【机器学习小记】【keras与残差网络】deeplearning.ai course4 2nd week programming(tensorflow2.0实现)
Keras入门与残差网络的搭建
- 1 keras 入门
-
- 导入库函数
- 加载数据
- 1.2 使用Keras框架搭建模型
-
- 测试
- 2 残差网络的搭建
-
- 导入库函数
- 2.2.1 恒等块
- 2.2.2 卷积块
- 2.3 构建50层的残差网络
- 加载数据
- 训练模型
- 加载模型
- 2.4 用自己的图片测试
- 3 相关代码
-
- 3.1 kt_utils.py
- 3.2 resnets_utils.py
- 其他一些问题
-
- tf.keras.BatchNormalization
- tf.keras.MaxPooling2D和MaxPool
- tf.keras.Model的`compile`、`fit`和`evaluate`
-
- model.compile
- model.fit
- model.evaluate
- 评价指标metrics
- 保存
-
- 使用model.save_weight
- 使用checkpoint
- model.save
目标:
1. 学习使用tf.keras
2. 学习搭建ResNet
修改【参考文章】的代码,使用tensorflow2实现
参考自:【中文】【吴恩达课后编程作业】Course 4 - 卷积神经网络 - 第二周作业 - Keras入门与残差网络的搭建
1 keras 入门
导入库函数
import numpy as np
import kt_utils
import matplotlib.pyplot as plt
import tensorflow as tf
import os
# 不使用GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
加载数据
"""
加载数据集
600个训练集
150个测试集
X_train.shape == (600,64,64,3)
Y_train.shape == (600,1)
图片是600张64x64的3通道图片
标签,0表示not happy,1表示happy
"""
def get_data():
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = kt_utils.load_dataset()
# Normalize image vectors
X_train = X_train_orig / 255.
X_test = X_test_orig / 255.
# Reshape
Y_train = Y_train_orig.T
Y_test = Y_test_orig.T
# print("number of training examples = " + str(X_train.shape[0]))
# print("number of test examples = " + str(X_test.shape[0]))
# print("X_train shape: " + str(X_train.shape))
# print("Y_train shape: " + str(Y_train.shape))
# print("X_test shape: " + str(X_test.shape))
# print("Y_test shape: " + str(Y_test.shape))
return X_train, Y_train, X_test, Y_test, classes
1.2 使用Keras框架搭建模型
实例化Model有两种方式,这里使用继承Model的方式。
(这种方法不好用,是我不会用 ,按照原博文的就行了。)
class HappyModel(tf.keras.Model):
def get_config(self):
pass
def __init__(self,input_shape=(64,64,3)):
super().__init__()
# 使用0填充
self.zp0 = tf.keras.layers.ZeroPadding2D(
padding=(3, 3)
)
# conv -> bn -> relu
self.conv0 = tf.keras.layers.Conv2D(
filters=32,
kernel_size=(7,7),
strides=(1, 1),
name="conv0"
)
self.bn0 = tf.keras.layers.BatchNormalization(
axis=3, # 指向[NHWC]的channel维度,当数据shape为[NCHW]时,令axis=1。此时3=-1
name="bn0",
)
self.ac0 = tf.keras.layers.Activation(
activation=tf.keras.activations.relu
)
self.pl0 = tf.keras.layers.MaxPooling2D(
pool_size=(2, 2),
name="max_pool"
)
self.flatten = tf.keras.layers.Flatten()
self.dense = tf.keras.layers.Dense(
units=1,
activation=tf.keras.activations.sigmoid,
name="fc"
)
def call(self, inputs, training=None, mask=None):
x = self.zp0(inputs)
x = self.conv0(x)
x = self.bn0(x)
x = self.ac0(x)
x = self.pl0(x)
x = self.flatten(x)
output = self.dense(x)
return output
- 一定需要重写
call和get_config - Model有两种实例化方式,Model实例化方式
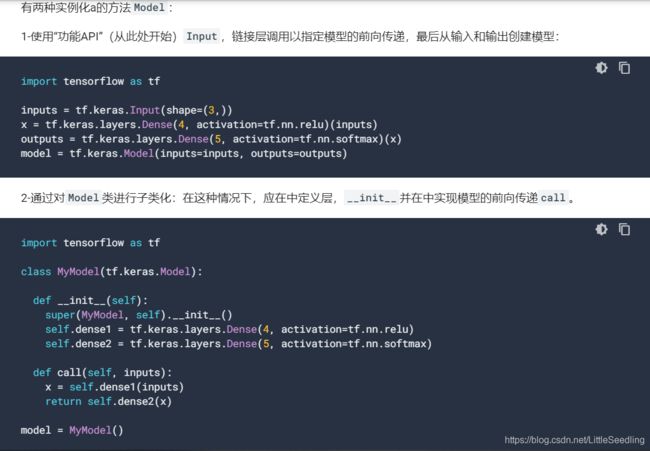
- 如果要使用
model.summary显示模型的详细信息,需要调用前需要调用model.call(tf.keras.layers.Input(shape=(64,64,3))) - 使用这种方法(继承Model)定义的model,无法保存(save)整个模型(报错,目前没找到解决办法。)
测试
训练40次
def test_train():
X_train, Y_train, X_test, Y_test, classes = get_data()
# 创建一个模型实体
happy_model = HappyModel()
# 实例化checkpoint
check_point = tf.train.Checkpoint(myModel=happy_model)
# 取上次最近的保存
check_point.restore(tf.train.latest_checkpoint("./save"))
# 编译模型
happy_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.009),
loss=tf.keras.losses.binary_crossentropy,
metrics=[tf.keras.metrics.binary_accuracy])
# 训练模型
# 请注意,此操作会花费你大约6-10分钟。
happy_model.fit(x=X_train, y=Y_train, epochs=40, batch_size=50)
# 评估模型
preds = happy_model.evaluate(x=X_test, y=Y_test, batch_size=32)
print("误差值 = " + str(preds[0]))
print("准确度 = " + str(preds[1]))
# 仅保存参数
check_point.save("./save/happy_model.ckpt")
happy_model.call(tf.keras.layers.Input(shape=(64,64,3)))
happy_model.summary()
输出:
Epoch 1/40
12/12 [==============================] - 5s 416ms/step - loss: 11.7985 - binary_accuracy: 0.5950
Epoch 2/40
12/12 [==============================] - 5s 389ms/step - loss: 1.6851 - binary_accuracy: 0.7867
...
...
Epoch 39/40
12/12 [==============================] - 5s 417ms/step - loss: 0.1432 - binary_accuracy: 0.9650
Epoch 40/40
12/12 [==============================] - 5s 399ms/step - loss: 0.1131 - binary_accuracy: 0.9733
5/5 [==============================] - 0s 32ms/step - loss: 0.2060 - binary_accuracy: 0.9400
误差值 = 0.20602744817733765
准确度 = 0.9399999976158142
Model: "happy_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
zero_padding2d (ZeroPadding2 (None, 70, 70, 3) 0
_________________________________________________________________
conv0 (Conv2D) (None, 64, 64, 32) 4736
_________________________________________________________________
bn0 (BatchNormalization) (None, 64, 64, 32) 128
_________________________________________________________________
activation (Activation) (None, 64, 64, 32) 0
_________________________________________________________________
max_pool (MaxPooling2D) (None, 32, 32, 32) 0
_________________________________________________________________
flatten (Flatten) (None, 32768) 0
_________________________________________________________________
fc (Dense) (None, 1) 32769
=================================================================
Total params: 37,633
Trainable params: 37,569
Non-trainable params: 64
_________________________________________________________________
2 残差网络的搭建
残差网络的的作用:
理论上,越深的网络越能实现复杂的功能,但实际上往往伴随着梯度消失和梯度爆炸的问题,导致非常难以训练。
残差网络通过将浅层网络的输出直接传送到更深层网络,缓解了梯度消失的问题。
导入库函数
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import kt_utils
import resnets_utils
import os
# 不使用GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
2.2.1 恒等块
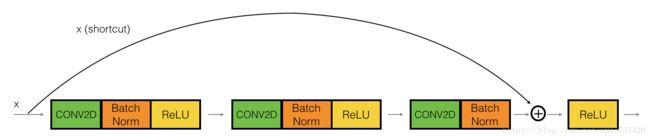
2.2.2 卷积块
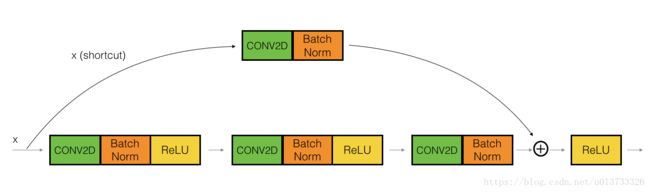
这里的输入,都跳跃了3层
2.3 构建50层的残差网络
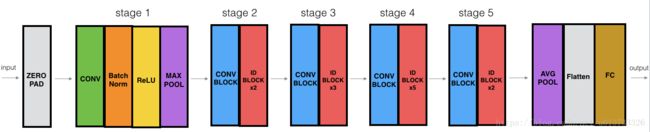
def ResNet50(input_shape=(64,64,3),classes=6):
"""
实现ResNet50
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
参数:
input_shape - 图像数据集的维度
classes - 整数,分类数
返回:
model - Keras框架的模型
"""
# 定义tensor类型的输入数据
X_input = tf.keras.layers.Input(input_shape)
# 0填充
X = tf.keras.layers.ZeroPadding2D(
padding=(3,3)
)(X_input)
# stage1
X = tf.keras.layers.Conv2D(
filters=64,
kernel_size=(7,7),
strides=(2,2),
name="conv1",
kernel_initializer=tf.initializers.glorot_uniform(seed=0)
)(X)
X = tf.keras.layers.BatchNormalization(
axis=3,
name="bn_conv1"
)(X)
X = tf.keras.layers.Activation(
activation=tf.keras.activations.relu
)(X)
X = tf.keras.layers.MaxPooling2D(
pool_size=(3,3),
strides=(2,2)
)(X)
# stage2
X = convolutional_block(X,f=3,filters=[64,64,256],stage=2,block="a",s=1)
X = identity_block(X,f=3,filters=[64,64,256],stage=2,block="b")
X = identity_block(X,f=3,filters=[64,64,256],stage=2,block="c")
# stage3
X = convolutional_block(X,f=3,filters=[128,128,512],stage=3,block="a",s=2)
X = identity_block(X, f=3, filters=[128, 128, 512], stage=3, block="b")
X = identity_block(X, f=3, filters=[128, 128, 512], stage=3, block="c")
X = identity_block(X, f=3, filters=[128, 128, 512], stage=3, block="d")
# stage4
X = convolutional_block(X, f=3, filters=[256, 256, 1024], stage=4, block="a", s=2)
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block="b")
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block="c")
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block="d")
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block="e")
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block="f")
# stage5
X = convolutional_block(X, f=3, filters=[512, 512, 2048], stage=5, block="a", s=2)
X = identity_block(X, f=3, filters=[512, 512, 2048], stage=5, block="b")
X = identity_block(X, f=3, filters=[512, 512, 2048], stage=5, block="c")
# 均值池化层
X = tf.keras.layers.AveragePooling2D(
pool_size=(2,2),
padding="same"
)(X)
# 输出层
## 拉平
X = tf.keras.layers.Flatten()(X)
## 全连接
X = tf.keras.layers.Dense(
units=classes,
activation=tf.keras.activations.softmax,
name="fc"+str(classes),
kernel_initializer=tf.initializers.glorot_uniform(seed=0)
)(X)
# 创建模型
model = tf.keras.Model(inputs=X_input,outputs=X,name="ResNet50")
return model
和原博文相同,这里使用功能API实例化Model。Keras会从Input开始,链接调用指定的层,进行前向传播,最后创建出模型。
加载数据
def get_data():
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = resnets_utils.load_dataset()
# Normalize image vectors
X_train = X_train_orig / 255.
X_test = X_test_orig / 255.
# Convert training and test labels to one hot matrices
Y_train = resnets_utils.convert_to_one_hot(Y_train_orig, 6).T
Y_test = resnets_utils.convert_to_one_hot(Y_test_orig, 6).T
# print("number of training examples = " + str(X_train.shape[0]))
# print("number of test examples = " + str(X_test.shape[0]))
# print("X_train shape: " + str(X_train.shape))
# print("Y_train shape: " + str(Y_train.shape))
# print("X_test shape: " + str(X_test.shape))
# print("Y_test shape: " + str(Y_test.shape))
"""
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
"""
return X_train,Y_train,X_test,Y_test
训练模型
def train():
X_train, Y_train, X_test, Y_test = get_data()
model = ResNet50(input_shape=(64, 64, 3), classes=6)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=tf.keras.metrics.categorical_accuracy
)
model.fit(X_train, Y_train, epochs=1, batch_size=32)
preds = model.evaluate(X_test, Y_test)
print("误差值 = " + str(preds[0]))
print("准确率 = " + str(preds[1]))
# 可以保存
# model.save("my_model_res50.h5")
这里使用功能API实例化的Model,是可以使用model.save保存整个模型的。
运行结果:
Epoch 1/2
34/34 [==============================] - 156s 5s/step - loss: 2.2758 - categorical_accuracy: 0.4713
Epoch 2/2
34/34 [==============================] - 132s 4s/step - loss: 1.0789 - categorical_accuracy: 0.6231
4/4 [==============================] - 1s 193ms/step - loss: 3.5756 - categorical_accuracy: 0.1750
误差值 = 3.5755507946014404
准确率 = 0.17499999701976776
加载模型
def load_weight():
X_train, Y_train, X_test, Y_test = get_data()
model = tf.keras.models.load_model("ResNet50.h5")
# model = tf.keras.models.load_model("my_model_res50.h5")
preds = model.evaluate(X_test, Y_test)
print("误差值 = " + str(preds[0]))
print("准确率 = " + str(preds[1]))
# 查看网络细节
# 可以查看,且正确
model.summary()
加载模型的运行结果:
4/4 [==============================] - 1s 169ms/step - loss: 0.1085 - accuracy: 0.9667
误差值 = 0.1085430383682251
准确率 = 0.9666666388511658
2.4 用自己的图片测试
def test_my_image():
model = tf.keras.models.load_model("ResNet50.h5")
img_path = "my_image.jpg"
my_image = tf.keras.preprocessing.image.load_img(img_path,target_size=(64,64))
# 显示图片
# 图像窗口名字
plt.imshow(my_image)
# 关掉坐标轴
plt.axis("off")
# 图像表提
plt.title("my_image")
plt.show()
my_image = tf.keras.preprocessing.image.img_to_array(my_image)
# 扩维
my_image = np.expand_dims(my_image,axis=0)
# 归一化
my_image = my_image / 255
# print("my_image.shape = " + str(my_image.shape))
# 获得预测结果
pred = model.predict(my_image)
print("预测结果是:",np.argmax(pred))
3 相关代码
3.1 kt_utils.py
# import keras.backend as K
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
# def mean_pred(y_true, y_pred):
# return K.mean(y_pred)
def load_dataset():
train_dataset = h5py.File('datasets/train_happy.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_happy.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
3.2 resnets_utils.py
import os
import numpy as np
import tensorflow as tf
import h5py
import math
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
def random_mini_batches(X, Y, mini_batch_size=64, seed=0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples) (m, Hi, Wi, Ci)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) (m, n_y)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[0] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :, :, :]
shuffled_Y = Y[permutation, :]
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(
m / mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[k * mini_batch_size: k * mini_batch_size + mini_batch_size, :, :, :]
mini_batch_Y = shuffled_Y[k * mini_batch_size: k * mini_batch_size + mini_batch_size, :]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[num_complete_minibatches * mini_batch_size: m, :, :, :]
mini_batch_Y = shuffled_Y[num_complete_minibatches * mini_batch_size: m, :]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)].T
return Y
def forward_propagation_for_predict(X, parameters):
"""
Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
# Numpy Equivalents:
Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3
return Z3
def predict(X, parameters):
W1 = tf.convert_to_tensor(parameters["W1"])
b1 = tf.convert_to_tensor(parameters["b1"])
W2 = tf.convert_to_tensor(parameters["W2"])
b2 = tf.convert_to_tensor(parameters["b2"])
W3 = tf.convert_to_tensor(parameters["W3"])
b3 = tf.convert_to_tensor(parameters["b3"])
params = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
z3 = forward_propagation_for_predict(X, params)
prediction = tf.argmax(z3)
return prediction
其他一些问题
tf.keras.BatchNormalization
class BatchNormalizationBase(Layer):
def __init__(self,
axis=-1,# 指向[NHWC]的channel维度,当数据shape为[NCHW]时,令axis=1
momentum=0.99,# 计算均值与方差的滑动平均时使用的参数(滑动平均公式中的beta,不要与这里混淆)
epsilon=1e-3,
center=True,# bool变量,决定是否使用批标准化里的beta参数(是否进行平移)
scale=True,# bool变量,决定是否使用批标准化里的gamma参数(是否进行缩放)
beta_initializer='zeros',# 调用init_ops.zeros_initializer(),beta参数的0初始化,beta参数是平移参数
gamma_initializer='ones',# 调用init_ops.ones_initializer(),gamma参数的1初始化,gamma参数是缩放参数
moving_mean_initializer='zeros',# 均值的滑动平均值的初始化,初始均值为0
moving_variance_initializer='ones',# 方差的滑动平均值的初始化,初始均值为1# 可见初始的均值与方差是标准正态分布的均值与方差
beta_regularizer=None,# beta参数的正则化向,一般不用
gamma_regularizer=None,# gamma 参数的正则化向,一般不用
beta_constraint=None,# beta参数的约束项,一般不用
gamma_constraint=None,# gamma 参数的约束项,一般不用
renorm=False,
renorm_clipping=None,
renorm_momentum=0.99,
fused=None,
trainable=True,# 默认为True,这个我觉得就不要改了,没必要给自己找麻烦,
# 就是把我们标准化公式里面的参数添加到
# GraphKeys.TRAINABLE_VARIABLES这个集合里面去,
# 因为只有添加进去了,参数才能更新,毕竟γ和β是需要学习的参数。
# 但是,tf.keras.layers.BatchNormalization中并没有做到这一点,
# 所以需要手工执行这一操作。
virtual_batch_size=None,
adjustment=None,
name=None,
**kwargs)
tf.keras.MaxPooling2D和MaxPool
二者,一个是原生的,一个是社区贡献的。
tf.keras.Model的compile、fit和evaluate
model.compile
注意:优化器,Adam()需要一个()
model.compile(
# 优化器
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
# 损失函数
loss=tf.keras.losses.sparse_categorical_crossentropy,
# 评估指标
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit
model.fit(
x=X_train, # 训练集输入
y=Y_train, # 训练集标签
epochs=num_epochs, # 迭代次数
batch_size=batch_size # 每次更新参数,的样本数间隔
)
model.evaluate
返回一个元组(损失度,精确度)
model.evaluate(
x=X_test, # 测试集输出
y=Y_test # 测试集标签
)
评价指标metrics
- 如果metrics=[“acc”] or metrics = [“accuracy”],将会自动选择符合loss函数的评价指标。
- 对于二分类问题,评价指标可以用 binary_accuracy,就是最直观上讲的准确率。
- 当面对多分类或者多标签的任务时,评价度量可能会用到这两个 categorical_accuracy和 sparse_categorical_accuracy
Keras: 评价指标 categorical_accuracy和 sparse_categorical_accuracy
保存
使用model.save_weight
只能保存参数
model.save_weights("./save/model.ckpt")
model.load_weights("./save/model.ckpt")
使用checkpoint
只能保存参数
# train.py 模型训练阶段
model = MyModel()
# 实例化Checkpoint,指定保存对象为model(如果需要保存Optimizer的参数也可加入)
checkpoint = tf.train.Checkpoint(myModel=model)
# ...(模型训练代码)
# 模型训练完毕后将参数保存到文件(也可以在模型训练过程中每隔一段时间就保存一次)
checkpoint.save('./save/model.ckpt')
# test.py 模型使用阶段
model = MyModel()
checkpoint = tf.train.Checkpoint(myModel=model) # 实例化Checkpoint,指定恢复对象为model
checkpoint.restore(tf.train.latest_checkpoint('./save')) # 从文件恢复模型参数
# 模型使用代码
checkpoint 可以保存多次,而不覆盖之前的内容
model.save
保存整个模型
model.save("my_model_res50.h5")
model = tf.keras.models.load_model("my_model_res50.h5")
注:
实例化Model有两种方法。
使用功能性API实例化Model才能使用。