这两个分布的差异:
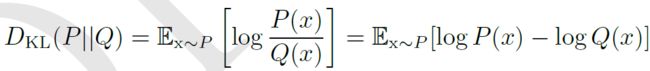
KL散度有很多有用的性质,最重要的是,它是非负的。KL散度为0,当且仅当P和Q在离散型变量的情况下是相同的分布,或者在连续型变量的情况下是“几乎处处”相同的。
3.14 结构化概率模型
当用途来表示概率分布的分解时,我们把它称为结构化概率模型或者图模型。
有两种主要的结构化概率模型:有向的和无向的。两种图模型都使用图![]() ,其中图的每个节点对应着一个随机变量,连接两个随机变量的边意味着概率分布可以表示成这两个随机变量之间的直接作用。
,其中图的每个节点对应着一个随机变量,连接两个随机变量的边意味着概率分布可以表示成这两个随机变量之间的直接作用。
有向模型使用带有有向边的图,记为

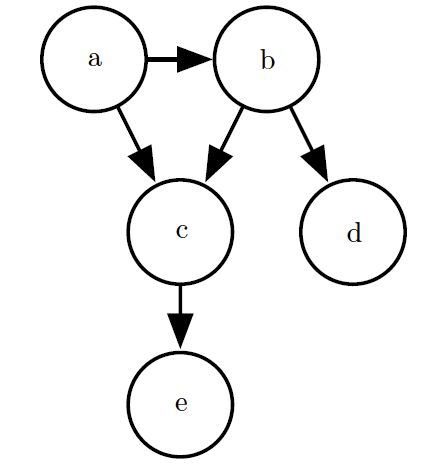

无向模型使用带有无向边的图,概率分布为:



这些图模型表示的分解仅仅是描述概率分布的一种语言。它们不是互相排斥的概率分布族。有向或无向不是概率分布的特性;它是概率分布的一种特殊描述所具有的的特性,而任何概率分布都可以用这两种方式进行描述。