SpringBoot日志文件
文章目录
- 日志有什么作用?
- SpringBoot 的日志
- 日志级别
-
- 日志级别的分类
- 自定义日志
-
- 在程序中得到日志对象
- 使用日志对象打印日志
- 日志级别设置
- 日志持久化
- 更简单的日志输出—lombok
日志有什么作用?
日志是程序的重要组成部分,想象⼀下,如果程序报错了,不让你打开控制台看日志,那么你能找到报错的原因吗?
答案是否定的,写程序不是买彩票,不能完全靠猜,因此日志对于我们来说,最主要的用途就是排除和定位问题。
除了发现和定位问题之外,我们还可以通过日志实现以下功能:
- 记录用户登录日志,方便分析用户是正常登录还是恶意破解用户
- 记录系统的操作日志,方便数据恢复和定位操作人
- 记录程序的执行时间,方便为以后优化程序提供数据支持
以上这些都是日志提供的非常实用的功能
SpringBoot 的日志
Spring Boot 项目在启动的时候默认就有日志输出,如下图所示:

以上内容就是 Spring Boot 输出的控制台日志信息。
通过上述日志信息我们能发现以下4个问题:
- Spring Boot 内置了日志框架(不然也输出不了日志)
- 打印的日志不仅有时间,还有日志等级,线程id以及日志信息来自哪个类
- 默认情况下,输出的日志并非是开发者定义和打印的,那开发者怎么在程序中自定义打印日志呢?
- 日志默认是打印在控制台上的,而控制台的日志是不能被保存的,那么怎么把日志永久的保存下来呢?
日志级别
日志的级别就是为了筛选符合目标的日志信息的。试想⼀下这样的场景,假设你⼀家 2 万⼈公司的⽼板,那么每⼈员工的日常工作和琐碎的信息都要反馈给你吗?⼀定不会,因为你根本没有那么多经历。于是就有了组织架构,而组织架构就会分级,有很多的级别设置,如下图所示:

有了组织架构之后,就可以逐级别汇报消息了,例如:组员汇报给组长;组长汇报给研发⼀组;研发一组汇报给 Java 研发,等等依次进行汇报
而日志分级大概的道理也是⼀样的,有了日志级别之后就可以过滤自己想看到的信息了,比如设置日志级别为 error,那么就可以只看程序的报错日志了,对于普通的调试日志和业务日志就可以忽略了,从而节省开发者的信息筛选时间
日志级别的分类
日志的级别分为:
- trace:微量,少许的意思,级别最低
- info:普通的打印信息
- debug:需要调试时候的关键信息打印
- warn:警告,不影响使⽤,但需要注意的问题
- error:错误信息,级别较⾼的错误日志信息
- fatal:致命的,因为代码异常导致程序退出执行的事件
日志级别的顺序:
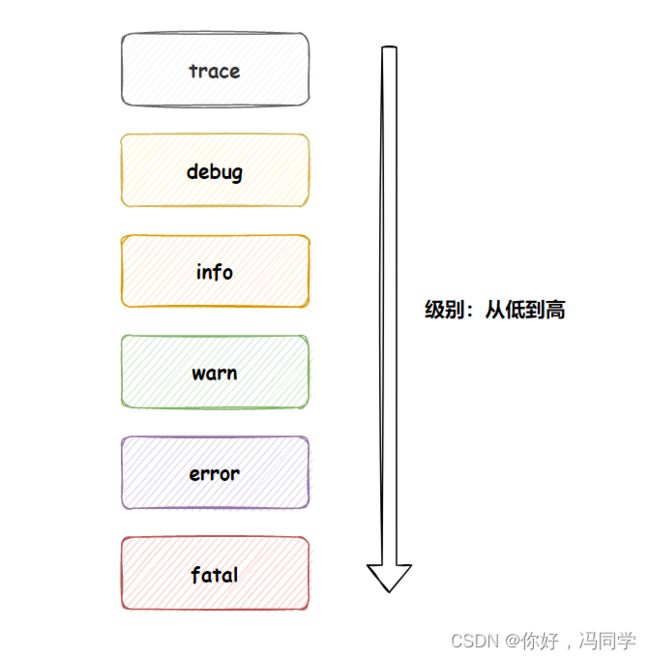
越往上接收到的消息就越少
自定义日志
开发者自定义打印日志的实现步骤:
- 在程序中得到日志对象
- 使用日志对象的相关语法输出要打印的内容
在程序中得到日志对象
在程序中获取日志对象需要使用日志工厂 LoggerFactory,如下代码所示:
先得到日志对象(来自slf4j)
private final static Logger log =
LoggerFactory.getLogger(UserController.class);//设置当前类的类型,打印日志的时候,就会把类信息带上
日志工厂需要将每个类的类型传递进去,这样我们才知道日志的归属类,才能更方便、更直观的定位到问题类
注意:Logger 对象是属于 org.slf4j 包下的,不要导入错包

因为 Spring Boot 中内置了日志框架 Slf4j,所以咱们可以直接在程序中调用 slf4j 来输出日志
使用日志对象打印日志
将所有级别的日志都打印一遍:
@Controller
@ResponseBody
public class UserController {
//1.先得到日志对象(来自slf4j)
private final static Logger log =
LoggerFactory.getLogger(UserController.class);//设置当前类的类型,打印日志的时候,就会把类信息带上
@RequestMapping("/sayhi") //设置路由
public void sayHi() {
log.trace("我是 trace");
log.debug("我是 debug");
//上述两个日志信息,控制台看不到,因为只能看到日志等级>=info的日志
log.info("我是 info");
log.warn("我是 warn");
log.error("我是 error");
}
}

结果我们发现 trace 和 debug 的日志信息并没有被打印,这是为什么呢?
这就是日志级别的问题了,SpringBoot的默认日志级别是 info,也就是说只有日志级别大于等于 info 的才会被输出,否则将会被过滤掉,后面将讲到如何设置日志级别
除此之外,我们并没有写 log.fatal(“我是 fatal”)
实际上,slf4j 的日志方法中,并没有这个方法,因为该日志级别是系统输出的日志,不能自定义打印
在获取日志对象时,如果不填写当前类(不设置参数),那么结果会是怎么样呢?
private final static Logger log = LoggerFactory.getLogger("");

结果并没有当前类的信息,因此我们在获取日志对象时,一定要填写当前类,否则在查看日志信息时,就不知道是哪个类打印的
日志级别设置
日志级别配置只需要在配置文件(.properties 或者 .yml)中设置“logging.level”配置项即可
例如,将全局的日志级别设置为 trace:
# 设置全局的日志级别为trace
logging.level.root=trace
此时 trace 和 debug 级别的日志都将被打印,说明全局日志配置已经成功
如果同时设置全局日志级别和局部日志级别时,那么最终的日志级别以局部为主,也就是说局部日志级别优先级 > 全局日志级别,例如:
# 设置全局的日志级别为trace
logging.level.root=trace
# 设置局部文件夹的日志级别
logging.level.com.example.demo=trace

日志持久化
之前的日志信息都是稍纵即逝的,每次重新启动 SpringBoot 项目时,上一次在控制台显示的日志信息将全部失去,这种情况在生产环境是不允许的。在生产环境上咱们需要将日志保存下来,以便出现问题之后追溯问题,把日志永久的保存到磁盘的某个位置的过程就叫做持久化。
想要将日志进行持久化,只需要在配置⽂件中指定日志的存储目录或者是指定日志保存文件名之后,
Spring Boot 就会将控制台的日志写到相应的目录或文件下了。
配置日志文件的保存路径:
# 配置⽇志⽂件的⽬录
logging.file.path= B:\\javatestdemo\\SpringBoot-2
# 单个反斜杠会存在转义,所以要写两个反斜杠
# 除此之外,还能写成Linux下的斜杠路径分隔符
# logging.file.path=B:/javatestdemo/SpringBoot-2

spring.log是默认的名字
配置日志文件的文件名:
# 配置日志文件的文件名
logging.file.name=B:\\javatestdemo\\SpringBoot-2\\SpringBoot.log
# 单个反斜杠会存在转义,所以要写两个反斜杠
# 除此之外,还能写成Linux下的斜杠路径分隔符
# logging.file.name=B:/javatestdemo/SpringBoot-2/SpringBoot.log
通常情况下,无论是哪种方式,我们都是指定绝对路径,而不是相对路径
通常情况下,日志的默认情况下是进行追加,而不是覆盖
设置日志的大小:
logging.logback.rollingpolicy.max-file-size=10MB
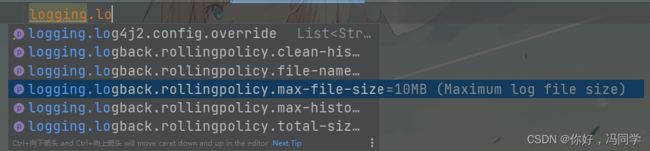
日志的默认大小就是10MB。日志不能太大,如果几个GB,堪比一场超清电影,难以查看。日志太小也会导致有大量的日志文件,难以查看
更简单的日志输出—lombok
每次都使用 LoggerFactory.getLogger(xxx.class) 很繁琐,且每个类都添加⼀遍,也很麻烦,因此 lombok 给我们提供了更简单,更好用的日志输出方式。
使用之前必须将 lombok 添加到当前项目
添加 @slf4j 注解即可,其他写法都一样
@Slf4j
@Controller
@ResponseBody
public class UserController {
@RequestMapping("/sayhi") //设置路由
public void sayHi() {
log.trace("我是 trace");
log.debug("我是 debug");
//上述两个日志信息,控制台看不到,因为只能看到日志等级>=info的日志
log.info("我是 info");
log.warn("我是 warn");
log.error("我是 error");
}
}
日志打印结果:

为什么我们加了注解之后就能实现这样一个功能呢?
lombok原理
lombok 能够打印日志的密码就在 target 目录里面,target 为项目最终执行的代码,查看 target 目录如
下:
JVM能识别的是字节码文件,而非源代码,看一下 UserController 的源代码:

在这个字节码文件中,并没有 @slf4j,却多了一条获取日志对象的代码,原因就是源代码进行编译成字节码文件时,会将对应的注解替换成对应的代码
Lombok 的作用如下图所示:
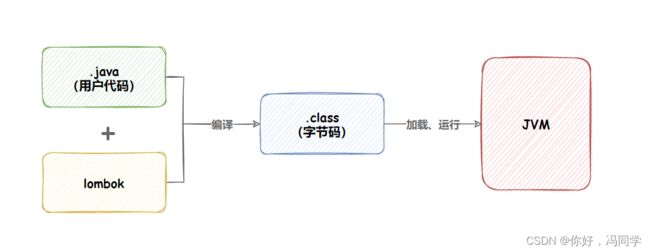
lombok 更多注解说明
基本注解
| 注解 | 作用 |
|---|---|
| @Getter | 自动添加 getter 方法 |
| @Setter | 自动添加 setter 方法 |
| @ToString | 自动添加 toString 方法 |
| @EqualsAndHashCode | 自动添加 equals 和 hashCode 方法 |
| @NoArgsConstructor | 自动添加无参构造方法 |
| @AllArgsConstructor | 自动添加全属性构造方法,顺序按照属性的定义顺序 |
| @NonNull | 属性不能为 null |
| @RequiredArgsConstructor | 自动添加必需属性的构造方法,final + @NonNull 的属性为必需 |
组合注解
| 注解 | 作用 |
|---|---|
| @Data | @Getter + @Setter + @ToString + @EqualsAndHashCode + @RequiredArgsConstructor + @NoArgsConstructor |
日志注解
| 注解 | 作用 |
|---|---|
| @Slf4j | 添加⼀个名为 log 的日志,使用 slf4j |