sklearn学习之:(6)sklearn 自动生成数据集用法: make_blobs, make_classification, make_gaussian-quantiles
文章目录
- 一、sklearn.datasets.make_blobs
-
- 1. 产生随机数据
- 2. 数据可视化
- 3. 代码
- 二、sklearn.datasets.make_classification
-
- 1. 产生分类数据
- 2. 可视化方法验证数据是否符合正态分布
- 3. 通过 scipy 库来验证数据是否符合正态分布
- 4. 画出两个特征下的二分类原数据可视化结果
- 5. 代码(只使用两个特征的情况)
- 三、sklearn.datasets.make_gaussian-quantiles
-
- 1. 产生数据并验证其正态性
- 2. 可视化数据
- 3. 代码
一、sklearn.datasets.make_blobs
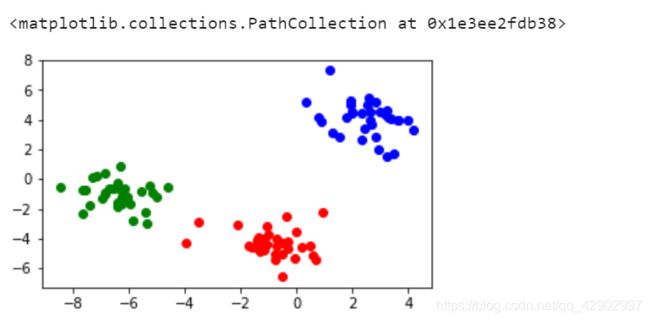
1. 产生随机数据
产生多类单标签数据集,为每个类分配一个或多个正态分布的点集,为测试聚类算法而使用的
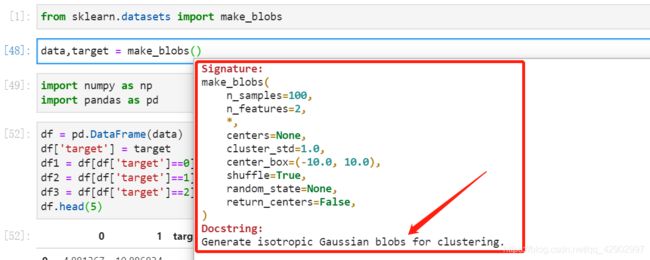

- 产生的默认特征 n_features 是两种,0 和 1
- 产生的默认种类是 3 个(center=3)
- 产生的默认样本是 100 个
2. 数据可视化
提取一下每个类的点集,并且可视化一下:
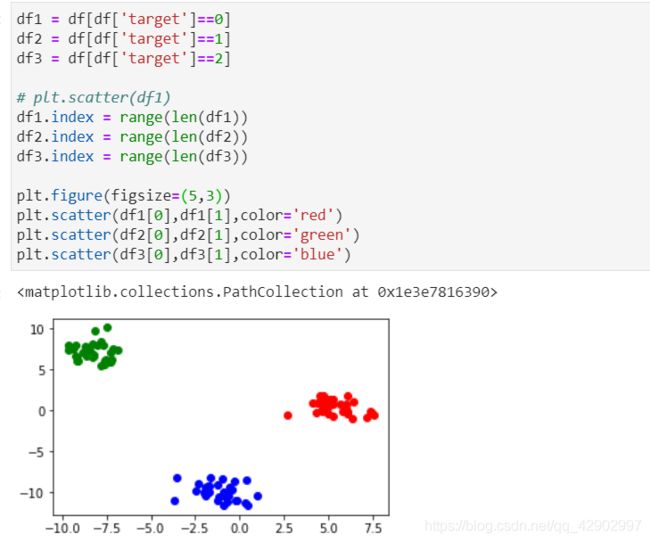
3. 代码
from sklearn.datasets import make_blobs
import numpy as np
import pandas as pd
data,target = make_blobs()
df = pd.DataFrame(data)
df['target'] = target
df1 = df[df['target']==0]
df2 = df[df['target']==1]
df3 = df[df['target']==2]
# plt.scatter(df1)
df1.index = range(len(df1))
df2.index = range(len(df2))
df3.index = range(len(df3))
plt.figure(figsize=(5,3))
plt.scatter(df1[0],df1[1],color='red')
plt.scatter(df2[0],df2[1],color='green')
plt.scatter(df3[0],df3[1],color='blue')
二、sklearn.datasets.make_classification
多类单标签数据集,为每个类分配一个或多个正太分布的点集,提供了为数据添加噪声的方式,包括维度相关性,无效特征以及冗余特征等

1. 产生分类数据


2. 可视化方法验证数据是否符合正态分布
- 只验证一下
df1(标签为0)的数据中的第一列的数据是否符合正态分布

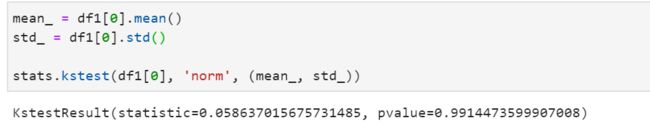
3. 通过 scipy 库来验证数据是否符合正态分布
scipy中的ks-test方法可以用来检测是否符合正态分布pvalue > 0.05就是正态分布

4. 画出两个特征下的二分类原数据可视化结果

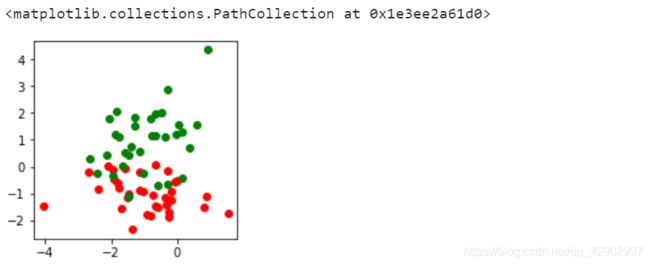
5. 代码(只使用两个特征的情况)
- 修改
make_classification里面的参数即可
'''
make_classification
'''
from sklearn.datasets import make_classification
import numpy as np
import pandas as pd
from scipy import stats
data, target = make_classification(n_features=2,n_classes=3,n_clusters_per_class=1,n_redundant=0)
df = pd.DataFrame(data)
df['target'] = target
df1 = df[df['target']==0]
df2 = df[df['target']==1]
df1.index = range(len(df1))
df2.index = range(len(df2))
plt.figure(figsize=(3,3)) # 画出数据集的数据分布
plt.scatter(df1[0],df1[1],color='red')
plt.scatter(df2[0],df2[1],color='green')
plt.figure(figsize=(6,2))
df1[0].hist()
df1[0].plot(kind = 'kde', secondary_y=True)
mean_ = df1[0].mean()
std_ = df1[0].std()
stats.kstest(df1[0], 'norm', (mean_, std_))
三、sklearn.datasets.make_gaussian-quantiles

将一个单高斯分布的点集划分为两个数量均等的点集,作为环形数据来验证模型分类效果
1. 产生数据并验证其正态性

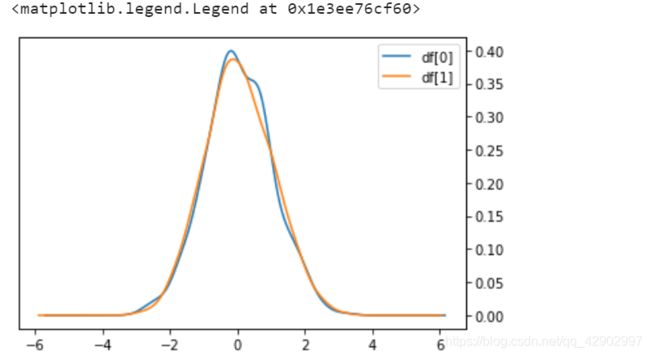
- 两个特征都完全符合正态分布
2. 可视化数据

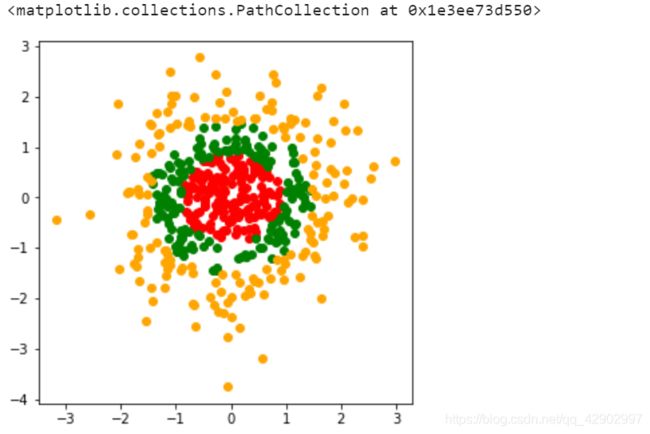
3. 代码
from sklearn.datasets import make_gaussian_quantiles
import numpy as np
import pandas as pd
data, target = make_gaussian_quantiles(n_samples=500)
df = pd.DataFrame(data)
df['target'] = target
df[0].plot(kind='kde',secondary_y=True,label='df[0]')
df[1].plot(kind='kde',secondary_y=True,label='df[1]')
plt.legend()
df1 = df[df['target']==0]
df2 = df[df['target']==1]
df3 = df[df['target']==2]
df1.index = range(len(df1)) # 调整行索引(养成良好的数据处理习惯)
df2.index = range(len(df2))
df3.index = range(len(df3))
plt.figure(figsize=(5,5))
plt.scatter(df1[0],df1[1],color='red')
plt.scatter(df2[0],df2[1],color='green')
plt.scatter(df3[0],df3[1],color='orange')