Brain Tumor Segmentation (BraTS) 脑部肿瘤分割2--二维UNet的复现与数据准备篇
医学领域采集的图像,一般都是灰白色的,相比于现实空间中的彩色图像,存储的信息简单了很多。一个是1个维度的灰度信息,一个是3个维度组合到一起的彩色信息。
脑部肿瘤分割的这批数据,相较于其他的数据,有一个特别的地方,就是它是多模态的。尽管是4个不同的模态,但是都对应到一个标签。
此时不禁联想到:既然RGB三个通道的彩色图像,可以直接作为输入送进网络,能够学习到色彩的信息。那么,脑肿瘤采集的4个维度的信息,是不是也可以简单的把它拍在一起,构成一个每一层4个channel的图像,一次检查155层呢。
- 这样输入图像变成: 4 * 155 * 240 * 240,155层,每一层4个channel,每一个channel是240*240大小
- 输出还是原来的形式:155 * 240 * 240
此时,这个任务就没有了模态的概念了,就当做他是一个彩色多通道的图像来处理。也不要有体积的概念,他就是一个个二维的图像。尽管损失了很多内在联系的信息,但是,简单了很多啊。
- 没有上下层信息
- 淡化模态信息
简单的,直接用医学领域常用的unet网络模型作为训练的网络。后面我们就着重搭建复现unet网络模型,和数据读取部分。
1、复现unet
unet从整体结构上进行划分,大体可以分成两个阶段:
- 下采样的阶段,也就是U的左边
- 上采样的阶段,也就是U的右边
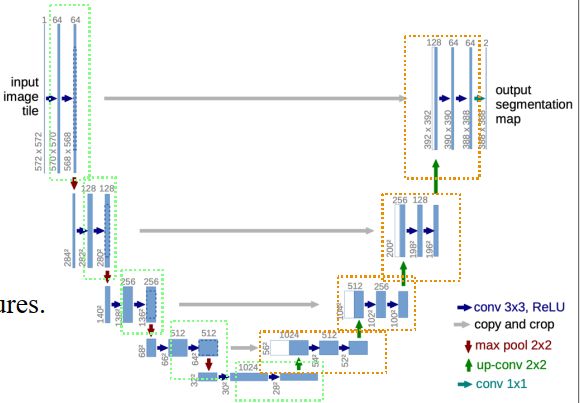
而下采样阶段,我们根据数据流动的方式,我们又分为5个的横向layer,每一个layer分别是有以下3个层串联组成:
- 1个红色箭头pool的层,标号A
- 2个3*3的卷积层,标号B
上采样阶段,也可以看成是4个横向的,具有相似结构的layer,每一个layer分别是有以下3个层串联组成:
- 1个向上变大的反卷积层(转置卷积),标号C
- 2个3*3的卷积层,标号B
除上面两个之外,还有一个跨层连接的残差结构,用于将下采样的数据传递给上采样阶段使用。避免下采样时候损失信息太多,帮助它恢复。
此时,再简单一些:我们不考虑跨层连接的残差结构,假设就是一个完整的串行,定义网络模型简单骨架版,大概是这样的:
class UNet2D(nn.Module):
def __init__(self, ):
super(UNet2D, self).__init__()
self.downLayer1 = B
self.downLayer2 = nn.Sequential(A,
B)
self.downLayer3 = nn.Sequential(A,
B)
self.downLayer4 = nn.Sequential(A,
B)
self.bottomLayer = nn.Sequential(A,
B)
self.upLayer1 = nn.Sequential(C,
B)
self.upLayer2 = nn.Sequential(C,
B)
self.upLayer3 = nn.Sequential(C,
B)
self.upLayer4 = nn.Sequential(C,
B)
self.outLayer = nn.Conv2d()
def forward(self, x):
x = self.downLayer1(x)
x = self.downLayer2(x)
x = self.downLayer3(x)
x = self.downLayer4(x)
x = self.bottomLayer(x)
x = self.upLayer1(x)
x = self.upLayer2(x)
x = self.upLayer3(x)
x = self.upLayer4(x)
x = self.outLayer(x)
return x
有了整体的结构,我们现在定义 B(2个3*3的卷积层)的结构,也就是上图中绿色矩形框的部分。如下:
class ConvBlock2d(nn.Module):
def __init__(self, in_ch, out_ch):
super(ConvBlock2d, self).__init__()
# 第1个3*3的卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
)
# 第2个3*3的卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
)
# 定义数据前向流动形式
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
B的结构比较的简单,这里我就不赘述了,一看便知。卷积之后,接数据归一化,再接激活函数,重复上述过程两次,就是B干的事情。
在卷积神经网络的卷积层之后总会添加
BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
为啥要单独定义B?因为,单独定义的目的是为了复用,避免出现重复书写的繁琐过程。尤其是卷积后面都喜欢配上Norm和激活函数,这样就能少些一些代码。(简洁、也就是懒)
受此启发,C的反卷积结构,是不是也要单独定义下。如下:
class ConvTrans2d(nn.Module):
def __init__(self, in_ch, out_ch):
super(ConvTrans2d, self).__init__()
self.conv1 = nn.Sequential(
nn.ConvTranspose2d(in_ch, out_ch, kernel_size=3, stride=2, padding=1, output_padding=1, dilation=1), # 转置卷积、反卷积
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.conv1(x)
return x
有了B的基础结构,下采样阶段的A和B都定义清楚了。前文定义上采样的模型时候不考虑跨层连接的残差结构,假设就是一个完整的串行。此时需要看到他从U的左边传过来的数据,那实施上采样阶段的一个简单模块是这样的:
- 反卷积
- 与跨层输入进行连接
- 传入B结构
最终上采样的一个模块,可以写成这样:
class UpBlock2d(nn.Module):
def __init__(self, in_ch, out_ch):
super(UpBlock2d, self).__init__()
self.up_conv = ConvTrans2d(in_ch, out_ch)
self.conv = ConvBlock2d(2 * out_ch, out_ch)
def forward(self, x, down_features):
x = self.up_conv(x)
x = torch.cat([x, down_features], dim=1)
x = self.conv(x)
return x
至此,缺失的部分,我们都给填补上去了,网络结构中还有一些信息是需要我们罗列下的:
- channel的变化是1 -> 64 -> 128 -> 256 -> 512 -> 1024 -> 512 -> 256 -> 125 -> 64 -> 2
- 卷积核是3*3
- pool是max pool
- 激活函数是relu
这样,我们就可以改写前面简单版本定义模型的类了,如下:
class UNet2D(nn.Module):
def __init__(self, in_ch=4, out_ch=2, degree=64):
super(UNet2D, self).__init__()
chs = []
for i in range(5):
chs.append((2 ** i) * degree) # [64, 128, 256, 512, 1024]
self.downLayer1 = ConvBlock2d(in_ch, chs[0])
self.downLayer2 = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
ConvBlock2d(chs[0], chs[1]))
self.downLayer3 = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
ConvBlock2d(chs[1], chs[2]))
self.downLayer4 = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
ConvBlock2d(chs[2], chs[3]))
self.bottomLayer = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
ConvBlock2d(chs[3], chs[4]))
self.upLayer1 = UpBlock2d(chs[4], chs[3])
self.upLayer2 = UpBlock2d(chs[3], chs[2])
self.upLayer3 = UpBlock2d(chs[2], chs[1])
self.upLayer4 = UpBlock2d(chs[1], chs[0])
self.outLayer = nn.Conv2d(chs[0], out_ch, kernel_size=3, stride=1, padding=1)
# # Params initialization
# for m in self.modules():
# if isinstance(m, nn.Conv2d):
# n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# m.weight.data.normal_(0, math.sqrt(2. / n))
# elif isinstance(m, nn.BatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_()
def forward(self, x):
"""
:param x: 4D Tensor BatchSize * 4(modal) * W * H
:return: 4D Tensor BatchSize * 2 * W * H
"""
x1 = self.downLayer1(x) # degree(32) * 16 * W * H
x2 = self.downLayer2(x1) # degree(64) * 16/2 * W/2 * H/2
x3 = self.downLayer3(x2) # degree(128) * 16/4 * W/4 * H/4
x4 = self.downLayer4(x3) # degree(256) * 16/8 * W/8 * H/8
x5 = self.bottomLayer(x4) # degree(512) * 16/16 * W/16 * H/16
x = self.upLayer1(x5, x4) # degree(256) * 16/8 * W/8 * H/8
x = self.upLayer2(x, x3) # degree(128) * 16/4 * W/4 * H/4
x = self.upLayer3(x, x2) # degree(64) * 16/2 * W/2 * H/2
x = self.upLayer4(x, x1) # degree(32) * 16 * W * H
x = self.outLayer(x) # out_ch(2 ) * 16 * W * H
return x
到这里,unet结构的复线部分就构建完毕了,不知道你有没有理解上面分拆的一个个结构。可以把构建网络的过程,理解为搭积木。
- 把长相一样的,给整理到一起
- 把有方向信息的,整理到一起
- 实在很独特的,就单独定义了插进来
定义好了模型还不算完,分阶段测试下构建的网络是不是和我们所预想的一样。我们给他一个输入,测试下是否与我们最初的想法是一致的,是否报错等等问题,如下:
if __name__ == "__main__":
net = UNet2D(4, 5, degree=64)
print(net)
print("total parameter:" + str(netSize(net)))
batch_size = 4
a = torch.randn(batch_size, 4, 240, 240)
print(a.shape) # (batch_size, 4, 240, 240)
b = net(a)
print(b.shape) # (batch_size, 5, 240, 240)
这时,你就可以看看,打印的网络模型,是不是和这张图的结构式完全一样的。改变网络的输入层,输出类别,或者每一层的channel数,看看参数量的变化。如下这样
net = UNet2D(4, 5, degree=64)
打印结果:
total parameter:34530437
torch.Size([4, 4, 240, 240])
torch.Size([4, 5, 240, 240])
也可以输入的channel设定为1,如下:
net = UNet2D(1, 5, degree=64)
打印结果:
total parameter:34528709
torch.Size([4, 1, 240, 240])
torch.Size([4, 5, 240, 240])
当然,你也可以更改degree的值,如下:
net = UNet2D(4, 5, degree=128)
打印结果:
total parameter:138070277
torch.Size([4, 4, 240, 240])
torch.Size([4, 5, 240, 240])
同理,也可以改输出类别,把之前的5类,给改成3类,如下:
net = UNet2D(4, 3, degree=64)
输出结果:
total parameter:34529283
torch.Size([4, 4, 240, 240])
torch.Size([4, 3, 240, 240])
上面几处内容的改变,会发现都伴随着模型参数量的改变。有些改变比较大,有些比较小,值得关注下。
2、构建数据流
在数据篇中,了解到4个模态,每一个模态存储的都是一个3维数据。而上文网络输入是一个(batch_size, channel=4, width, height),没有了Z轴的维度信息。所以,在构建数据的时候,需要按Z轴,将每一层单独拿出来,组成新的数据形式。
- 读取数据,区分图像和标签
- 处理成图像(channel, width, height)和标签(width, height)形式
在pytorch的训练数据处理中,以下这段内容,可以作为嵌套的依据:
class Brats15DataLoader(Dataset):
def __init__(self, data_dir, train=True):
self.data = []
if train:
self.data ···
else:
self.data ···
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# ********** get file dir **********
image, label = self.data[index] # get whole data for one subject
# ********** change data type from numpy to torch.Tensor **********
image = torch.from_numpy(image).float()
label = torch.from_numpy(label).float()
return image, label
简单点就是干这么3件事情:
- 告诉我数据在哪里,我好去读取
- 有了数据,处理成模型需要feed的数据形式,按index一个一个的返回
- 返回数据长度,好知道一次循环结束了
插入一点内容:创建Brats15DataLoader类中__len__和__getitem__方法,可以类比创建列表的时候,是实现了一个列表对象的实例化a_list。
- len(a_list)函数实际上是调用列表类中的私有方法
__len__() - 用列表索引的时候a_list[1],实际上是调用了
__getitem__()方法,传入的index=1
直接将代码放到这里,注释部分加入了自己的学习和理解,如存在问题,欢迎评论区交流。
# coding:utf-8
from torch.utils.data import Dataset
from src.utils import *
modals = ['flair', 't1', 't1c', 't2']
class Brats15DataLoader(Dataset):
def __init__(self, data_dir, conf='../config/train15.conf', train=True):
img_lists = []
train_config = open(conf).readlines()
for data in train_config:
img_lists.append(os.path.join(data_dir, data.strip('\n'))) # 获取图像列表
print('\n' + '~' * 50)
print('******** Loading data from disk ********')
self.data = []
self.freq = np.zeros(5) # 频率 array([0., 0., 0., 0., 0.])
self.zero_vol = np.zeros((4, 240, 240)) # 初始化 volume 大小
count = 0
for subject in img_lists: # 逐文件获取全部数据
count += 1
if count % 10 == 0:
print('loading subject %d' % count)
volume, label = Brats15DataLoader.get_subject(subject) # 4 * 155 * 240 * 240, 155 * 240 * 240 ******重点*****
volume = norm_vol(volume) # 归一化
self.freq += self.get_freq(label)
if train is True:
length = volume.shape[1] # length = 155, 4 * 155 * 240 * 240
for i in range(length): # 沿Z轴逐层扫描
name = subject + '=slice' + str(i)
# 如果当前层的内容为空,则跳过
# all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是,返回 True;否,返回 False。
if (volume[:, i, :, :] == self.zero_vol).all(): # when training, ignore zero data
continue
else:
self.data.append([volume[:, i, :, :], label[i, :, :], name]) # self.data.append([4,240,240], [240, 240], name)
else:
volume = np.transpose(volume, (1, 0, 2, 3))
self.data.append([volume, label, subject])
self.freq = self.freq / np.sum(self.freq)
self.weight = np.median(self.freq) / self.freq # np.median中位数
print('******** Finish loading data ********')
print('******** Weight for all classes ********')
print(self.freq)
print(self.weight)
if train is True:
print('******** Total number of 2D images is ' + str(len(self.data)) + ' **********')
else:
print('******** Total number of subject is ' + str(len(self.data)) + ' **********')
print('~' * 50)
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# ********** get file dir **********
[image, label, name] = self.data[index] # get whole data for one subject
# ********** change data type from numpy to torch.Tensor **********
image = torch.from_numpy(image).float() # Float Tensor 4, 240, 240
label = torch.from_numpy(label).float() # Float Tensor 240, 240
return image, label, name
"""
一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法。
而使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用。
这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁。
"""
# 单个文件处理
@staticmethod
def get_subject(subject):
"""
:param subject: absolute dir
:return:
volume 4D numpy 4 * 155 * 240 * 240
label 4D numpy 155 * 240 * 240
"""
# **************** get file ****************
files = os.listdir(subject) # [XXX.Flair, XXX.T1, XXX.T1c, XXX.T2, XXX.OT] T2加权液体衰减反转恢复(FLAIR)、T1加权(T1)、T1加权对比增强(T1c)、T2加权(T2)、OT-label
multi_mode_dir = [] # 图像文件名
label_dir = "" # 标签文件名
for f in files:
if f == '.DS_Store':
continue
if 'Flair' in f or 'T1' in f or 'T2' in f: # if is data, (.Flair, .T1, .T1c, .T2)
multi_mode_dir.append(f)
elif 'OT.' in f: # if is label
label_dir = f
# ********** load 4 mode images **********
multi_mode_imgs = [] # list size :4 item size: 155 * 240 * 240
for mod_dir in multi_mode_dir:
path = os.path.join(subject, mod_dir) # absolute directory
img = load_mha_as_array(path)
multi_mode_imgs.append(img)
# ********** get label **********
label_dir = os.path.join(subject, label_dir)
label = load_mha_as_array(label_dir)
volume = np.asarray(multi_mode_imgs)
return volume, label
def get_freq(self, label):
"""
:param label: numpy 155 * 240 * 240 val: 0,1,2,3,4
:return:
"""
class_count = np.zeros((5)) # array([0., 0., 0., 0., 0.])
for i in range(5):
a = (label == i) + 0 # label维度的 0 or 1 数组
class_count[i] = np.sum(a) # 有就对应类别位置+1
return class_count
# test case
if __name__ == "__main__":
data_dir = '../data_sample/'
conf = '../config/sample15.conf'
# test data loader for training data
brats15 = Brats15DataLoader(data_dir=data_dir, conf=conf, train=True)
print(len(brats15))
image2d, label2d, im_name = brats15[70]
print('image size ......')
print(image2d.shape) # (4, 240, 240)
print('label size ......')
print(label2d.shape) # (240, 240)
print(im_name)
name = im_name.split('/')[-1]
save_one_image_label(image2d, label2d, 'img5/img_label_%s.jpg' % name)
# test data loader for testing data
brats15_test = Brats15DataLoader(data_dir=data_dir, conf=conf, train=False)
print(len(brats15_test))
image_volume, label_volume, subject = brats15_test[0]
print(image_volume.shape)
print(label_volume.shape)
print(subject)
打印结果如下:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
******** Loading data from disk ********
******** Finish loading data ********
******** Weight for all classes ********
[9.87486111e-01 2.95374104e-03 5.94198029e-03 9.16218638e-05
3.52654570e-03]
[3.57123575e-03 1.19392515e+00 5.93496701e-01 3.84902200e+01
1.00000000e+00]
******** Total number of 2D images is 132 **********
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
132
image size ......
torch.Size([4, 240, 240])
label size ......
torch.Size([240, 240])
../data_sample/HGG/brats_2013_pat0001_1=slice80
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
******** Loading data from disk ********
******** Finish loading data ********
******** Weight for all classes ********
[9.87486111e-01 2.95374104e-03 5.94198029e-03 9.16218638e-05
3.52654570e-03]
[3.57123575e-03 1.19392515e+00 5.93496701e-01 3.84902200e+01
1.00000000e+00]
******** Total number of subject is 1 **********
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1
torch.Size([155, 4, 240, 240])
torch.Size([155, 240, 240])
../data_sample/HGG/brats_2013_pat0001_1
其中保存一个index的图像内容如下:

3、总结
本文代码部分参考自GitHub,完整代码可以点击下方链接直达。在上文部分,着重对学习过程的主要代码进行了描述,其他辅助的功能函数,还需要你自行学习。
参考GitHub:stm_multi_modal_UNet
下一章博客是对训练的主函数做个简单的介绍,还有训练和测试过程做个描述。本文的数据处理和网络复现部分最为重要,所以篇幅较多。
作者提供了解决一个问题的多个思路和角度,这种对问题的分析方式,值得我好好学习和思考。于是对论文和代码部分进行学习、训练之余,分享给大家进行参考。
也希望大家对其中不对的地方多多在评论区批评指正,谢谢。