多模态最新Benchmark!aiMotive DataSet:远距离感知数据集
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【多传感器融合】技术交流群
后台回复【aiMotive】获取更多论文和数据集等更多信息!
摘要
自动驾驶是计算机视觉领域的一个研究热点。因为自动驾驶汽车对安全性要求很高 ,确保鲁棒性对现实世界的部署至关重要。虽然有几个公共多模态数据集可以访问,但它们主要包括两种传感器模态(照相机、激光雷达),它们不太适合不利的天气。此外,它们缺乏远程标注,这使得训练神经网络变得更加困难,而神经网络是自动驾驶汽车高速公路辅助功能的基础。因此,本文引入了一个多模态数据集,用于具有远程感知的鲁棒自动驾驶。该数据集由176个场景组成,具有同步和校准的激光雷达(Lidar)、相机和毫米波雷达(Radar),覆盖360度视场。所收集的数据是在白天、夜间和下雨时在高速公路、城市和郊区捕获的,并使用具有跨帧一致标识符的3D边界框进行标注。此外,本文训练了用于三维目标检测的单模态和多模态基线模型。
介绍
在过去的几年里,大量用于自动驾驶(AD)中的三维目标检测的数据集已经发布[2,3,5,8,17,18]。大多数数据集都有一个共同的特性,即包含来自不同模态的传感器数据,包括摄像机和激光雷达。通过这种方式,360度的视野(FOV)可以覆盖到Ego交通工具的周围。三维目标检测数据集可以通过ego车辆周围的覆盖范围的维度和传感器冗余度分成不同的组。虽然许多数据集公开可用,但它们要么不提供传感器冗余(即至少两种传感器模态的覆盖),这对稳健的自动驾驶至关重要,要么只依赖于相机和激光雷达传感器,这些传感器在恶劣天气下并不完全适用(根据传感器覆盖和冗余分组的几种流行数据集的属性见表1)。这一问题可以通过使用毫米波雷达来解决,毫米波雷达是一种成本效益高的传感器,不受不利环境条件(例如雨或雾)的影响。此外,标注范围不超过80米(除了少数例外),这对于训练远程感知系统来说是不够的。标注范围的局限性可以解释为自动驾驶数据集主要集中在城市环境中,而确保检测远处目标的能力对高速公路辅助(assistant)至关重要,因此对自动驾驶来说也是如此。
为了克服上述限制,本文发布了一个多模态数据集,用于具有远程感知的鲁棒自动驾驶。收集的数据集包括176个场景,具有同步和校准的激光雷达、摄像机和毫米波雷达传感器,覆盖360度视场。这些数据是在不同的地理区域(高速公路、城市和郊区)以及不同的时间和天气条件(白天、夜晚、下雨)中捕获的。本文提供了3d bounding box,具有跨帧的一致标识符,这使得本文的数据集能够用于三维目标检测和多目标跟踪任务。建议的数据集是在CC BY-NC-SA 4.0 license下发布的,允许研究社区将收集的数据用于非商业研究目的。
主要贡献
本文发布了一个多模态自动驾驶数据集,具有冗余传感器覆盖,包括毫米波雷达和360°视场。
与现有的数据集相比,本文的数据集有一个扩展的标注范围,允许开发远程感知系统。
本文培训了单模态和多模态基线模型,并对其进行了基准测试。
相关工作
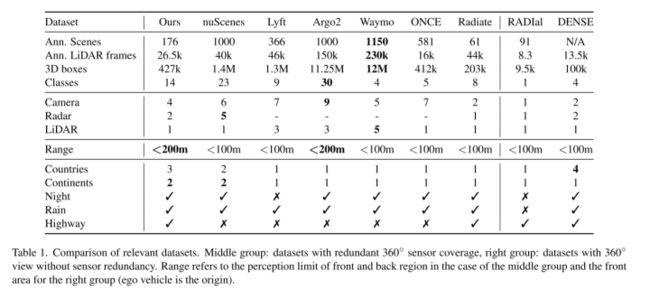
表1。相关数据集的比较。中间组:带有冗余360°传感器覆盖的数据集,右组:带有360°视图而没有传感器冗余的数据集。范围是指中间组对前后区域的感知极限,右组对前区域的感知极限(ego 车辆是原点)。
其中最有影响力的数据集是Geiger等人的KITTI[5],它引发了人们对自动驾驶中三维目标检测的兴趣。KITTI数据集包含在德国卡尔斯鲁厄记录的22个场景。传感器设置由前置摄像头和车顶安装的激光雷达组成。发布的数据集感知范围小于100米,不提供360度视场。此外,录像只在白天录制。
几种流行的三维目标检测数据集提供了360°的视场和传感器冗余。nuScenes[2]是与本文的工作最相似的数据集,包括整个传感器设置的完全传感器冗余。但在记录过程中使用了点云相对稀疏、感知范围有限的32波束激光雷达,导致感知极限短于100米(即在给定帧被标注的瞬间,没有距离ego车辆大于100米的标注对象)。传感器数据记录在城市环境中(波士顿、美国、新加坡),缺乏高速公路上的镜头。Waymo Open DataSet[25]是首个360°视场的大规模自动驾驶三维目标检测数据采集,包括1000多个场景和12M标注对象。该数据集的主要缺点是感知范围和传感器组有限。最近发布的Argoverse2 Sensor[27]数据集利用了从使用Argoverse[3]数据集承载几个挑战中获得的经验。Argoverse2的规模与Waymo Open DataSet相似,但标注范围有所扩展。与本文的解决方案相比,该数据集的缺点是缺乏毫米波雷达传感器的使用和记录位置的多样性(见表1)。Lyft Level 5感知数据集[10]和ONCE[15]都只有来自一个国家的记录,没有使用任何雷达,也不包含遥远地区的标注物体。
Radiate[23]使用三种不同的传感器模态,并在恶劣天气(例如雾、雨、雪)中包含大量标注关键帧。该论文的主要贡献是发布了一个高分辨率毫米波雷达数据集。然而,感知范围有限(即小于100米),其他传感器模态也受到限制(32束激光雷达具有非常稀疏的点云,只有前置摄像头具有低分辨率图像)。
另一组数据集也提供360度覆盖,没有传感器冗余,这对稳健的自动驾驶至关重要。RADIal[21]类似于Radiate,采用高清晰度毫米波雷达进行360°传感。记录的数据覆盖了广泛的地理区域,**然而传感器设置仅限于三个传感器。此外,数据集的标注对象数量有限(少于10K)**。Dence[1]还侧重于在恶劣天气下收集的数据。本文介绍了一种独特的传感器设置,包括热像仪、门控相机和旋转激光雷达。即使在记录车上安装了一组不同的传感器,在数据集的情况下也不能确保传感器冗余。此外,由于具有挑战性的天气条件,标注区域是有限的。
就像Tab 1的总结,本文的数据集比现有的相关工作有优势。所提出的数据集结合了传感器的全冗余和在不同环境下的长感知范围,这是以前发表的三维目标检测数据集所没有提供的。保证这些特性是训练神经网络所需要的,它可以作为能够在不同环境下运行的鲁棒的自动驾驶软件的基础。
数据集详解:Aimotive多模态数据集
本文的多模态数据集包括15s的长场景,具有同步和校准的传感器。该数据集使用冗余传感器布局提供360°视场,其中至少两个不同的传感器同时记录EGO车辆周围的区域。由于标注的3d bounding box具有跨帧一致的标识符,该数据集可以用于三维目标检测和多目标跟踪任务。另外,相当多的标注(约25%)位于关于自我载体的远距离区域(≥75m)。由于这种特性和冗余传感器的设置,本文的数据集可以促进多模态传感器融合和鲁棒的远程感知系统的研究。
1. 数据收集
这些数据是在两大洲的三个国家收集的,有四辆车,以提供一个多样化的数据集。录像发生在美国加州;奥地利;匈牙利,使用三辆丰田凯美瑞和一辆丰田普锐斯。录像的记录阶段跨越一年,以收集不同季节和天气条件的数据。因此,本文的数据集由一组不同的位置(高速公路、郊区、城市)、时间(白天、夜晚)和天气条件(太阳、云、雨、眩光)组成。数据收集方法满足了机构审查委员会批准的要求。
2. 传感器设置
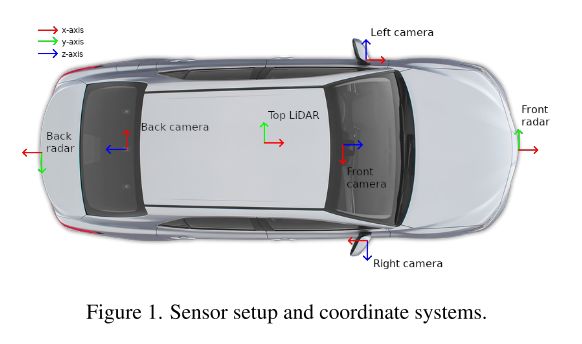
传感器布局。 这些数据是用一个屋顶安装(roof-mountend)、旋转的64波束激光雷达、四个摄像机和两个远程毫米波雷达记录的,提供了360度的传感器冗余覆盖。定位是基于高精度GNSS+INS传感器。更多细节可以在图1和Tab2找到。
同步。 所有记录的传感器数据都是同步的。激光雷达和毫米波雷达共享相同的时间戳来源。本文的相机使用滚动快门方法捕捉图像,这种方法快速扫描环境,而不是在单个时刻捕捉整个场景的快照。由于所使用的相机逐行捕捉场景,所以相机时间戳大约是捕捉中间行时的曝光时间。
坐标系。该数据集使用五个坐标系,即全球坐标系、人体坐标系、雷达坐标系、摄像机坐标系和图像坐标系。本文使用ECEF[24]作为全局坐标系,并为每个标注帧提供了一个6-DOF的ego车辆姿态。用于定义带标注对象的参考坐标系称为车身坐标系,该坐标系附着在车身上。原点是在标称车身高度和零速度下,车辆后轴中心下的投影地平面点。雷达坐标系使用与人体坐标系相同的轴(X轴正向前进,Y轴正向左边,Z轴正向向上)。将激光雷达点云转换到人体坐标系作为预处理步骤。摄像机坐标系的原点是摄像机的视点,坐标轴的定义与OpenCV[9]摄像机坐标系相同(x轴向右,y轴向下,z轴向前)。摄像机到物体和毫米波雷达到物体的变换可以使用摄像机和毫米波雷达外参(extrinsic)矩阵来执行。本文利用OpenCV的图像坐标系来绘制标注,使用内参矩阵从摄像机坐标投影到图像坐标。
3. Ground Truth 生成
本文使用了两种方法来生成ground truth标签:一种专有的用于训练数据生成的自动标注方法和用于创建验证数据的手动标注方法。由于自动批注可能容易出错,一个额外的手工质量检查后处理已经被执行,以过滤标签错误。即使我们的目标是使用人工验证来最小化标签噪声,但数据集中仍可能包含一些标签噪声。通过这种方式,本文选择了标记足够准确的记录,并丢弃了大多数错误的标注。
在验证集的情况下,本文雇佣了手动标注者在记录的传感器数据上标记对象。在标注阶段,人类标注者使用激光雷达和相机传感器数据来拟合出现在相机图像上的任何感兴趣的目标上的长方体。对于长方体大小,标注者使用默认尺寸。如果点云或图像上的默认尺寸与给定目标的大小不匹配,标注者根据自己的决定调整给定长方体的不匹配尺寸。手工劳动还确保了一个长方体轴与目标方向对齐,精度在5度以内。
将14个类的手动或自动标注的对象表示为具有一些附加物理属性的3D长方体。每个标记的边界框都有一个3D中心点、3D范围(沿水平x轴的长度、沿垂直y轴的宽度、沿z轴的高度)、方向(表示为四元数)、相对速度和唯一的轨迹ID。此外,本文利用FCOS[26]检测器提供了2d bounding box。使用匈牙利算法[11]关联2D-3D标注,以允许利用2D-3D一致性或半标记[16]。
4. 数据集分析
该数据集包括26 583个带有多种模态传感器数据的标注帧,分为21个402训练帧和5个181验证帧(80/20 训练集/验证集 分割)。这些场景是在不同的天气和环境条件下记录的。参见Tab3用于数据分发。
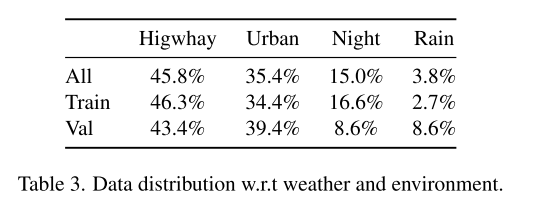
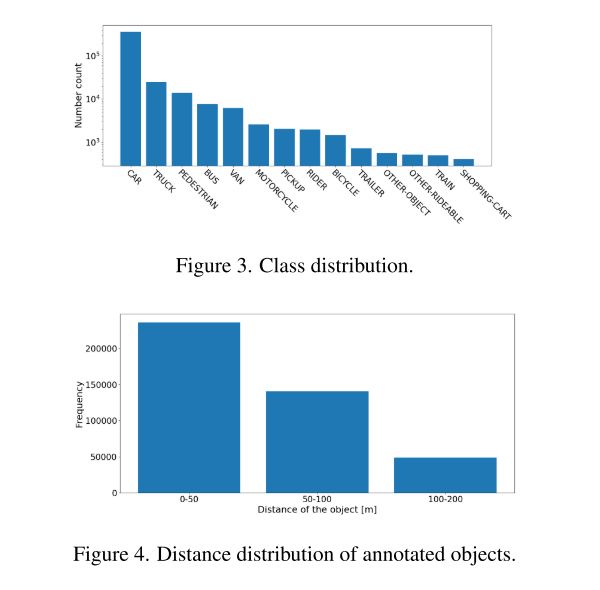
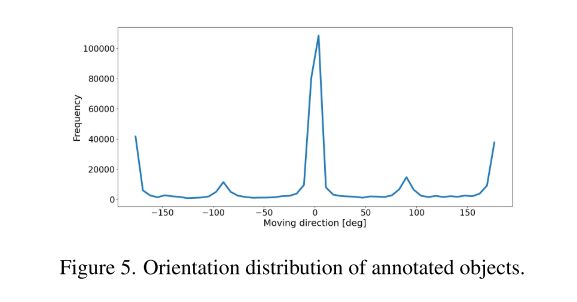
该数据集包含超过425k个对象,这些对象被组织成14个类别。图3中显示了类别分布。标注对象的距离分布在图4中被可视化。约24%的长方体在75米以上,Argoverse2约有14%,Waymo,nuScenes,一度不足1%。这一特性使得Longrange感知系统能够借助本文的数据集进行训练。在图2和图5中查看有关对象大小和方向分布的其他统计信息。
实验
本文使用公开可用的模型在本文的数据集上训练了几个三维目标检测基线。为了利用位于较远区域的标注,本文将目标网格定义为纵向[-204.8,204.8]m和横向[-25.6,25.6]m。本文将包含在数据集中的14个类别映射为四个类别(轿车、卡车/公共汽车、摩托车和行人),并在鸟瞰(BEV)空间以类别不可知的方式使用全点和11点插值平均精度(AP)度量[4]评估模型的性能。匈牙利方法[11]用于将ground truth和预测与0.3 IOU阈值联系起来。本文选择了一个小的IOU值作为关联阈值来处理BEV中在远距离区域特别频繁的位移误差。此外,利用平均方位相似度(AOS)[6]度量来评价模型在方位预测方面的性能。
1. 基线模型
本文的基线模型基于VoxelNet[30]、BevDepth[12]和BevFusion[14]用于激光雷达、相机和多模态模型。由于BevFusion不使用毫米波雷达传感器,本文为Lidar-Radar Fusion设计了一个简单的解决方案。也就是说,本文把毫米波雷达点云看作一个规则的激光雷达点云。经过点云合并步骤后,Voxelnet可以像处理常规激光雷达点云一样处理来自不同模态的数据。
Voxelnet具有直接在点云上操作的能力,由三个主要部分组成。体素特征编码器(VFE)负责在单个体素级别对原始点云进行编码。Voxelnet利用堆叠的VFE层,其输出由中间卷积神经网络(CNN)进一步处理,以聚集体素特征。执行3D目标检测的最后一个组件是区域建议网络[22]。
BevDepth是一个只需摄像头的三维目标检测网络,提供可靠的深度估计。作者的主要观察是,最近使用像素深度估计的仅摄像机的三维目标检测方案由于深度估计不足而产生次优结果。因此,显式深度监督编码的内参和外参被利用。此外,利用激光雷达点云的稀疏深度数据引入了深度校正子网络,为深度估计网络提供监督。
BEVFusion的主要贡献是利用BEV空间作为摄像机和激光雷达传感器融合的统一表示。BevFusion提出的图像主干显式地预测每个图像像素的离散深度分布,类似于BevDepth(没有深度校正子网络)。然后,对三维特征点云应用BEV池化算子,然后沿Z轴对其进行展平,得到BEV中的特征映射。激光雷达产生的点云的处理方式与Voxelnet的处理方式相同,两个BEV特征图由CNN融合。最后,将检测头附加到融合子网络的输出上。
2. 实施细节
基线模型的激光雷达组件使用HardSimpleVFE[28]作为体素特征编码器,使用SparseEncoder[28]作为中间编码器CNN。图像组件采用Lift-Splat-Shot[19]作为图像编码器,具有Resnet-50主干,随后是用于利用多尺度特征的特征金字塔网络[13]。一个额外的深度校正网络也是图像流的一部分,灵感来自BEVDepth。在多模态模型的情况下,不同模态的特征使用由卷积和挤压激励组成的简单融合子网络来融合[7]。最后,Centerpoint[29]头负责从单峰和多峰情况下的BEV特征中检测对象。
由于本文的目标不是在这项工作中开发最先进的模型,而是为了促进多模态目标探测研究,本文使用了BEVDEPTH提供的超参数,而没有进行任何繁重的参数调整。本文调整了网格分辨率,以支持远程检测,并使用批量大小4,训练模型,使用BEV特征空间中的翻转、旋转和缩放,以6.25e-5的学习速率进行16K迭代(3个 epochs)。本文使用了一个NVIDIA A100 TensorCore GPU进行神经网络训练。这些模型是用MMDetection3D实现的。
3. 实验结果
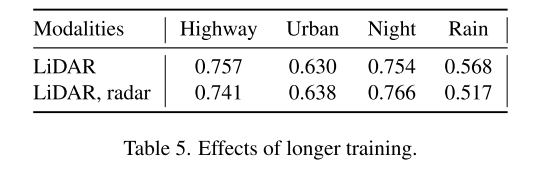
在Tab 4中描述了基线模型在不同度量上的性能比较。由于文献中有几个例子[14,20]说明了仅用激光雷达的单峰解优于仅用摄像机的模型,所以本文没有训练仅用摄像机的基线。正如表中所描述的,在非不利的天气和时间下,每个多模态模型在公路和城市环境中都超过了LIDAR-ONLY基线。在密集的城市环境中,附加的传感器信号显著提高了检测性能。然而,单峰基线在大雨中表现最好,人们会认为毫米波雷达信号应该有助于提高性能。这一现象表明,更复杂的毫米波雷达融合技术可能有利于增强多模态模型。
摄像机在方位预测方面起着至关重要的作用。没有RGB图像的模型难以始终如一地保持方向,尤其是在大型车辆的情况下。这种闪烁效应(flickering effect)在使用相机传感器的模型中不太明显。使用所有模态的模型在AOS指标上表现最好。
令人惊讶的是,使用激光雷达+相机模态的模型在夜间和城市环境中的表现远远超过了所有其他模型。本文研究了学习曲线,发现增加训练步数有助于进一步提高性能。为了验证本文的假设,本文对本文的模型进行了5个额外的时间点的训练。不幸的是,使用相机传感器的模型在第三个epoch后变得不稳定,导致深度损失爆炸。Tab 5描述了使用11点插值AP度量的更长训练过程的结果。在所有环境中都可以看到坚实的改进,尤其是在雨天验证集(激光雷达和激光雷达+雷达模型分别为+10.8/+6.2AP)上。这可以用训练越长,探测热图越清晰的事实来解释。在第一组基线模型的情况下,模糊的热图导致AP指标较低。在大雨的情况下,由于雨滴的激光雷达反射,热图上的模糊效果在EGO汽车周围非常明显。
为了验证基线模型的远距离感知能力,本文对长期训练的模型进行了远距离目标检测的基准测试。在距离EGO汽车不到75米的地方,探测和ground truth被过滤掉。结果总结在Tab 6中(定性例子见图8)。两种模型在公路环境下的性能相似,没有显著差异。然而,在所有其他环境中,带有额外毫米波雷达信号的模型明显优于仅使用激光雷达的基线。事实上,如图7所示,毫米波雷达传感器即使在恶劣天气下也提供用于感知远处区域中的对象的可靠且准确的信号,可以被用于提高3D目标检测器的性能。在密集的城市环境中也可以观察到类似的效果,在这种环境中,毫米波雷达信号被多模态基线利用,从而导致远距离感知性能的显著提高(+5.5/+4.7全点/11点插值AP)。
训练结果表明,该数据集可以作为多模态远距离感知神经网络训练的基础。诸如测试时间延长或模型集成等先进的评估技术可以导致进一步的改进。但是,在评估方法的过程中,没有一个被应用。Tab 5表明需要进一步改进传感器融合方法以充分利用每一种模态,本文的朴素方法提供了一个次优解。尽管如此,本文希望研究界会发现本文的数据集是有用的,可以在本文基线的基础上进行构建,并显著提高其性能。

表6,远区(>75m)基线模型的比较。第一组:全点AP度量,第二组:11点插值AP度量,第三组:Val-set上平均的AOS度量。
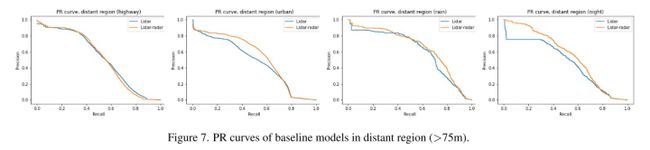

图8。定性结果:激光雷达+毫米波雷达基线模型的检测。上排:激光雷达点云检测。中排:毫米波雷达目标检测,下排(从左到右):左、前、右、后摄像头检测。
总结
本文提出了一个多模态数据集用于鲁棒的远程感知自动驾驶。本文在两大洲的三个国家记录的不同数据集包括来自激光雷达、毫米波雷达和摄像机的传感器数据,提供冗余的360度传感器覆盖。该数据集包含了大量远距离区域的标注对象,使得多模态远程感知神经网络的开发成为可能。此外,本文开发了几个单模态和多模态基线模型,并比较了它们在所提出的数据集上基于不同标准的性能。本文的数据集充分利用了记录的传感器模态的优势,可以用于训练、多模态、远程感知神经网络。在未来,本文的目标是扩展本文收集的数据集与额外的环境和天气条件。此外,本文还将对多模态神经网络的传感器融合进行更深入的实验。本文期望通过发布本文的数据集来促进多模态传感器融合和鲁棒的远程感知系统的研究。
参考
[1] Matuszka T, Barton I, Butykai Á, et al. aiMotive Dataset: A Multimodal Dataset for Robust Autonomous Driving with Long-Range Perception[J]. arXiv preprint arXiv:2211.09445, 2022.
往期回顾
多模态3D目标检测发展路线方法汇总!(决策级/特征级/点/体素融合)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
