An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
论文:https://arxiv.org/abs/2010.11929#
代码:https://github.com/lucidrains/vit-pytorch
https://github.com/likelyzhao/vit-pytorch
https://github.com/google-research/vision_transformergithub.com
1 核心思想
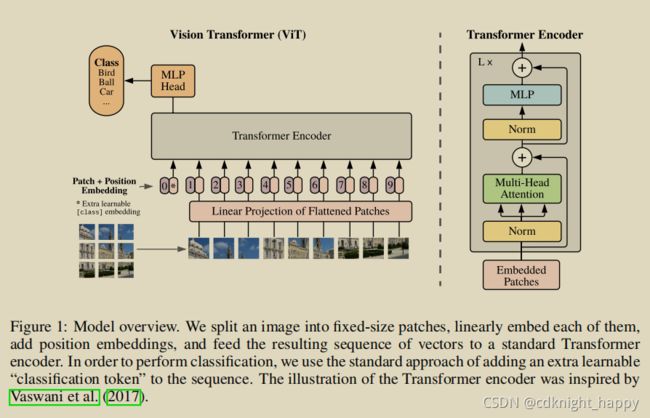 应用ViT进行图像分类的处理过程:
应用ViT进行图像分类的处理过程:
- 输入图像分块,原始图像为 x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C,分块后为 x p ∈ R N × ( P 2 C ) x_p \in R^{N \times (P^2 C)} xp∈RN×(P2C),每个图像块的大小为 ( P , P ) (P,P) (P,P), N = H W / P 2 N = HW/P^2 N=HW/P2为图像块的数目, C C C为图像的通道数;这一步操作的目的是模仿原始Transformer的输入的形式, N N N表示输出sequence的长度, P 2 × C P^2 \times C P2×C表示每个输入的维度;
- 对各个图像块应用线性变换得到其特征,假设特征维度为 d d d;这个过程称之为Patch Embedding;
- 类似于BERT中的做法,添加一个
class token,如Fig. 1中的*所示,表示输入图像的类别信息;添加的class token的维度也是 d d d; - 对各个图像块添加位置信息,如Fig. 1中的 0 , 1 , ⋯ , 9 0,1,\cdots,9 0,1,⋯,9所示;
- 将信息输入Transformer Encoder, 选取输出中第一个长度为 d d d的向量作为表示其类别的向量;
- 其输出再次送入MLP Head中,得到和gt label长度一致的类别信息。
整个处理过程用公式可以表示为:
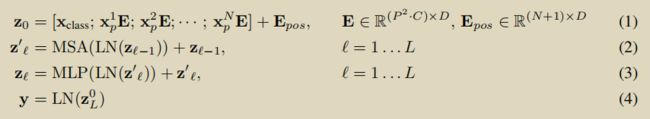
1.1 class token的作用
如果没有class token这个向量,假设9个向量输入Transformer Encoder,输出9个编码向量,然后呢?对于分类任务而言,我应该取哪个输出向量进行后续分类呢?
不知道。干脆就再来一个向量 x c l a s s x_{class} xclass,这个向量是可学习的嵌入向量,它和那9个向量一并输入Transfomer Encoder,输出1+9个编码向量。然后就用第0个编码向量,即 x c l a s s x_{class} xclass的输出进行分类预测即可。
这么做的原因可以理解为:ViT其实只用到了Transformer的Encoder,而并没有用到Decoder,而 x c l a s s x_{class} xclass的作用有点类似于解码器中的Query的作用,相对应的Key和Value就是其他9个编码向量的输出。
x c l a s s x_{class} xclass是一个可学习的嵌入向量,它的意义说通俗一点为:寻找 x c l a s s x_{class} xclass与其他9个输入向量的关联关系,训练过程迫使模型学习如何去做特征映射、如何去学习图像类别和各图像块的关联关系,从而能够最小化交叉熵损失,取得最高的分类准确率。
1.2 Positional Embedding
ViT中同样使用了Positional Embedding,只不过其具体值是学习得到的,而非预定义的。在代码中其初始值体现为参与训练的随机矩阵。
1.3 归纳偏倚(inductive bias)
ViT中使用的图像领域的归纳偏倚要比CNN中的少。在CNN中,使用了局部连接性质、二维方向上相邻像素点差异一般不大和平移不变性这三个归纳偏倚知识。但是在ViT中,只有MLP块是局部连接的和平移不变的,self-attention层则是利用了全局的信息。至于二维方向上相邻像素点差异不大的性质则只在开头对图像进行分块时和微调时针对不同分辨率的图像调整positional Embedding时进行了使用。
1.4 微调
一般情况下,在大规模的数据集上预训练ViT模型,然后在其他的需要更小分辨率的任务上进行微调。
微调时:
- 去除预训练的预测头MLP,添加一个新的 D × K D \times K D×K的前向传播层,K表示微调任务的类别数;
- 在微调时使用比预训练时更高分辨率的输入往往可以取得更好的结果,虽然输入分辨率增大,但送入Transformer Encoder中的图像块的大小保持不变,这就意味着输入的图像块的数量增多,即输入的长度变大。理论上,ViT可以接受内存允许时的任意长度的输入;
- 输入的长度增加后,原始预训练的Positional Encoding的长度就需要增加,具体的做法是按照各个图像块在原始图像中的位置对预训练的Positional Encoding进行2D插值得到新的Positional Encoding。
1.5 Hybrid结构
ViT的输入可以不是原始的图像块而是CNN输出的feature map。这种情况下,可以认为输入patch的大小为 1 × 1 1 \times 1 1×1。
2 实验
数据集:从小到大依次为 ILSVRC-2012 1K类别数据集(1.3 Million 图像)、ILSVRC-2012 21K类别数据集(14 Million 图像)和JFT 18K个类别,303 Million 高分辨率图像。
模型:三个模型,按照规模从小到大依次为ViT-Base、ViT-Large和ViT-Huge,细节如下表所示:
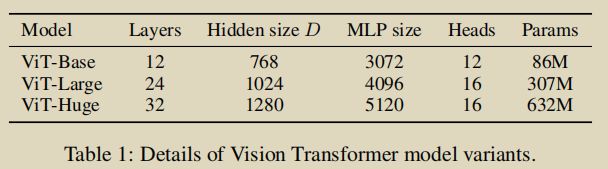
ViT-L/16表示使用ViT-Large模型,输入图像块的大小为 16 × 16 16 \times 16 16×16。
对照的CNN模型:ResNet(BiT),基于ResNet模型的变体,使用GN替换BN层且使用Weight standardization。
针对Hybirds实验,把CNN模型的中间层的feature map输入到ViT中,为了实验不同长度的feature map的影响,作者使用了两种特征:(1)使用ResNet50中stage 4的输出;(2)移除ResNet50中的stage 4,在stage 3中添加网络层,确保和移除stage 4前的网络层数量一致,这样得到的输出的长度是方式(1)的4倍,用于验证计算量更大时ViT模型的性能。
训练&微调:训练时所有模型使用Adam优化算法,batchsize=4096,weight decay=0.1,线性的学习率warm up和decay;微调时使用带momentum的SGD优化算法,batchsize=512.
实验一:与SOAT算法对比
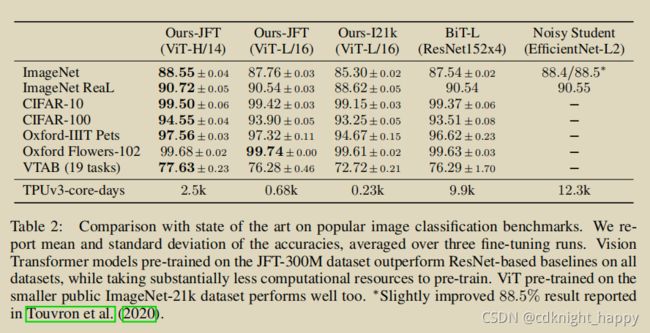 可以看出在JFT这种大规模数据集上,Huge ViT模型比ResNet效果要更好,且训练计算量更小。
可以看出在JFT这种大规模数据集上,Huge ViT模型比ResNet效果要更好,且训练计算量更小。
实验二:ViT对预训练数据集的要求
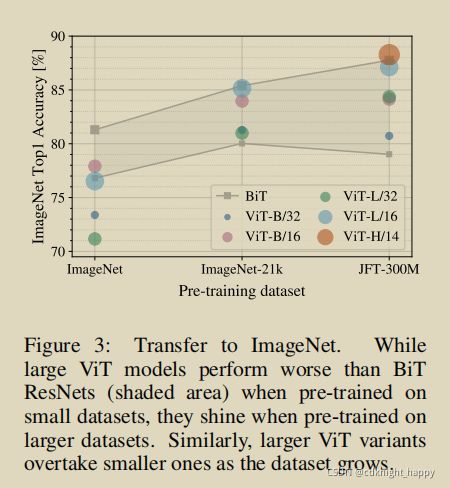 我们发现: 当在最小数据集ImageNet上进行预训练时,尽管进行了大量的正则化等操作,但ViT-大模型的性能不如ViT-Base模型,并且都不如ResNet-152;在稍微大一点的ImageNet-21k数据集上预训练,它们的表现差不多,但也都不如ResNet-152。只有到了JFT 300M,我们才能看到更大的ViT模型全部优势。 图3还显示了不同大小的BiT模型跨越的性能区域。BiT CNNs在ImageNet上的表现优于ViT(尽管进行了正则化优化),但在更大的数据集上,ViT超过了所有的模型,取得了SOTA。
我们发现: 当在最小数据集ImageNet上进行预训练时,尽管进行了大量的正则化等操作,但ViT-大模型的性能不如ViT-Base模型,并且都不如ResNet-152;在稍微大一点的ImageNet-21k数据集上预训练,它们的表现差不多,但也都不如ResNet-152。只有到了JFT 300M,我们才能看到更大的ViT模型全部优势。 图3还显示了不同大小的BiT模型跨越的性能区域。BiT CNNs在ImageNet上的表现优于ViT(尽管进行了正则化优化),但在更大的数据集上,ViT超过了所有的模型,取得了SOTA。
作者还进行了一个实验: 在9M、30M和90M的随机子集以及完整的JFT300M数据集上训练模型,结果如下图所示。
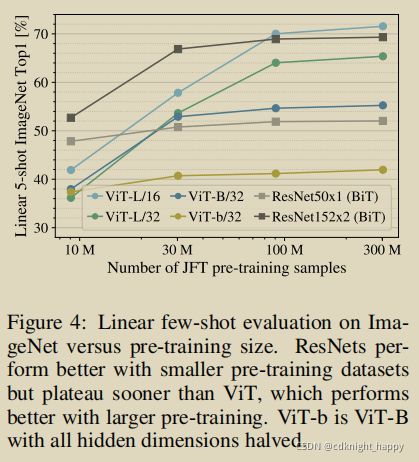
同样得出一个结论,在小规模数据集上,ViT-L不如ViT-Base且都不如ResNet。只有到了大规模数据集上,ViT-L才能超过ViT-Base并超过ResNet。也就是只有大规模的数据集才能体现出ViT的优势。
注意力区域:
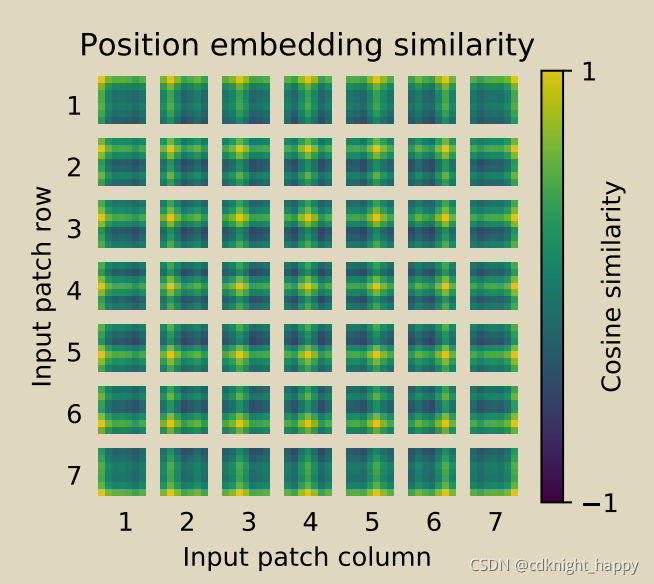
上图给出了对每个块学习的Positional Encoding和对应的块位置的相似度,可以看出学习的Positional Encoding明确表示了块的位置。
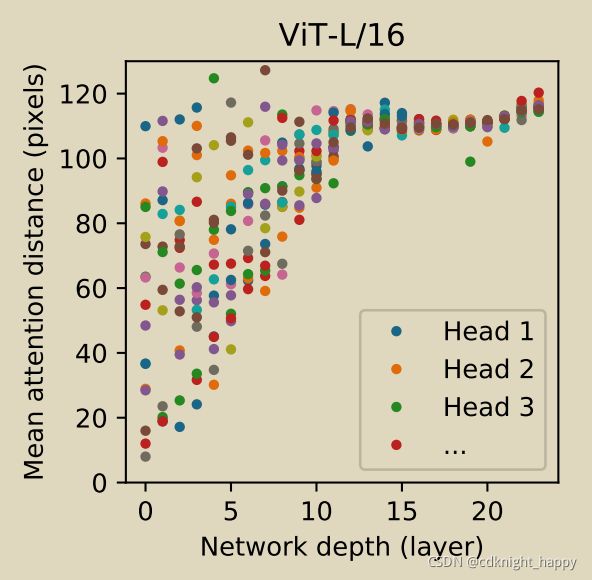
上图给出的是ViT各层attention的区域的平均大小。可以看出,在最底层, 有些head也已经注意到了图像的大部分,说明模型已经可以globally地整合信息了,说明它们负责global信息的整合。其他的head 只注意到图像的一小部分,说明它们负责local信息的整合。取得了CNN层次化学习的效果。

上图给出的是对于各输入图像的attention的区域,可以看出关注到了核心目标。
参考:
https://zhuanlan.zhihu.com/p/372692913
https://zhuanlan.zhihu.com/p/359071701
https://mp.weixin.qq.com/s?__biz=MzI5MDUyMDIxNA==&mid=2247535922&idx=1&sn=f4ea9fcee78ac604c03924e367844e85&chksm=ec1ca0cbdb6b29dd154fc54e28689dd9b074183920e9d7e0b675d9f9eb7946b8e45b94ab28d3&cur_album_id=1685054606675902466&scene=189#rd