传统语音增强——基本谱减法
一、基本谱减法的概念
设语音信号的时间序列为x(n),加窗分帧处理后得到第i帧语音信号为x(m),帧长为
N。任何一帧语音信号x(m)做FFT后为
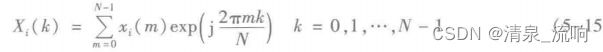
对Xi(k)求出每个分量的幅值和相角,幅值是|Xi(k)|,相角为
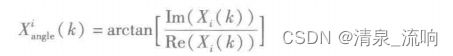
已知前导无话段(噪声段)时长为IS,对应的帧数为NIS,可以求出该噪声段的平均能量为
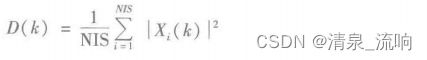
谱减公式为
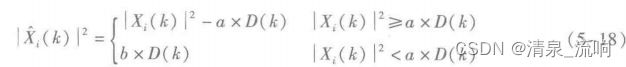
式中,a和b是两个常数,a称为过减因子;b称为增益补偿因子。
整个算法的原理下图所示:
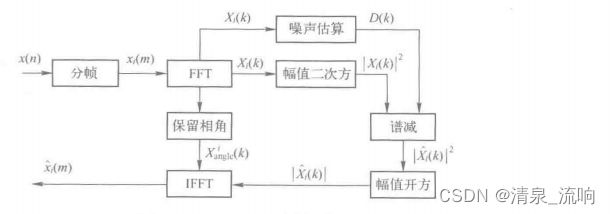
二、基本谱减法的实验
信噪比计算函数SNR_Calc
名称:SNR_Calc
功能:计算信噪比。
调用格式:
snr=SNR_Calc(x,xn)
说明:输入信号x是输入的纯净语音信号;xn是输入的含噪信号。输出参数snr是计算的信噪比。
函数程序如下:
function snr=SNR_Calc(I,In)
% 计算带噪语音信号的信噪比
% I 是纯语音信号
% In 是带噪的语音信号
% 信噪比计算公式是
% snr=10*log10(Esignal/Enoise)
I=I(:)'; % 把数据转为一列
In=In(:)';
Ps=sum((I-mean(I)).^2); % 信号的能量
Pn=sum((I-In).^2); % 噪声的能量
snr=10*log10(Ps/Pn); % 信号的能量与噪声的能量之比,再求分贝值基本谱减法函数SpectralSub
名称:SpectralSub
功能:谱减法语音降噪。
调用格式:
output =SpectralSub(signal, wlen, inc,NIS,a,b)
说明:输入参数signal是输入的含噪语音信号;wlen为窗函数或窗长;inc是帧移;NIS
是前导无话段帧数;a为过减因子;b为增益补偿因子。output是降噪后的信号。
函数程序如下:
function output=SpectralSub(signal,wlen,inc,NIS,a,b)
wnd=hamming(wlen); % 设置窗函数
N=length(signal); % 计算信号长度
y=enframe(signal,wnd,inc)'; % 分帧
fn=size(y,2); % 求帧数
y_fft = fft(y); % FFT
y_a = abs(y_fft); % 求取幅值
y_phase=angle(y_fft); % 求取相位角
y_a2=y_a.^2; % 求能量
Nt=mean(y_a2(:,1:NIS),2); % 计算噪声段平均能量
nl2=wlen/2+1; % 求出正频率的区间
for i = 1:fn; % 进行谱减
for k= 1:nl2
if y_a2(k,i)>a*Nt(k)
temp(k) = y_a2(k,i) - a*Nt(k);
else
temp(k)=b*y_a2(k,i);
end
U(k)=sqrt(temp(k)); % 把能量开方得幅值
end
X(:,i)=U;
end;
output=OverlapAdd2(X,y_phase(1:nl2,:),wlen,inc); % 合成谱减后的语音
Nout=length(output); % 把谱减后的数据长度补足与输入等长
if Nout>N
output=output(1:N);
elseif Nout案例、实验基本谱减法给带噪语音降噪
程序如下:
clear all; clc; close all;
[xx, fs] = audioread('C5_2_y.wav'); % 读入数据文件
xx=xx-mean(xx); % 消除直流分量
x=xx/max(abs(xx)); % 幅值归一化
IS=0.25; % 设置前导无话段长度
wlen=200; % 设置帧长为25ms
inc=80; % 设置帧移为10ms
SNR=5; % 设置信噪比SNR
N=length(x); % 信号长度
time=(0:N-1)/fs; % 设置时间
signal=awgn(x,SNR,'measured','db'); % 叠加噪声
snr1=SNR_Calc(x,signal); % 计算初始信噪比
NIS=fix((IS*fs-wlen)/inc +1); % 求前导无话段帧数
a=4; b=0.001; % 设置参数a和b
output=SpectralSub(signal,wlen,inc,NIS,a,b);% 谱减
snr2=SNR_Calc(x,output); % 计算谱减后的信噪比
snr=snr2-snr1;
fprintf('snr1=%5.4f snr2=%5.4f snr=%5.4f\n',snr1,snr2,snr);
% 作图
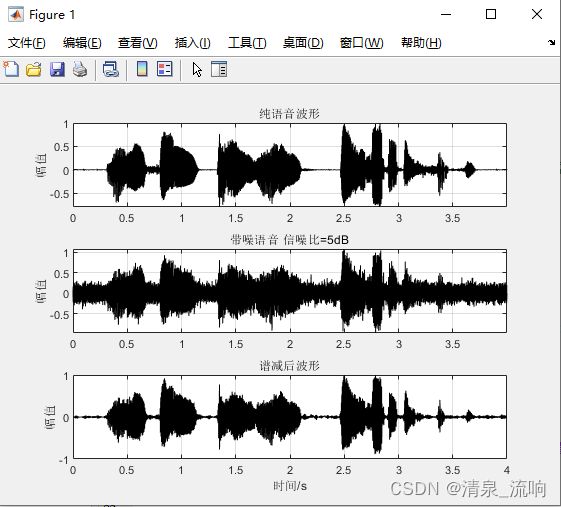
subplot 311; plot(time,x,'k'); grid; axis tight;
title('纯语音波形'); ylabel('幅值')
subplot 312; plot(time,signal,'k'); grid; axis tight;
title(['带噪语音 信噪比=' num2str(SNR) 'dB']); ylabel('幅值')
subplot 313; plot(time,output,'k');grid;%hold on;
title('谱减后波形'); ylabel('幅值'); xlabel('时间/s');运行结果如下:
实验使用到的语音数据下载链接如下:
https://download.csdn.net/download/qq_42233059/86442782
参考文献:语音信号处理实验教程;梁瑞宇、赵力、魏昕(编著)