YOLOv5、v7改进之三十九:引入改进遮挡检测的Tri-Layer插件 | BMVC 2022
前 言:作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注文末公众号即可免费领取深度学习算法资料!
解决问题:不同的目标检测应用场景有不同的检测难点,之前解决过小目标、多尺度以及背景复杂等问题,本文尝试解决待测目标相互遮挡带来的检测困难。应用场景常常在行人检测、鱼类目标检测等很多地方,针对这个检测难点所来带来的错漏检问题,此前曾采用改进非极大值抑制的方法,引入soft-nms取得一定的效果,本文尝试引入最新的BMVC2022中的论文提出的Tri-Layer来改善算法的检测效果,从而进行适应性改进,可以作为文章的创新点之一用于发论文使用,供读者参考。
基本原理:
检测被遮挡的物体仍然是最先进的物体检测器面临的挑战。这项工作的目标是改进对此类对象的检测,从而提高现代对象检测器的整体性能。为此,我们做了以下四个贡献:(1)我们提出了一个简单的“plu-gin”模块,用于两级目标检测器的检测头,以提高部分遮挡对象的召回率。该模块预测目标对象、遮挡物和被遮挡物的三层分割遮罩,这样可以更好地预测目标对象的遮罩。(2) 我们提出了一种可扩展的管道,用于通过使用现有对象检测和实例分割训练数据集的近似完成来为模块生成训练数据,以建立遮挡关系。(3) 我们还建立了一个COCO评估数据集来测量部分遮挡和分离对象的召回性能。(4) 我们表明,插入到两级检测器中的插件模块可以显著提高性能,只需微调检测头即可,如果整个架构得到微调,还可以进行额外的改进。COCO结果被重新报告给带有Swin-T或Swin-S骨干的掩码R-CNN,以及带有Swin-B骨干的级联掩码R-CN。

模块的架构和功能

原论文进行了彻底的实验,以验证插件中不同模块的有效性。如下表所示,进行了以下观察:1)三层建模:在阻塞COCO的召回方面带来了显著改善(B1至B3,+75,仅微调掩模头;B1至C2,+96,微调整个网络);2) 方框调整:为BBox mAP提供了显著的性能提升,例如,从B1到B2,仅微调头为+1.9,微调网络为从B1到C1,+2.3;3) RoI功能重新加权:进一步改进了Mask mAP、Recall on Occluded COCO和Recall on Separated COCO(+0.3/+10/+21仅用于微调头部,+0.1/+7/+15用于微调整个网络),如模型所示,从B4到B5,从C3到C4;4) 微调整个网络:通常可以改善所有评估指标,例如,将B2-B5与C1-C4进行比较。值得注意的是,只有微调头部才能对大部分改进做出贡献,从而验证原论文提出的模块作为通用“插件”的有效性,该插件可以插入预先训练的检测器中,并快速提高性能。
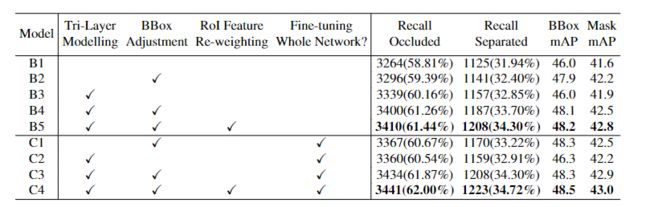
消融实验
添加方法:
部分代码如下,完整代码以及添加方法请关注公众号“人工智能AI算法工程师”,私信后领取。
#!/usr/bin/env python
import os
from setuptools import find_packages, setup
import torch
from torch.utils.cpp_extension import (BuildExtension, CppExtension,
CUDAExtension)
def readme():
with open('README.md', encoding='utf-8') as f:
content = f.read()
return content
version_file = 'mmdet/version.py'
def get_version():
with open(version_file, 'r') as f:
exec(compile(f.read(), version_file, 'exec'))
return locals()['__version__']
def make_cuda_ext(name, module, sources, sources_cuda=[]):
define_macros = []
extra_compile_args = {'cxx': []}
if torch.cuda.is_available() or os.getenv('FORCE_CUDA', '0') == '1':
define_macros += [('WITH_CUDA', None)]
extension = CUDAExtension
extra_compile_args['nvcc'] = [
'-D__CUDA_NO_HALF_OPERATORS__',
'-D__CUDA_NO_HALF_CONVERSIONS__',
'-D__CUDA_NO_HALF2_OPERATORS__',
]
sources += sources_cuda
else:
print(f'Compiling {name} without CUDA')
extension = CppExtension
return extension(
name=f'{module}.{name}',
sources=[os.path.join(*module.split('.'), p) for p in sources],
define_macros=define_macros,
extra_compile_args=extra_compile_args)
def parse_requirements(fname='requirements.txt', with_version=True):
"""Parse the package dependencies listed in a requirements file but strips
specific versioning information.
Args:
fname (str): path to requirements file
with_version (bool, default=False): if True include version specs
Returns:
List[str]: list of requirements items
CommandLine:
python -c "import setup; print(setup.parse_requirements())"
"""
import sys
from os.path import exists
import re
require_fpath = fname
def parse_line(line):
"""Parse information from a line in a requirements text file."""
if line.startswith('-r '):
# Allow specifying requirements in other files
target = line.split(' ')[1]
for info in parse_require_file(target):
yield info
else:
info = {'line': line}
if line.startswith('-e '):
info['package'] = line.split('#egg=')[1]
elif '@git+' in line:
info['package'] = line
else:
# Remove versioning from the package
pat = '(' + '|'.join(['>=', '==', '>']) + ')'
parts = re.split(pat, line, maxsplit=1)
parts = [p.strip() for p in parts]
info['package'] = parts[0]
if len(parts) > 1:
op, rest = parts[1:]
if ';' in rest:
# Handle platform specific dependencies
# http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
version, platform_deps = map(str.strip,
rest.split(';'))
info['platform_deps'] = platform_deps
else:
version = rest # NOQA
info['version'] = (op, version)
yield info
def parse_require_file(fpath):
with open(fpath, 'r') as f:
for line in f.readlines():
line = line.strip()
if line and not line.startswith('#'):
for info in parse_line(line):
yield info
def gen_packages_items():
if exists(require_fpath):
for info in parse_require_file(require_fpath):
parts = [info['package']]
if with_version and 'version' in info:
parts.extend(info['version'])
if not sys.version.startswith('3.4'):
# apparently package_deps are broken in 3.4
platform_deps = info.get('platform_deps')
if platform_deps is not None:
parts.append(';' + platform_deps)
item = ''.join(parts)
yield item
packages = list(gen_packages_items())
return packages
if __name__ == '__main__':
setup(
name='mmdet',
version=get_version(),
description='OpenMMLab Detection Toolbox and Benchmark',
long_description=readme(),
long_description_content_type='text/markdown',
author='OpenMMLab',
author_email='[email protected]',
keywords='computer vision, object detection',
url='https://github.com/open-mmlab/mmdetection',
packages=find_packages(exclude=('configs', 'tools', 'demo')),
classifiers=[
'Development Status :: 5 - Production/Stable',
'License :: OSI Approved :: Apache Software License',
'Operating System :: OS Independent',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: 3.8',
],
license='Apache License 2.0',
setup_requires=parse_requirements('requirements/build.txt'),
tests_require=parse_requirements('requirements/tests.txt'),
install_requires=parse_requirements('requirements/runtime.txt'),
extras_require={
'all': parse_requirements('requirements.txt'),
'tests': parse_requirements('requirements/tests.txt'),
'build': parse_requirements('requirements/build.txt'),
'optional': parse_requirements('requirements/optional.txt'),
},
ext_modules=[],
cmdclass={'build_ext': BuildExtension},
zip_safe=False)预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注即可免费领取深度学习算法学习资料!