本周AI热点回顾:百度NLP开源语言与视觉一体的统一模态预训练方法,登顶各类榜单;用一张草图创建GAN模型,新手也能玩转...
点击左上方蓝字关注我们

01
ACL 2021 | 百度NLP开源语言与视觉一体的统一模态预训练方法,登顶各类榜单
百度首创地提出了语言与视觉一体的预训练方法 UNIMO,提供了一种新的统一模态学习范式,打破了文本、图像和图文对等数据间的边界,让机器可以像人一样利用大规模异构模态数据,学习语言知识与视觉知识并相互增强,从而实现感知与认知一体的通用 AI 能力。
百度在 2021 年深度学习开发者峰会 WAVE SUMMIT 上开源了语言与视觉一体的预训练模型 ERNIE-UNIMO,其核心方法 UNIMO 已经被 NLP 顶级会议 ACL 2021 主会正式录用为 oral 长文。
在机器之心 7 月 31 日举办的 ACL 2021 论文分享会上,本文第一作者李伟详细介绍了他们的这项研究成果,感兴趣的同学可以点击阅读原文查看回顾视频。
AI 系统能否像人一样,使用一个统一的大脑模型,实现感知认知一体的通用能力?基于此出发点,百度提出的 UNIMO 试图构建面向各种不同模态的统一预训练模型。

论文地址:https://arxiv.org/abs/2012.15409
代码地址:https://github.com/PaddlePaddle/ERNIE/tree/develop/ernie-unimo
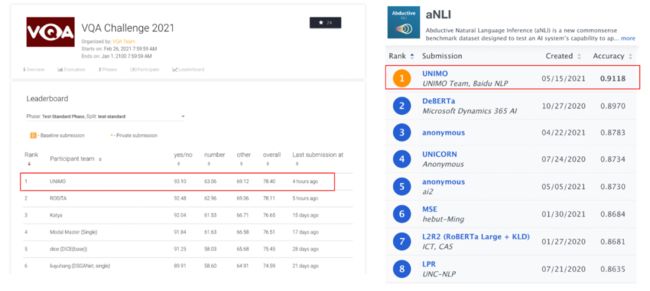
此方法首创的同时还能学习大量的文本、图像、图文对数据,通过跨模态对比学习,有效的让语言知识与视觉知识进行统一表示和相互增强。UNIMO 在语言理解与生成、跨模态理解与生成,4 类场景共 13 个任务上超越主流的文本预训练模型和跨模态预训练模型,同时登顶视觉问答榜单 VQA、文本推理榜单 aNLI 等权威榜单,首次验证了通过非平行的文本与图像等单一模态数据,能够让语言知识与视觉知识相互增强。目前 UNIMO 已经逐步在百度的产品中落地应用。
信息来源:机器之心
02
ACL2021 | 多粒度输入信息不降低推理速度,高效预训练方法LICHEE
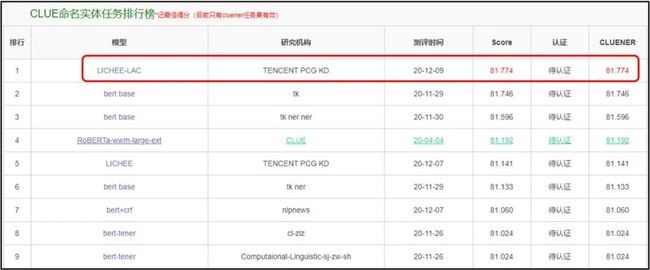
既能利用多粒度输入信息,又不降低推理速度,某机构的研究者在一篇 ACL 论文中提出了一种高效的语言模型预训练方法荔枝 LICHEE。经过半年多的摸索改进,荔枝 LICHEE 同时登顶 CLUE 分类榜单、阅读理解榜单、总榜单,其相关的技术创新也被 ACL 2021 录用。
基于大型语料库的语言模型预训练在构建丰富的上下文表示方面已经取得了巨大的成功,也在一系列自然语言理解任务中实现了显著的性能提升。然而,现有的预训练语言模型(如 BERT)大多是基于单粒度训练而成的,通常伴随细粒度的字符或 sub-word,这使其很难学习粗粒度词汇和短语的准确含义 。
为了得到更加准确的模型,部分研究者试图通过在预训练阶段 mask 连续 token 的序列,将粗粒度信息纳入到用细粒度分词训练的模型中。还有研究者提出了一种可以处理多粒度输入文本的模型——AMBERT。它利用两个具有共享权重的编码器将细粒度 token 和粗粒度 token 分别编码为两个上下文表示序列。虽然 AMBERT 效果不错,但它的推理成本却比原始 BERT 高了一倍左右,这在业界的很多场景下都是不可接受的。
为了得到更加准确的模型,主要的研究方向分为两类:
在 MASK 层引入粗粒度信息,如 whole word mask 或者 ERNIE 1.0;
在嵌入层引入粗粒度信息,如 ZEN 何 AMBert。
前者的好处是不需要修改模型,只需要在数据预处理阶段对整个词做连续 mask 就好,缺点是没有充分使用文本中的词信息(没有 mask 的词依然会使用字粒度)。后面的 ERINIE-gram 直接把词作为整体进行预测,会导致最后 softmax 层效率极大降低,导致训练周期变长。后者的好处是充分使用了全文的词信息,但是缺点是引入了额外的计算逻辑,导致效率降低。以 AMBERT 为例,它利用两个具有共享权重的编码器将细粒度 token 和粗粒度 token 分别编码为两个上下文表示序列。虽然 AMBERT 效果不错,但它的推理成本却比原始 BERT 高了一倍左右,这在业界的很多场景下都是不可接受的。
在这篇 ACL 论文中,来自某机构和阿尔伯塔大学的研究者提出了一种简单但高效的预训练方法——荔枝 LICHEE。该方法可以在预训练阶段有效利用多种粒度的输入信息来增强预训练语言模型(PLM)的表示能力。

论文链接:https://arxiv.org/pdf/2108.00801.pdf
与 AMBERT 不同的是:AMBERT 利用两个编码器编码细粒度和粗粒度 token,这使得推理成本大大增加;但在 LICHEE 中,输入文本的多粒度信息融合发生在嵌入层,不需要改变 PLM 原有的模型结构,因此几乎不会带来额外的推理开销。
具体来说,LICHEE 首先会将输入文本处理成细粒度和粗粒度 token。然后,这些 token 会被传送到两个嵌入层,生成对应的向量表示。接下来,两种向量表示通过池化操作进行融合,形成多粒度嵌入向量,作为 PLM 编码器的输入。最后,我们得到由 PLM 编码器生成的增强上下文表示(包含细粒度和粗粒度信息)并将其用于下游任务。
在 CLUE 和 SuperGLUE 上进行的实验表明,该方法在中、英两种语言的多个自然语言理解任务中都能带来全面的性能提升,而且几乎不增加额外的推理成本。采用该方法的最优集成模型在 CLUE 基准上实现了 SOTA 性能。
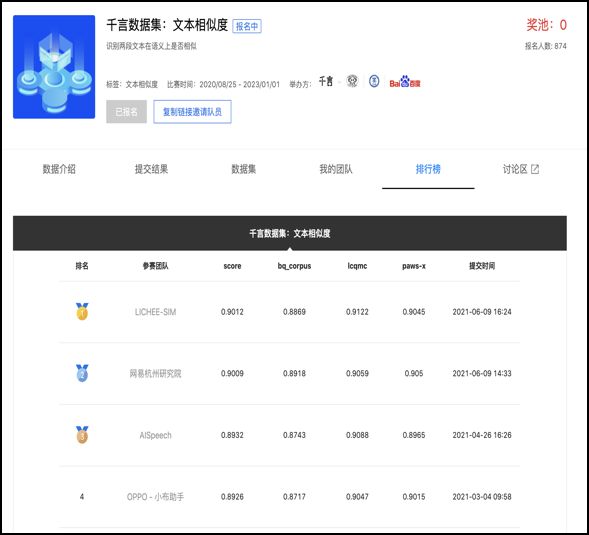
此外,使用荔枝做特征抽取器,在词法分析任务 CLUENER 和千言数据集文本相似度任务上取得了超越其他模型的结果。
信息来源:机器之心
03
PaddleOCR新发版v2.2:开源版面分析与轻量化表格识别
时隔数月之后PaddleOCR发版v2.2,又带着新功能和大家见面了。本次更新,为大家带来最新的版面分析与表格识别技术:PP-Structure。核心功能点如下:
支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
支持表格区域进行结构化分析,最终结果输出Excel文件
支持Python whl包和命令行两种方式,简单易用
支持版面分析和表格结构化两类任务自定义训练
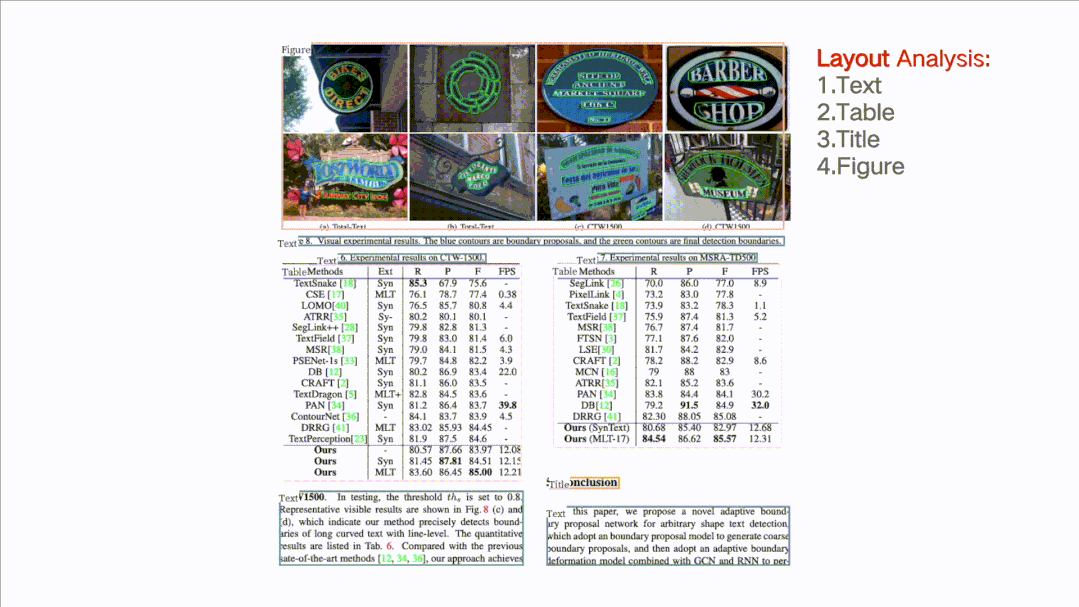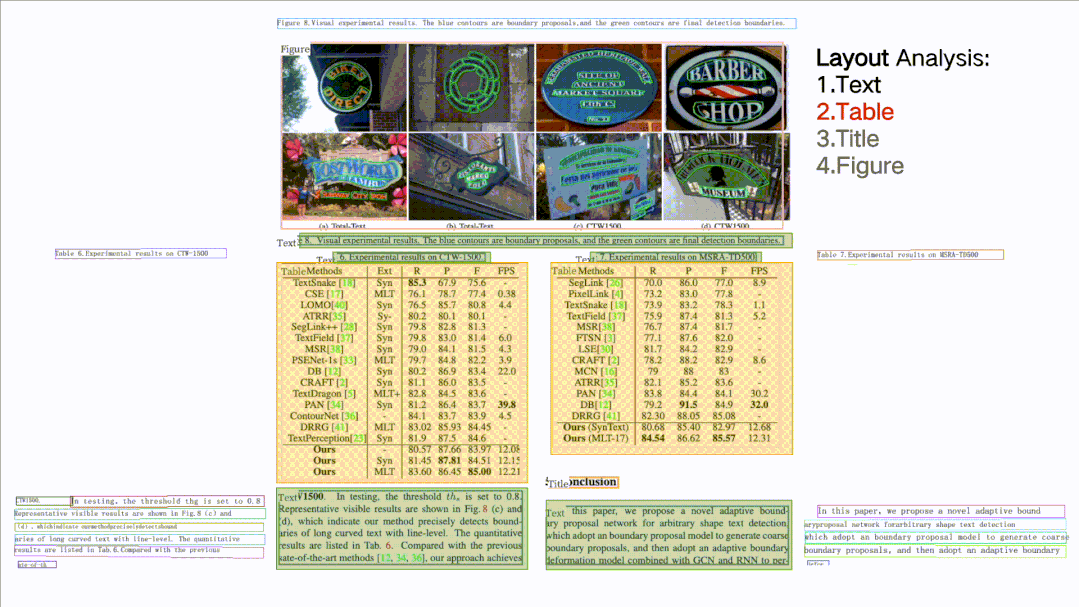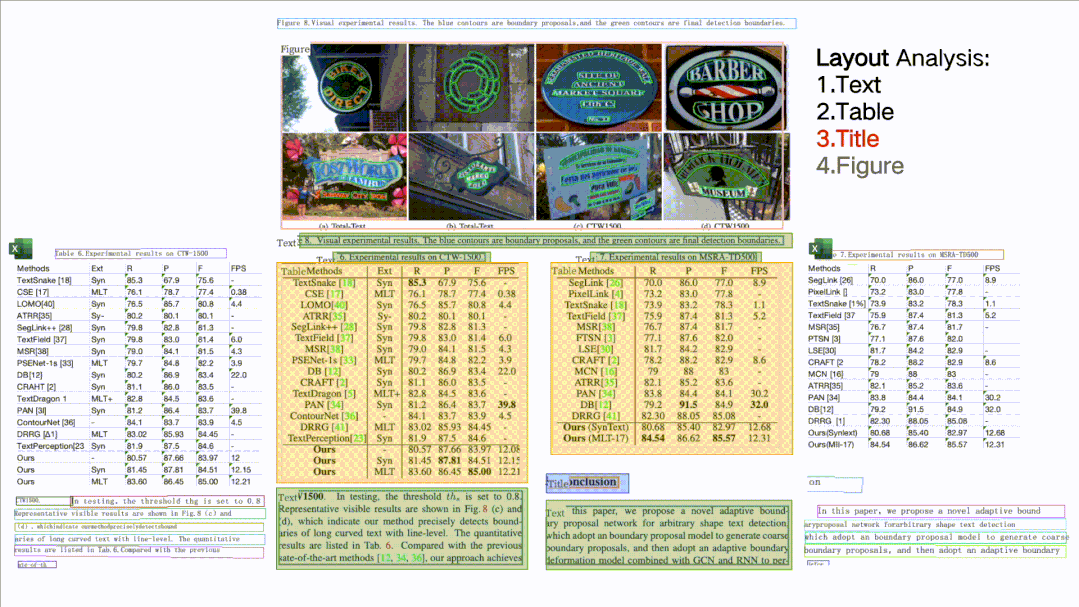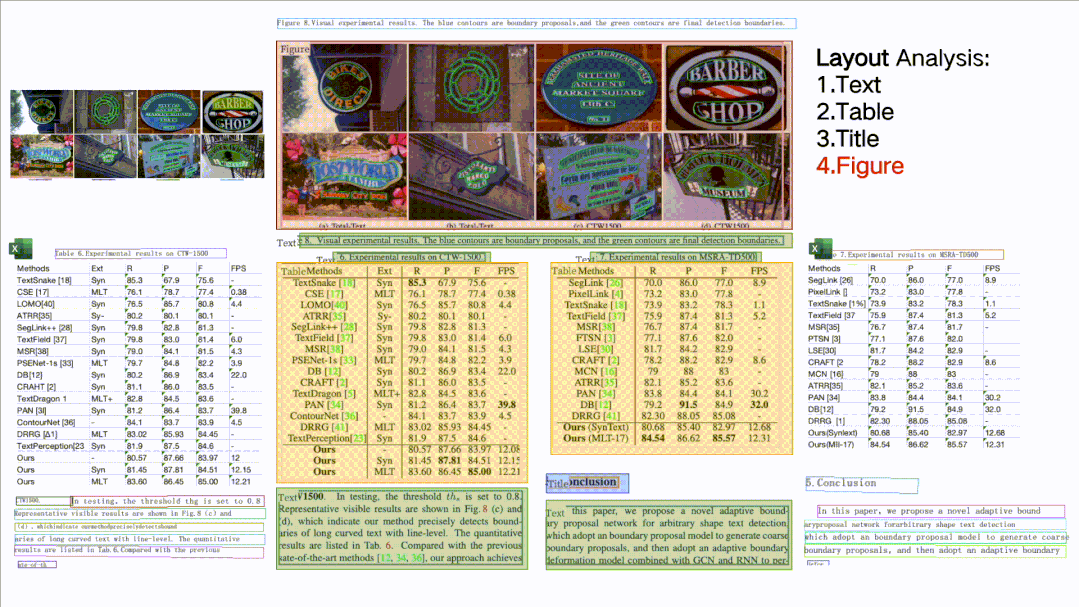
所谓版面分析,就是对文档图片中的文本、表格、图片、标题与列表区域进行分类。而表格识别则是基于版面分析出的表格类区域,进行文本的检测与识别,同时还完整的提取表格结构信息,使得表格图片变为可编辑的Excel文件。
PP-Structure的使用也是非常方便,在完成Python whl包安装之后,简单代码即可完成快速试用。
详细文档,请参考:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
信息来源:飞桨PaddlePaddle
04
用一张草图创建GAN模型,新手也能玩转,朱俊彦团队新研究入选ICCV 2021
CMU 助理教授朱俊彦团队的最新研究将 GAN 玩出了花,仅仅使用一个或数个手绘草图,即可以自定义一个现成的 GAN 模型,进而输出与草图匹配的图像。相关论文已被 ICCV 2021 会议接收。
深度生成模型(例如 GAN)强大之处在于,它们能够以最少的用户努力合成无数具有真实性、多样性和新颖的内容。近年来,随着大规模生成模型的质量和分辨率的不断提高,这些模型的潜在应用也不断的在增长。
然而,训练高质量生成模型需要高性能的计算平台,这使得大多数用户都无法完成这种训练。此外,训练高质量的模型还需要收集大规模数据以及复杂的预处理过程。常用的数据集(例如 ImageNet 、LSUN)需要人工标注和过滤;而专用的数据集 FFHQ Face 需要进行人脸对齐以及超分辨率预处理。此外,开发一个高级生成模型需要一组专家的领域知识,他们通常会在特定数据集的单个模型上投入数月或数年的时间,耗时较长。
这就引出了一个问题:普通用户如何创建自己的生成模型?比如,用猫来创造艺术作品的用户可能不愿意使用普通的猫模型,而希望是一种特殊猫的定制模特,摆着特定的姿势:在附近、斜倚着,或者都向左看。一般来说,要获得这样的定制模型,用户必须管理成千上万的向左倾斜的猫图像,然后需要领域专家花几个月的时间进行模型训练和参数调整,才能生成一个较为理想的模型。
在这项工作中,朱俊彦等来自 CMU 和 MIT 的研究者提出 GAN Sketching,该方法通过一个或多个草图重写 GAN,让新手用户更容易地训练 GAN。具体地,该方法还能通过用户草图改变原始 GAN 模型的权重,并且通过跨域(cross-domain )对抗损失鼓励模型输出来匹配用户草图。
此外,该研究还探索了不同的正则化方法,以保持原始模型的多样性和图像质量。

论文地址:https://arxiv.org/pdf/2108.02774.pdf
项目地址:https://peterwang512.github.io/GANSketching
它的效果是这样的:绘制一张猫咪草图,模型会匹配与草图神似的猫咪图片:
信息来源:机器之心
05
好家伙!B站竟然开源了一个Dota2 AI项目:影魔SOLO智能体
为什么 Dota 里大家喜欢杀影魔?
Dota 2 的人工智能击败人类,是 AI 界的一次里程碑事件。2019 年 4 月,OpenAI 提出的 AI 智能体「OpenAI Five」击败 OG 成为了第一个在电竞游戏中击败世界冠军的 AI 系统。
作为一款 MOBA(多人在线战术竞技)游戏,Dota 2 不仅人气很高,还对人工智能,特别是强化学习系统的研究提出了很多挑战,例如游戏时间跨度长,信息不完善及高度复杂,连续的状态动作空间。所有这些问题,对于功能完善的 AI 系统在真实世界中的应用至关重要。
既然游戏是训练 AI 的好环境,那自然就会有不少科技公司前来尝试,除了 OpenAI 以外,这些年里我们还看到过很多的游戏 AI 项目,如 DeepMind 打星际争霸、腾讯王者荣耀的「绝悟」、快手的斗地主 AI。
不过两天前刚刚开源的一个 AI 项目是我们万万没想到的,小破站 Bilibili 竟然开源了一个强化学习训练的 Dota2 影魔 solo 智能体。
B 站这个项目叫 Last Order Dota2 Solo AI,虽然并非原创性的游戏 AI 研究,且当前只有 65 个 star 量,但我们还是想感叹一句:出息了啊!
项目链接:https://github.com/bilibili/LastOrder-Dota2
信息来源:机器之心
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
