论文笔记(七)Learning from Longitudinal Face Demonstration - Where Tractable Deep Modeling Meets Inverse
这篇文章是关于逆强化学习的应用,主要是实现了人脸的老化,是最近发表在arxiv上的文章。
 论文地址
论文地址
本文主要是对这篇文章阅读过程的笔记。
一、论文笔记
0 摘要:
(1)本文提出的方法为Subject-dependent Deep Aging Path(SDAP),依赖目标的深度老化方法,结合了产生式模型和逆强化学习模型的优点。该模型能生成面部的结构并给出该目标纵向的老化过程。 longitudinal:纵向的。
(2)SDAP通过采用深度特征提取网络来实现对数似然函数的可处理性。
(3)相比固定的人脸老化过程,SDAP采用最优的老化奖励函数实现对不同的人脸进行最佳的老化过程。
(4)SDAP可以接受多张图片作为输入,获取目标相同或者不同的年龄信息,从而给出最佳的老化过程。
(5)该模型在人脸老化合成和交叉年龄人脸验证。
face verification 人脸验证 1:1匹配问题,给定人脸图片和身份,在人脸数据库进行人脸比对,验证该人脸是不是该身份。
face recognition 人脸识别 1:n匹配问题,给定人脸图片,从人脸数据库中找到与其相似度最高的人脸,确定其身份。
1 引言:
(1)人脸老化合成可以应用在年龄无关的人脸验证、寻找失踪儿童、美容美妆行业。
(2)传统的深度学习方法大多集中在两个方向:直接老化合成和循序渐进的老化合成。
对于第一种方向,通过训练集与对应的年龄标签之间的关系进行合成。例如传统方法(prototyping approaches)利用年龄标签将人脸进行分组,计算不同年龄组人脸的平均值,然后将源年龄和目标年龄组之间的差异应用到输入的人脸,从而得到目标年龄的人脸。此外,GAN的方法是通过获取输入人脸高维的表示与年龄标签之间关系,根据年龄标签通过生成器合成老化人脸。
直接合成方法的缺点在于只能合成训练集中年龄范围的人脸,无法生成更老的照片。而且合成效果不是很好。
对于第二种方向,是将长期的老化过程进行分解,重点关注两个连续年龄阶段之间人脸老化的转化。通过学得的转化方式,将输入人脸从一个年龄阶段处理到下一个阶段直到目标年龄阶段。这种方式可以有效地学习暂时的信息(temporal information)并且提供更多的年龄变化细节,即使目标年龄距离输入年龄很远。 这种方法最大的局限性在于缺少纵向的人脸老化数据库,训练的过程通常只有每个人的三四张人脸图片。
对于以前方法与作者提出方法比较如下图所示:

文中作者对比较的结果进行总结:
1.非线性。人脸老化是复杂且是高度非线性的过程,采用线性的方法如基于原型法、AAMs、3DMM是有局限性的。
2.深度学习框架的损失函数。采用固定的损失函数会产生模糊的结果。
3. 可处理性。 采用概率图模型(Probabilistic Graphical Models,PGM)可以更好地完成人脸老化任务。
PGM基本可以分为两个类别:贝叶斯网络(有向图)和马尔科夫随机场(无向图),通过概率图来描述变量之间的关系,以此建模来推导求解问题。
4.数据利用情况。往往只会用同一年龄的一张图片,造成其他图片的浪费。
5.固定的老化发展路径。 学得的老化发展路径应用所有人在实际情况是不合理的,应该每个个体都有自己的年龄老化发展路径。
(3)本文的贡献:
1.对老化转换嵌入过程进行修改。(aging transformation embedding,应该是人脸老化合成中的方法,是专有的叫法。)具体而言,可计算的对数似然估计、采用CNN卷积网络、age controller年龄控制器来反应年龄改变了多少次。
因此,SDAP提供了平滑的合成过程,并且能够最大化人脸年龄数据的使用率,同一个体不同年龄或者相同年龄的所有照片都可以进行利用。
2.为每一个个体寻找最佳年龄发展路径。这个目标可以通过逆强化学习(IRL)实现。
3.在训练中通过数据驱动的策略(data driven strategy)自动得出最优的目标函数和参数。
2 相关工作:
1.人脸年龄问题包括年龄估计(age estimation)和年龄进程(age progression)问题。
2.年龄进程(Age Progression)解决方法可以分为四类:模型法(modeling)、重建法(reconstruction)、原型法(prototyping)、基于深度学习的方法(deep learning-based methods)。文章对四种方法进行简要介绍,有需要可以自行看原论文。
个人理解这种问题是为展示人脸老化的过程,针对不同年龄组之间的差异进行分析,逐步将输入人脸向目标年龄靠近。
3.年龄估计(Age Estimation),目前的年龄估计方法通常包括两部分:年龄特征提取模块和年龄预测模块。
个人觉得age progression包含age estimation,想要完成从输入人脸转化成目标年龄人脸需要进行年龄估计的操作。
3 SDAP介绍:
1.先是讲TNVP的不足,毕竟SDAP是在TNVP的基础上发展而来,TNVP的不足一是在于没有关注老化过程长期的关系,二是没有针对不同的个体进行不同的老化过程。
其实,SDAP最大的亮点为不同的个体选择不同的老化的过程。
2.age controller提供了主要的功能,在合成过程中判断多少年龄差异需要添加,从而为不同的个体选择不同的老化过程。
3.采用逆强化学习的方法将老化转化方法嵌入到长期的年龄序列中,从而有效反映主体的长期老化发展过程。
图片合成部分: Aging Embedding with Age Controller :
三部分组成,潜在空间映射、老化转化、年龄控制器。

mapping function就是潜在空间映射;aging transformation是老化转化过程;a就是年龄控制器(age controller)。
结合公式讲一下大体流程:

x属于输入人脸,f1和f2是映射函数,τ是x编码后的表示(个人觉得没必要格外强调),z就是潜在变量,G是转化过程。
x1输入经过f1得到潜在变量z1,x2经过f2得到潜在变量z‘2(还不是完全的z2)。【映射过程】
z1和a1经过G得到g1,g1与z'2结合得到真正的潜在变量z2。【转化过程,同时年龄控制器发挥作用】。
对于年龄控制器与aging transformation的结合单独进行了讲解:
![]() 和
和![]() 经过G(aging transformation)为:
经过G(aging transformation)为:

之后,对于![]() 有:
有:![]()
以上便是一个合成单元的流程,相当于由x1最终得到了z2。
年龄控制器(公式2) 起到的作用:1、a为one-hot变量,起到了控制不同参数的作用。因此,能够决定多少的年龄信息嵌入到老化的过程中。2、给定年龄控制器,模型能够使用同一目标的所有照片来进行训练,增强模型的表现能力。
在实际操作中,三维矩阵的参数太多,因此,w可以由三维矩阵分解为三个矩阵。
由![]() 变成
变成![]()
因此,公式2可以转换成:
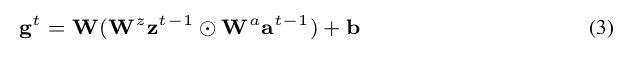
 代表Hadamard product(哈达玛积),简单而言就是A矩阵和B矩阵的对应元素相乘得到一个新矩阵。
代表Hadamard product(哈达玛积),简单而言就是A矩阵和B矩阵的对应元素相乘得到一个新矩阵。
对数-似然函数(the log-likelihood):

理解:对于似然函数![]() ,有上面的流程可知,
,有上面的流程可知,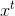 取决于
取决于![]() 。其中
。其中 是映射F和G的参数。
是映射F和G的参数。
公式右边从第一步到第二步为概率分布映射后需要乘一个雅克比矩阵。
第二步到第三步就是条件概率的推导。
因此,对数-似然函数可以表示为:
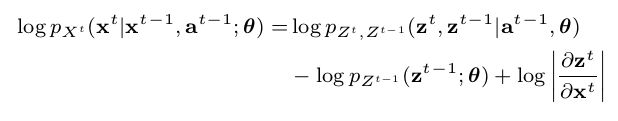
联合分布概率:
论文看到这有个疑问,怎么感觉用到了流模型呢?
为了确保对老化流过程建模,将高斯分布作为pz的先验分布。年龄控制器变量a也设置为高斯分布,使用![]() 来表示a。
来表示a。
潜在变量组合![]() 都为高斯分布,均值为
都为高斯分布,均值为![]() ,方差为
,方差为![]()
所以,潜在变量![]() 表示为:
表示为:

公式(5)结合公式(3)会好理解一点,就是将公式(3)拆分成均值方差的形式再加上![]() 的均值方差形式。
的均值方差形式。
因为![]() 属于不同的高斯分布,作者假设他们的联合分布仍然是高斯分布。因此有:
属于不同的高斯分布,作者假设他们的联合分布仍然是高斯分布。因此有:

目标函数:

最大化对数似然函数,找到其值最大时的θ参数值。等式右边第二项是限制条件,令年龄限制器a为高斯分布。
逆强化学习部分:年龄序列中的逆强化学习部分(IRL Learning from Aging Sequence):
1、通过定义个体独立的老化策略网络(subject-dependent deep aging policy network)来为年龄控制器提供一个可计划的老化路径(planning aging path)。从而保证输入图片x都能有最佳的老化发展过程。
2、能量函数(energy function)多次见过这个函数的出现,这次只是从容易理解的角度来解释,不涉及数学原理。
首先是通过能量函数能引入一系列的概率分布函数。为什么呢?首先理解能量模型,在能量模型中,个体所处的状态对应着一个能量,这个能量由能量函数来定义。这个个体处于某种状态的概率可以通过该状态下具有的能量来定义。因此能量和概率有了联系。
举个例子而言,弹玻璃球。在坑坑洼洼的地面上,弹一下玻璃球,它最终停下的位置有很多种可能性,在能量模型中,每个不同的位置对应一个能量,而玻璃球有着不同的概率最终停在不同的位置,因此可以用该位置下的能量来表示对应的概率。这就是我的理解。
对于能量函数,系统越有序或概率分布越集中,系统的能量越小。相反,系统越无序或概率分布越均匀,系统的能量越大。能量函数的最小值对应系统最稳定的状态。

这是文中给出的能量函数与概率分布的公式。其基本公式形式就是如此,变化的是他们的变量。
其中:![]() 代表第i个个体的观测到的年龄序列,共M个年龄序列;
代表第i个个体的观测到的年龄序列,共M个年龄序列;![]() 代表能量函数,参数为τ;
代表能量函数,参数为τ;![]() 为归一化因子,也称为配分函数(partition function)。
为归一化因子,也称为配分函数(partition function)。
此时的P(ζ)相当于待优化的似然函数。
因此,目标是学得最大化似然函数时的参数τ。

3、为何是逆强化学习(IRL)而不是强化学习(RL)
在公式8中,能量函数E(ζ)如果被认为是奖励函数的一种形式,那么问题等价于给定一系列的年龄序列ζ,从而强化学习一个策略。
奖励函数是基于策略的强化学习中的关键元素,但是对于人脸老化过程而言,预先定义一个合理的奖励函数是不现实的。事实上,即使给定某一个体所有年龄的照片也是很难去度量一个最优的年龄老化过程。因此,与其定义一个add-hoc(点对点?也不知道什么意思)的年龄奖励函数,不如令E(ζ)能量函数作为非线性的损失函数,转化为逆强化学习的问题。
在这个逆强化学习系统中,参数τ可以直接从观测到的年龄序列ξ学到。给定一系列的年龄序列作为示范,通过最大化给定的年龄序列的对数似然,不仅可以优化损失函数,还可以优化策略,为每个个体预测最佳的老化路径。
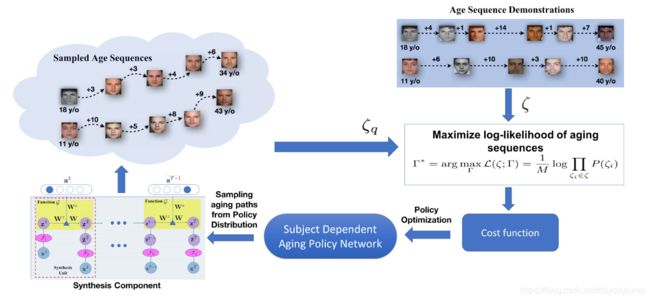
上图代表加入逆强化学习的流程图。
4、逆强化学习过程可以进行以下描述。马尔科夫决策过程为M{S,A,T,ζ,E} 。其中{S,A,T}代表状态空间、动作空间、转换过程。ζ代表给定的年龄序列(专家示范)。E代表损失函数。我们的目标是通过示范ξ发现损失函数E,同时最小化损失函数得到最佳的策略 。
State:![]() ,两部分:x输入人脸;age年龄标签。
,两部分:x输入人脸;age年龄标签。
Action:与年龄控制器类似,对于状态s,动作a定义为对s执行多大程度的老化变化。 a是从动作概率分布中随机取样。在测试过程,给定目前状态,选取最高概率的动作进行合成操作。因为使用的数据集年龄最大的跨度为15,所以选择Na = 16.
Cost Function:对于输入s和a,损失函数将其映射为![]() ,因此,损失函数为
,因此,损失函数为 ![]()
Policy: 策略可以表示为高斯轨迹分布。如公式9所示。
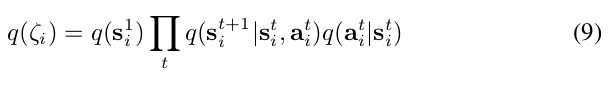
结合公式7和8,损失函数为:
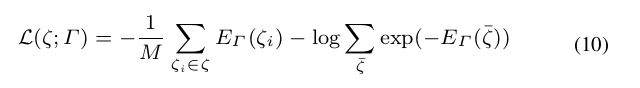
计算过程为将公式7代入公式8,然后累乘展开之后变成累加,就能得到公式10。
因为计算配分函数是困难的,(因为计算所有的可能情况是困难的,给出的专家示范本身就是某个目标老化的一部分,所以相当于进行采样。)因此采用基于采样的方式来估计配分函数(公式右侧第二项)的值。因此有:

采样的分布为q(ζ),N代表取样的个数。因此待求梯度(对τ求导)可以表示为:

因此,q的分布如何选择是十分关键的。它可以是通过调节进行优化,首先初始化一个均匀分布,然后通过三个步骤的优化过程迭代进行优化。过程为:1、根据初始分布生成一系列的老化序列ζ;2、通过公式11优化损失函数;3、 通过公式12重新定义分布q 。
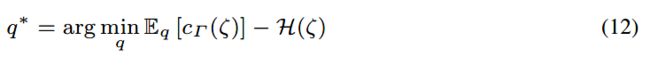
对于公式12的解决方法采用了论文Learning Neural Network Policies with Guided Policy Search under Unknown Dynamics的方法,是一种策略搜索方法。
算法1展示了整个策略学习的步骤:

上图展示了整个拟强化学习的流程。简单而言,就是给出专家示范,同时根据示范的第一个状态进行合成,然后通过专家示范序列和合成序列对参数和采样的序列分布进行更新。
5 讨论:
第4部分讲的是模型的优点,其实第5部分也算是进一步介绍优点,只不过是加上了对比。
与基于GAN方法的比较:
第一,SDAP对非线性的变换提供了更强的控制能力。
第二,为不同的个体提供不同的老化过程。传统的方法有可能将相同的老化特征放在不同的目标上,导致生成图片质量不佳。
第三,基于GAN方法的年龄判别器只能分辨年轻和年老的区别,只是粗糙地将合成图片和年龄标签结合在一起。在SDAP的逆强化学习过程中,年龄标签(精确到年)是被包含在状态的定义中,所以合成图片和标签的关系会紧密地结合在一起。在整个学习过程中发挥作用。
6 实验:
数据集选取了好多个,并且进行处理,只用了正面人脸。
模型的设置大体可以分为两个网络,生成网络和策略网络。
对于强化学习的模型提到了rllab,是一个发展和评估强化学习算法的框架。之后会好好看一下。
二、个人感受
合成的流程感觉比较像流模型,但是加上了逆强化学习进行控制,保证不同目标可以有不同的发展路径。确实思路比较好,可以考虑应用一下。