全景分割调研(3) 当前研究现状
文章目录
-
- 0. 前言
- 1. 研究现状
- 2. 单篇论文笔记
-
- 2.1 Panoptic Feature Pyramid Networks
- 2.2 Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
- 2.3 Fully Convolutional Networks for Panoptic Segmentation
- 3. 论文浏览
-
- 3.1 Deeplab 系列
- 3.2 其他
- 4. 开源情况
0. 前言
- 全景分割调研系列文章分为4篇
- 问题引入与性能指标
- 常用数据集
- 当前研究现状 - 现有模型分类以及当前常见研究方向(本文)
- 本文主要内容
- 研究现状概述:介绍现在的基本研究方向
- 单篇论文笔记:介绍几个研究方向的代表论文的详细介绍
- 论文浏览:其他全景分割相关论文浏览
- 开源情况:全景分割相关开源项目简介
1. 研究现状
-
从输入数据上分,全景分割可以分为
- 基于RGB图像的全景分割,常见的数据集包括 COCO/Cityscapes/Mapillary/IDD/ADE20K 等
- 基于点云数据的全景分割,常见的包括 SemanticKITTI 等
-
基于RGB图像的全景分割算法可以分为
- box-based(主要都是 top-down 方法),thing/stuff 使用不同的 branch 预测,thing 的预测基于 box,如 PanopticFPN
- box-free(主要是 bottom-up 方法),thing/stuff 使用不同的 branch 预测,先预测 semantic再生成instance,没有用到 bbox,如 Panoptic-DeepLab
- thing/stuff 完全使用相同的结构进行预测,即 PanopticFCN/Max-Deeplab
-
其他参考资料
- 漫谈全景分割:2019.6的文章,比较详细,方法分类比较全
2. 单篇论文笔记
- 后面就分别介绍
- PanopticFPN:top-down,box-based
- Panoptic-Deeplab:bottom-up,box-free
- PanopticFCN:unified framework
2.1 Panoptic Feature Pyramid Networks
- 相关资料:
- arxiv
- github(非官方实现,使用GluonCV)
- 论文解读
- 论文基本信息
- 领域:全景分割
- 作者单位:FAIR
- 发表时间:CVPR 2019
- 一句话总结:在 Mask R-CNN(用于识别thing) 的基础上添加了一个 FCN 分支用于实现 stuff 识别。
- 要解决什么问题
- 像是对开山论文 Panoptic Segmentation 的补充。
- 在原始论文中,使用的 baseline 方法就是两个模型的叠加,没有参数共享。
- 用了什么方法
- 全景分割可以看成是语义分隔+实例分割。那一种很朴素的想法就是,在实例分割模型(Mask R-CNN)的基础上实现语义分割(就是添加一个branch)。
- 总体结构如下图,语义分割branch参考Figure3
- 后处理类似NMS,包括
- resolving overlaps between different instances based on their confidence scores,多个实例之间如果有重叠,就根据 confidence score 来进行选择
- resolving overlaps between instance and semantic segmentation outputs in favor of instances,如果实例与stuff有重叠则选择实例
- removing any stuff regions labeled ‘other’ or under a given area threshold. 删除类别为 other 的stuff,以及一些面积小于阈值的stuff。
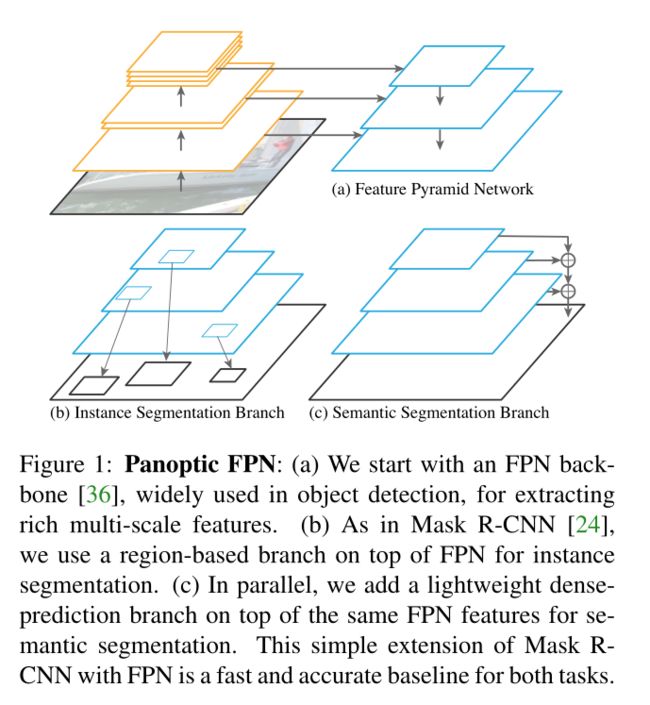

- 效果如何:本文算是全景分割领域的baseline吧,是基于 box 方法的代表作。结果也就看个热闹

- 还存在什么问题&可借鉴之处
- 这篇论文没什么能多说的,感觉只是比较直观的想法,没有太多insights。
2.2 Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
- 相关资料:
- arxiv
- github,源码2(这个backbones多一些)
- 论文解读,解读2,解读3
- 论文基本信息
- 领域:全景分割
- 作者单位:UIUC & Google
- 发表时间:CVPR 2020
- 一句话总结:提出一种基于 deeplab/bottom-up/box-free 的全景分割模型
- 要解决什么问题
- 之前全景分割主要都是 top-down 方法,例如 PanopticFCN,基本都是 two-stage 的,普遍速度比较慢。
- 用了什么方法
- 提出了 bottom-up 的方法,先语义分割,再根据分割结果获取实例。
- 整体模型如下图所示
- thing/stuff 通用了 encoder 部分
- decoder部分前面的结构都非常类似,使用了ASPP和一系列decoder(注意,decoder有skip connection)
- stuff 的最终预测就是普通的 deeplab 算法,dense prediction
- thing 的预测使用了 instance center prediction 和 instance center regression
- 这部分其实比较麻烦。
- Instance center regression 的 channels 是2,也就是每个点到对应instance中心点的偏移量。
- 那么,通过聚类我们就可以得到每个中心点对应的一组像素点,聚类结果就是该instance 的mask。
- 还有一个问题,如何获取instance的类别?在前一步聚类的时候,就是通过 semantic 的预测结果,对每一类分别进行聚类的。
- 这样得到的 instance 没有 confidence,基于 yolo 提出了一种 confidence 的计算方法。

- 效果如何:又是一个全景分割baseline,速度快

- 还存在什么问题&可借鉴之处
- 这是提出了一种解决方案,其中的 deeplab 可以通过其他语义分割模型替换。
2.3 Fully Convolutional Networks for Panoptic Segmentation
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息
- 领域:全景分割
- 作者单位:港中文&牛津&港大&旷视&思谋
- 发表时间:2021 CVPR
- 一句话总结:Panoptic FCN,提出一种可同时处理 things 和 stuff 的方法,实现真正的 end-to-end 全景分割。
- 要解决什么问题
- 全景分割的一个主要问题在于,处理things区分个体而stuff不区分个体。
- 两类任务所需的特征不太相同
- things 需要 instance-aware features,stuff 需要 semantic-aware features。
- 因此,如果公用特征图,会导致模型能下降;不公用特征图会导致模型太大,需要算力太多。
- 为了解决这种不同,之前的全景分割模型一般都是份两路,一路实现实例分割,一路实现全景分割,结果通过后处理(类似NMS)进行筛选。
- 由于有后处理的存在,所以不能完全当作是 end-to-end 的结构,且模型推理速度也因此存在瓶颈。
- 用了什么方法
- 提出了一种新的结构,如下图所示。
- 其主要组件就是:FPN +Kernel Generator + Kernel Fusion + Feature Encoder
- Kernel Generator 分为两部分
- Position Head:生成与输入特征图同尺寸(长宽)的Object Centers(things相关,由于不同的实例中心点不同,所以可以通过物体中心点来表示,channels是things类别数量)和Stuff regions(stuff相关,用来表示stuff标签,channels是stuff类别数量)
- 为了更好的计算 Position Head 的损失函数,有多种GT生成方法,比如CenterNet中的Gaussian Kernels。所有Predictions都是在0到1之间。
- Kernel Head:CoordConv + 3*Conv。
- Kernek Fusion:根据 Position Head 的结果,选择对应位置的 Kernel Head 的结果,多原始FPN中多个stage结果进行合并。设置Objects数量为M,stuff数量为N
- 最终得到的 predictions 就是 Kernel Fusion 的结果与 Feature Encoder 结果的进行矩阵乘法。
- 如何通过 Predictions 得到最终结果?
- 先通过 Kenrel Generator,获取things的中心点以及stuff的位置
- 感觉,Prediction 的每一层都是一个mask。
- 损失函数分为两部分
- Position Head 一部分 计算 pos loss,使用了 Focal Loss
- Prediction 一部分,计算 seg loss,使用了 Dice Loss

- 效果如何:结果很多就不都贴了,放一个有代表性的,本文的方法,又快又好。
- 还存在什么问题&可借鉴之处
- 这篇论文已经有 TensorRT 量化了。
- 不知道换 backbone 效果如何。
3. 论文浏览
- 前一章是重点论文阅读,现在是其他论文浏览。
3.1 Deeplab 系列
- Deeperlab
- 应该是最早的 bottoom-up 全景分割方法之一,有较好的笔记
- 使用了完整的 deeplab 结构,在最后一层后面添加了head分别预测 things 和 stuff,架构如下面第一张图
- instance 相关的head有4个,得到的是 类别不相关的 mask,后面有张图介绍
- 后面还有一个fuse过程,融合semantic和instance信息,因为instance信息是类别不相关的,就通过投票方式选择该mask对应的类别


-
Panoptic-DeepLab(CVPR 2020)
- 前文介绍过,这里总结一下。
- 对 stuff 和 thing 分两路处理。
- 每一路前面都一样,就是普通的 Deeplab 结构。
- stuff 路结尾就是普通的 deeplab 实现语义分割的结构。
- thing 路结尾预测了当前像素点是中心点的概率(center position,channels为1)以及当前像素点与他对应mask中心点的便宜(center regression,channels为2)
-
Axial-DeepLab(ECCV 2020)
- 这篇论文从内容上看,不像是直接研究全景分割,而是在研究 CNN + Self-attention 之后有了新的 module,通过全景分割来验证新 module 的确有效。
- CNN 的特点是 locality 从而达到 efficient 的要求,但这也会损失一些信息。所以现在有很多工作在研究如何优化CNN从而更好地提取 non-local 信息,一类方法就是使用 self-attention。
- 有很多工作验证 stacking attention layers as stand-alone models without any spatial convolution 能够很好的解决上面的这个问题,但这个结构存在计算量大的问题。
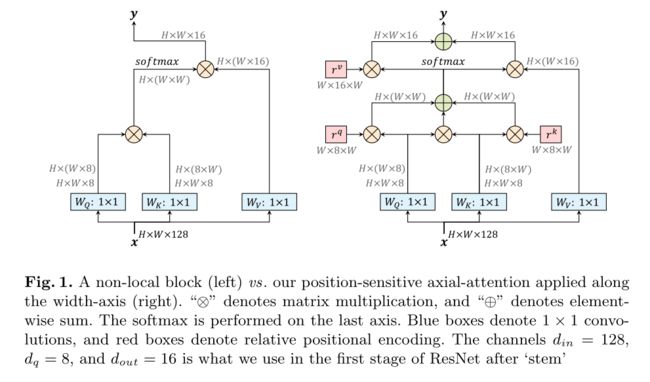
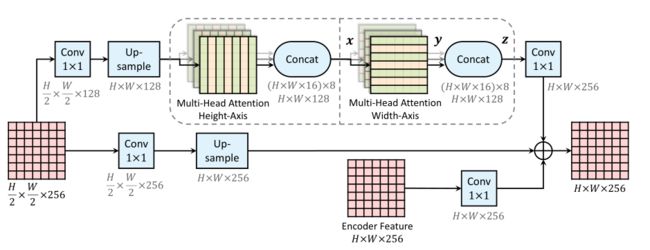
- 为了解决上面的问题,本文提出了 axial-attention,也就是将 2D attention 分解为 height/width 两个 1D attention,所谓的 axial 就是 轴 的意思,基本结构如下面第一张图所示
- 如何在 ResNet 中使用 axial-attention,修改 resnet block 结构如下面第2张图所示
- 如何在 Deeplab 中使用 axial-attention,结构如下面第3张图所示

- SWideRNet
- 本文有不错的介绍文章
- 主要就是优化 Wide-ResNet集成SE模块与SAC,这两个模块结构如下面第一张图所示
- WR以及本文提出的SWideRNet的结构如下面第二张图所示


- MaX-DeepLab(CVPR 2021)
- 本质上就是 Axial-DeepLab with a Mask Xformer,是基于 Transformer 的 End-to-End 全景分割结构(下面第一章图解释了什么是 End-to-End)
- 重新定义了全景分割,GT的形式是K个 class-labeled masks,每个mask是由c(类别标签)和 m(HxW的mask)组成的,即每个label是由 ( c i , m i ) (c_i, m_i) (ci,mi) 组成的。这样可以同时代表 stuff 和 things
- 模型输出的形式与上面提到的GT形式完全相同,生成N对 ( c i , m i ) (c_i, m_i) (ci,mi)。生成的 mask 不会有重叠:固定了mask一共只有N个,所以每个像素位置属于哪个mask的概率,累加起来是1。
- 训练过程中主要有几个问题:
- N个预测结果和K个GT如何匹配,这就涉及到两个mask相似度如何计算,以及匹配算法如何实现。
- 损失函数如何设计
- 整体网络结构使用了 CNN 与 Transformer 混用的架构,如下面第二张图所示
- 使用了 Dual-path transformer 结构,即分为两路。
- 一路为基于2D pixel-based CNN,1D global memory of size N(N是最终预测mask数量)
- 整体模型效果很好,box-free 模型第一次与 box-based 模型性能相当。

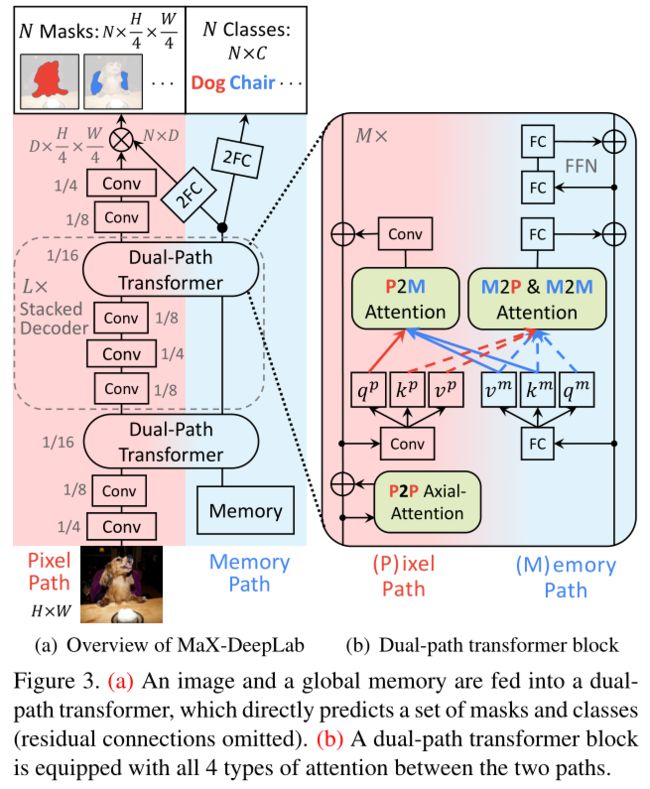
-
VIP-Deeplab
-
本文有 google 的官方介绍
-
本文的主要目标是解决视觉逆向投影问题(inverse projection problem)
- 即从一张图片中还原3D场景,3D场景包括深度信息以及全景分割信息。
- 换句话说,将上述问题转换为两个子任务:单目深度估计+视频全景分割
- 新任务取名为 Depth-aware Video Panoptic Segmentation (DVPS)
-
本文通过已有的3D点云全景分割数据集(SemanticKITTI和CityscapesVPS),经过处理,构建 DVPS 形式的数据集。
-
提出一个模型解决 CVPS 问题,即同时解决单目深度估计以及全景分割(也解决了点云全景分割),在几个子任务(KITTI 单目深度估计、Cityscapes-VPS、KITTI-MOTS)上都达到了SOTA的效果
-
所谓的Video Panoptic Segmentation(视频全景分割)如下面第一张图所示
- 输入是两张图片concat
- 语义分隔分支就是正常的预测两个结果
- center prediction分支只在前一张图上进行预测,预测结果用于两张图
- center regression 分支是在两张图上分别进行
-
模型结构其实就是在 Panoptic-Deeplab 的基础上加了一路,用于实现深度估计,如下面第二张图所示

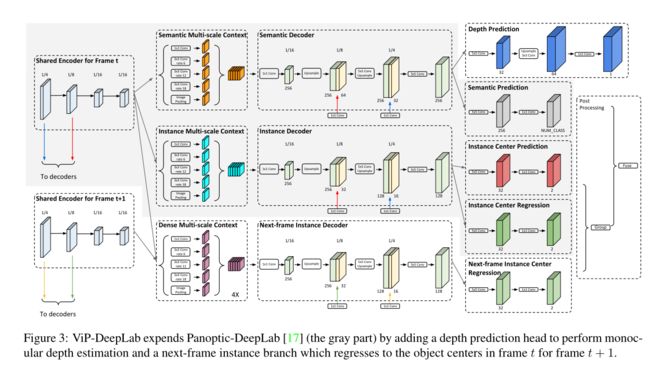
3.2 其他
- UPSNet: A Unified Panoptic Segmentation Network
- CVPR 2019,对应的repo star很多,估计是全景分割中最早开源的之一
- 基本就是在 PanopticFPN 的末尾添加 Panoptic Head,更好地融合stuff与things分支


- Attention-guided Unified Network for Panoptic Segmentation
- 即AUNet,CVPR 2019,有比较好的笔记
- 本文是在 PanopticFPN 的基础上进行优化,希望能够增加 stuff 分支和 things 分支之间的联系,添加了 RPN branch,还有一些特殊结构(如PAM/MAM)来增加两个分支之间的联系。
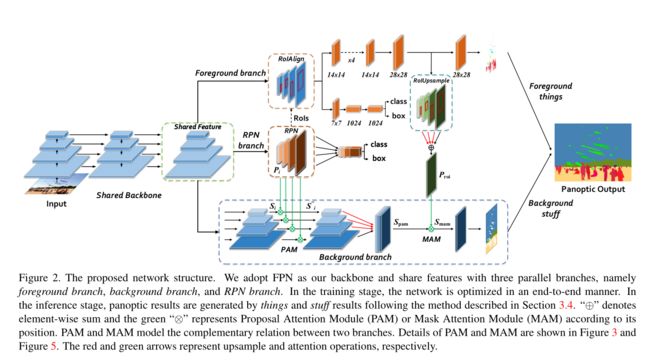
- Learning to Fuse Things and Stuff:本文主要是在 semanticFPN 的基础上,在 stuff 和 thing 分支之间添加了一个 Things and Stuff Consistency (TASC),如论文标题,就是 fuse things and stuff
- stuff的结果和things的结果应该吻合,加上这个部分能够提高稳定性和精度

-
Video Panoptic Segmentation
- CVPR 2020
- 提出了新任务 视频全景分割,在全景分割的基础上,还有跟踪功能,并给出了数据集、性能指标。
- 提出的架构还是基于 PanopticFPN 的
-
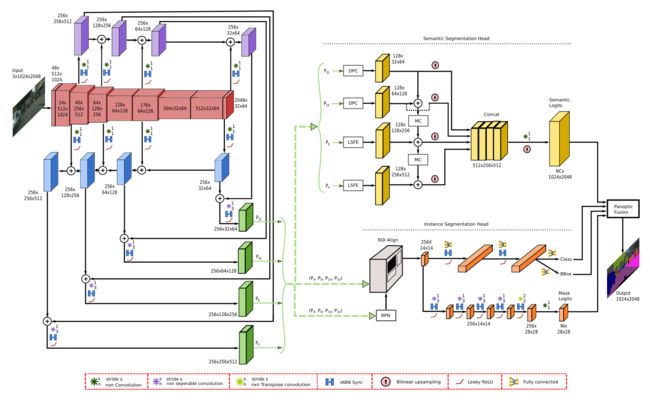
EfficientPS:top-down 的结构,感觉就是加强了 backbone 以及相关组件,并没有方法上的改进,感觉是工程上的改进。给出了一个基于 KITTI 的全景分割数据集(与SemanticKITTI不同)。
- Exemplar-Based Open-Set Panoptic Segmentation Network
- CVPR 2021
- 之前全景分割数据集基本上是闭集的,即所有像素点所属类别都是已知的。
- 但现实场景下,很多情况是开集,即不是所有类别都是在我们数据集中的。
- 本文就是解决一些开集全景分割问题。
- Panoptic Segmentation Forecasting
- CVPR 2021
- 全景分割预测问题,自动驾驶场景下可以预测未来人、车的位置
- Part-aware Panoptic Segmentation
- CVPR 2021
- 提出了 Part-aware Panoptic Segmentation,从多个纬度了解一个场景

- Cross-View Regularization for Domain Adaptive Panoptic Segmentation
- CVPR 2021 Oral
- 现有的全景分割一般都是作为监督学习进行,但实际应用场景下很少能收集到足够多的数据。
- 一种解决方案是使用生成的图片,但生成图片和真实图片差别大。
4. 开源情况
- 从调研结果看,下面三个库需要学习:
- detectron2 是全景分割中最重要的开源项目,不仅直接提供了 PanopticFPN、projects中提供了 Panoptic-Deeplab,大量其他项目也都是基于 detectron2 实现的。
- deeplab2 是另一个高质量全景分割项目,基于 TensorFlow2.5,有deeplab 系的大量全景分割模型。
- mmdetection 目前(2021.7.7)官方不支持全景分割模型,但在一个月内应该会支持 COCOPanoptic 数据集,之后应该会慢慢支持 PanopticFPN 以及更多模型。还有一些repo自己基于 mmdetection 实现了一些功能。
- 罗列开源项目(随便看了一些,感觉需要研究的就是前三个)
| 项目名称 | 相关模型 | 简介 |
|---|---|---|
| detectron2 | PnaopticFPN/Panoptic-Deeplab | FAIR 出品,非常适合二次开发,目前是全景分割领域扛把子 |
| deeplab2 | Panoptic/Axial/MaX/ViP-DeepLab | Google Research 出品,基于TensorFlow2.5,定位是提供 SOTA 的dense pixel labeling task 相关模型。非常好的项目。 |
| PanopticFCN | PanopticFCN(CVPR 2021) | 基于 Detectron2 的实现,是PyTorch目前唯一的 end2end 全景分割模型,TensorRT 加速后能达到40fps。 |
| JTSM | JTSM(CVPR 2021) | 基于Detectron2的实现 |
| UPSNet | UPSNet(CVPR 2019) | 早期工作,两年前的代码,基于 PyTorch 0.4.1,Star很多,像是前任全景分割扛把子。 |
| panoptic-deeplab | Panoptic-DeepLab | repo中建议使用 Detectron2 版代码,但这个repo中的backbone选择较多 |
| EfficientPS | EfficientPS | 基于 mmdetection,在paperswithcodes上是若干数据集的SOTA,属于还是两阶段模型,速度不快。 |
| ResNeSt | 基于ResNeSt的PanopticFPN | 基于 Detectron2 的实现,只是改backbone |
| detr | detr | 基于 detr 的全景分割,需要重新看一下 detr 论文 |
| vps | Video Panoptic Segmentation(CVPR 2020) | 基于 mmdetection 的实现 |
| Res2Net-detectron2 | 基于Res2Net的PanopticFPN | 基于 Detectron2 的实现,只是改backbone |
| AdelaiDet | blendmask | 基于 Detectron2 的实现 |
| axial-deeplab | axial-deeplab | PyTorch 复现 |
| SOGNet | SOGNet(AAAI 2020) | Innovation Award in COCO 2019 challenge,代码基于 UPSNet |
| adaptis | AdaptIS(ECCV 2019) | |
| pcv | Pixel Consensus Voting (CVPR 2020) | |
| boundary-iou-api | Boundary IoU API(CVPR 2021) | 感觉不是改模型,而是提出新的IoU计算方法,没有提供模型相关源码,只是修改了 COCO/Cityscapes 相关的API |
| DS-Net | DS-Net(CVPR 2021) | 基于点云的全景分割,当前 SemanticKITTI 的SOTA |
| ViP-DeepLab | ViP-Deeplab | 同时进行单目深度估计以及视频语义分割,每个子任务都能达到SOTA |