2019独角兽企业重金招聘Python工程师标准>>> 
在了解了TensorflowJS的一些基本模型的后,大家会问,这究竟有什么用呢?我们就用深度学习中被广泛使用的MINST数据集来进行一下手写识别的操作。
MINST数据集
MINST是一组0到9的手写数字。就像这个:
这组数据出现在各种深度学习的入门和例子中,有点像传统机器学习中的Iris数据集。被各种使用。
TensorflowJS提供了一个关于训练MINST数据集的例子。

为了便于重用,笔者把其中提供数据的代码提取出来。大家可以参考。该部分主要功能有:
- class MnistData()提供数据类
- load()对Minst数据的异步加载
- nextTrainBatch(batchSize)从训练数据集中随机返回batchSize的数据,虽然MINST数据集是有限的,但是调用nextBatch总是能返回数据。
- nextTestBatch(batchSize)从测试数据集中随机返回batchSize的数据
let data;
async function load() {
data = new MnistData();
await data.load();
}
async function mnist() {
await load();
console.log("Data loaded!");
}
mnist().then(function(){
const train_data = data.nextTrainBatch(batch_size);
// 使用train_data数据
}); 返回的train_data的格式如下:
- train_data.xs 是shape为[16, 784]的张量,16是数据的个数,784 = 28*28,是二维图像打平后的数据。
- train_data.labels是shape为[16, 10]的张量,16是数据的个数,每一个数据标签是一个有是个数值的向量。分别对应0-9
请参考的我的代码演示:

逻辑回归
在我的前一篇文章《在浏览器中进行深度学习:TensorFlow.js (三)更多的基本模型》中,我们使用逻辑回归演示了对空间二维数据点的分类算法。这一次我就拿MINST数据集来试一试。
训练算法代码如下:
function logistic_regression(train_data) {
const batch_size = 1000;
const numIterations = 1000;
const number_of_labels = 10;
let loss_results = [];
const learningRate = 0.15;
const optimizer = tf.train.sgd(learningRate);
const w = tf.variable(tf.zeros([784,number_of_labels]));
const b = tf.variable(tf.zeros([number_of_labels]));
function predict(x) {
return tf.softmax(tf.add(tf.matMul(x, w),b));
}
function loss(predictions, labels) {
const entropy = tf.mean(tf.sub(tf.scalar(1),tf.sum(tf.mul(labels, tf.log(predictions)),1)));
return entropy;
}
for (let iter = 0; iter < numIterations; iter++) {
const batch = train_data.nextTrainBatch(batch_size);
const train_x = batch.xs;
const train_y = batch.labels;
optimizer.minimize(() => {
const loss_var = loss(predict(train_x), train_y);
loss_results.push({
x:new Date().getTime(),
y:loss_var.dataSync()[0]
});
return loss_var;
})
train_x.dispose();
train_y.dispose();
}
return {
model : predict,
loss : loss_results
};
}大家可以比较一下和之前的例子的区别,可以发现几个小的差异:
- 之前的例子数据和数据的标签是分开的,这里数据和标签在train_data的xs和labels属性中。
- 逻辑回归的连个变量w和b的shape不一样,因为这些变量要和问题域的数据形状保持一致。
- loss_result用于训练完成后返回训练过程中损失的变化。
- 调用dispose方法释放资源。
请参考的我的代码演示:

BatchSize=16,迭代100次,准确率为0.9。白底黑字的是预测错误的数据。
这个是验证准确率的代码:
const test_batch = data.nextTestBatch(100);
const prediction = train_result.model(test_batch.xs);
const correct_prediction = tf.equal(tf.argMax(prediction,1), tf.argMax(test_batch.labels, 1));
const accuracy = tf.mean(tf.cast(correct_prediction,'float32'));过程入下:
- 从测试数据中取100个点
- 对这100点做预测
- 计算有哪些点是预测正确的。tf.argMax(prediction,1) 返回预测结果在维度1上最大值所在的索引。因为对于标签而言,[1,0,0,0,0,0,0,0,0,0]表示0,[0,1,0,0,0,0,0,0,0,0]表示1,所以最大值的索引,其实就是1的位置,也就是预测的结果。tf.equal检查连个张量是不是相等。
- 计算正确预测的数据的均值,也就是准确率。

增大迭代次数,准确率并没有提高。
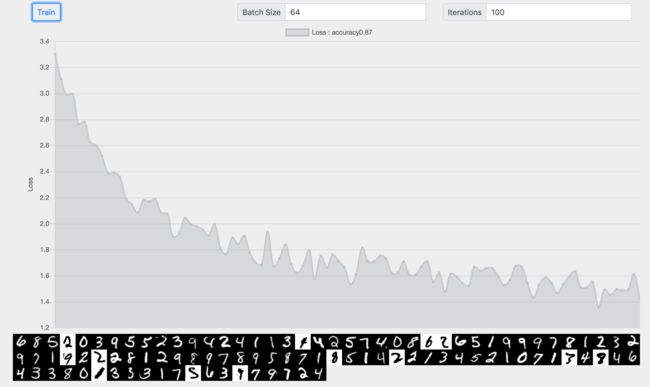
增大BatchSize对结果也没有改善。
测试下来,逻辑回归的算法应用在MINST数据集上准确率在90%左右。
近邻算法
同样的我们也试一下近邻算法在MINST数据上的分类效果。
function nearest_neighbers(train_data) {
const train_xs = train_data.xs;
const train_labels = train_data.labels;
let results;
return function(x) {
for (let i = 0; i < x.shape[0]; i++) {
const xs = x.slice([i, 0], [1, x.shape[1]]);
const distance = tf.sum(tf.abs(tf.sub(xs, train_xs)),1);
const label_index = tf.argMin(distance, 0);
if (results ) {
results = results.concat(train_labels.gather(label_index.expandDims(0)));
} else {
results = train_labels.gather(label_index.expandDims(0));
}
}
return results;
};
}该算法采用L1距离来预测,简单的说就是计算目标张量离训练数据哪一个近,就分为那个类。
这里:
- 对每一输入数据,计算和训练数据各个点的距离,找到最近的点,可以理解为找到长得最像的图像。
- 所有的输入点都计算完后,利用tf.concat方法把结果合并在一个张量中返回。
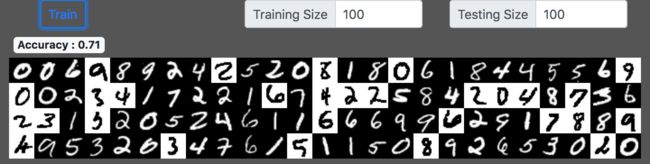


我们发现,因为不存在迭代,分类的准确率和训练数据的规模关系明显:
- 100 > 0.71
- 1000 > 0.88
- 5000 > 0.92
还有如果你选择训练集size为1你会发现:

如上图所示,只有数字3能被准确分类。我可以肯定,那个训练数据就是3 。
好了,至今,这个系列已经是第四篇了,说好的深度学习呢?作者该不是个骗子吧?请大家稍安勿躁,我保证后面一定有深度学习的内容。

参考
- 在浏览器中进行深度学习:TensorFlow.js (三)更多的基本模型
- 在浏览器中进行深度学习:TensorFlow.js (二)第一个模型,线性回归
- 在浏览器中进行深度学习:TensorFlow.js (一)基本概念