【ACM 2020 - Text Recognition in the Wild:A Survey】OCR识别综述
Introduction
1. 推动基于深度学习的STR发展三要素:
(1)先进的硬件系统:高性能计算支持训练大规模识别网络
(2)基于深度学习的STR算法能自动进行特征学习
(3)STR应用需求旺盛
BACKGROUND
STR基本问题:
(1)Text localization(文本定位)
- Pan He, Weilin Huang, Tong He, Qile Zhu, Yu Qiao, and Xiaolin Li.Single shot text detector with regional attention. In Proceedings of ICCV. 3047–3055.
- Fangneng Zhan and Shijian Lu. 2019. ESIR: End-to-end scene text recognition via iterative image rectification. In Proceedings of CVPR. 2059–2068.
- Fang Yin, Rui Wu, Xiaoyang Yu, and Guanglu Sun. 2019. Video text localization based on Adaboost. Multimedia Tools and Applications 78, 5 (2019), 5345–5354.
(2)Text verification(文本验证)
- Tao Wang, David J Wu, Adam Coates, and Andrew Y Ng. 2012. End-to-end text recognition with convolutional neural networks. In Proceedings of ICPR. 3304–3308.
- Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep features for text spotting. In Proceedings of ECCV. 512–528.
(3)Text detection(文本检测)
基于回归:
- Yuliang Liu and Lianwen Jin. 2017. Deep matching prior network: Toward tighter multi-oriented text detection. In Proceedings of CVPR. 1962–1969.
- Yuliang Liu, Lianwen Jin, Shuaitao Zhang, Canjie Luo, and Sheng Zhang. 2019. Curved scene text detection via transverse and longitudinal sequence connection. Pattern Recognition 90 (2019), 337–345.
基于分割:
- Yongchao Xu, Yukang Wang, Wei Zhou, Yongpan Wang, Zhibo Yang, and Xiang Bai. 2019. TextField: learning a deep direction field for irregular scene text detection. IEEE Transactions on Image Processing 28, 11 (2019), 5566–5579.
- Yuliang Liu, Lianwen Jin, and Chuanming Fang. 2020. Arbitrarily Shaped Scene Text Detection with a Mask Tightness Text Detector. IEEE Transactions on Image Processing 29 (2020), 2918–2930.
(4)Text segmentation(文本分割)
单行分割:
- Fangneng Zhan and Shijian Lu. 2019. ESIR: End-to-end scene text recognition via iterative image rectification. In Proceedings of CVPR. 2059–2068.
单字符分割(早期文字识别方法):
- Palaiahnakote Shivakumara, Souvik Bhowmick, Bolan Su, Chew Lim Tan, and Umapada Pal. 2011. A new gradient based character segmentation method for video text recognition. In Proceedings of ICDAR. 126–130
- Anand Mishra, Karteek Alahari, and CV Jawahar. 2012. Scene text recognition using higher order language priors. In Proceedings of BMVC. 1–11.
(5)Text recognition(文本识别)
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, and Shuigeng Zhou. 2017. Focusing attention: Towards accurate text recognition in natural images. In Proceedings of ICCV. 5086–5094.
- Canjie Luo, Lianwen Jin, and Zenghui Sun. 2019. MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition. Pattern Recognition 90 (2019), 109–118.
- Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2019. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell 41, 9 (2019), 2035–2048.
(6)End-to-end system(端到端)
- Hui Li, Peng Wang, and Chunhua Shen. 2017. Towards end-to-end text spotting with convolutional recurrent neural networks. In Proceedings of ICCV. 5238–5246.
- Tong He, Zhi Tian, Weilin Huang, Chunhua Shen, Yu Qiao, and Changming Sun. 2018. An end-to-end textspotter with explicit alignment and attention. In Proceedings of CVPR. 5020–5029.
- Yuliang Liu, Hao Chen, Chunhua Shen, Tong He, Lianwen Jin, and Liangwei Wang. 2020. ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network. In Proceedings of CVPR.
其它:Script identification、Text enhancement、Text tracking、NLP
METHODOLOGIES
STR常见方法有基于单字符分割的方法和文本行识别的方法
1. 基于单字符分割
三个步骤:图像处理,字符分割,单字符识别
- Zhaoyi Wan, Mingling He, Haoran Chen, Xiang Bai, and Cong Yao. 2020.TextScanner: Reading Characters in Order for Robust Scene Text Recognition. In Proceedings of AAAI.
通过与语义分割实现字符级识别,通过构建两个分支分别进行字符的分类和定位
存在的问题:
(1)字符定位被认为是STR中最具挑战性的任务之一,识别效果受字符定位效果影响
(2)单字符识别未考虑到上下文语义信息,最终单词级别效果可能较差
2. 文本行识别
四个步骤:图像处理,特征提取,序列模型,文本行预测,其中第一步和第三部非必需

(1)图像处理
背景移除
传统的二值化方法可以应用到文档图像中,对于自然场景中的复杂图像,可以借鉴GAN的方法移除背景
- Canjie Luo, Qingxiang Lin, Yuliang Liu, Jin Lianwen, and Shen Chunhua. 2020. Separating Content from Style Using Adversarial Learning for Recognizing Text in the Wild. CoRR abs/2001.04189 (2020).(借助CANs的方法移除背景)
图像超分
对于模糊且分辨率低的图像,通过采用图像超分的方法解决
- Wenjia Wang, Enze Xie, Peize Sun, Wenhai Wang, Lixun Tian, Chunhua Shen, and Ping Luo. 2019. TextSR: Content-Aware Text Super-Resolution Guided by Recognition. CoRR abs/1909.07113 (2019).(首次将图像超分与识别任务相结合)
- https://github.com/JasonBoy1/TextZoom(超分+识别)
图像整流
通过人为设计整流网络应对不规则文本图像,规范化图像输入
- Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. 2015. Spatial transformer networks. In Proceedings of NIPS. 2017–2025.(STN)
- Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2019. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell 41, 9 (2019), 2035–2048.(TPS)
- Canjie Luo, Lianwen Jin, and Zenghui Sun. 2019. MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition. Pattern Recognition 90 (2019), 109–118.(提出多目标整流网络,预测图像每个部分的偏移量来纠正不规则文本)
(2)特征提取
图像特征提取的效果直接影响到最终的识别性能,更深更先进的特征提取网络能取得更好的效果,但是需要更高的内存开销以及需要更大的算力支持,背景消除+简单的特征提取网络可能是未来发展的一个方向
基于CNN:
- Xiao Yang, Dafang He, Zihan Zhou, Daniel Kifer, and C Lee Giles. 2017. Learning to read irregular text with attention mechanisms. In Proceedings of IJCAI. 3280–3286.(VGG)
- Qingqing Wang, Wenjing Jia, Xiangjian He, Yue Lu, Michael Blumenstein, Ye Huang, and Shujing Lyu. 2019. ReELFA: A Scene Text Recognizer with Encoded Location and Focused Attention. In Proceedings of ICDAR: Workshops. 71–76.(VGG)
- Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2019. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell 41, 9 (2019), 2035–2048.(ResNet)
- Xiaoxue Chen, Tianwei Wang, Yuanzhi Zhu, Lianwen Jin, and Canjie Luo. 2020. Adaptive Embedding Gate for Attention-Based Scene Text Recognition. Neurocomputing 381 (2020), 261–271.(ResNet)
- Yunze Gao, Yingying Chen, Jinqiao Wang, Ming Tang, and Hanqing Lu. 2018. Dense Chained Attention Network for Scene Text Recognition. In Proceedings of ICIP. 679–683.(DenseNet)
- Yunze Gao, Yingying Chen, Jinqiao Wang, Ming Tang, and Hanqing Lu. 2019. Reading scene text with fully convolu-tional sequence modeling. Neurocomputing 339 (2019), 161–170.(DenseNet)
基于RCNN:
- Chen-Yu Lee and Simon Osindero. 2016. Recursive recurrent nets with attention modeling for OCR in the wild. In Proceedings of CVPR. 2231–2239.
- Jianfeng Wang and Xiaolin Hu. 2017. Gated recurrent convolution neural network for OCR. In Proceedings of NIPS. 335–344.
基于CNN+Attention:
考虑到直接用CNN提取特征可能会引入额外噪声,因此结合Attention机制强化文本内容抑制背景
- Yaping Zhang, Shuai Nie, Wenju Liu, Xing Xu, Dongxiang Zhang, and Heng Tao Shen. 2019. Sequence-To Sequence Domain Adaptation Network for Robust Text Image Recognition. In Proceedings of CVPR. 2740–2749.
- Minghui Liao, Pengyuan Lyu, Minghang He, Cong Yao, Wenhao Wu, and Xiang Bai. 2019. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. IEEE Trans. Pattern Anal. Mach. Intell (2019).
- Yunlong Huang, Zenghui Sun, Lianwen Jin, and Canjie Luo. 2020. EPAN: Effective parts attention network for scene text recognition. Neurocomputing 376 (2020), 202–213.
(3)序列模型
序列模型被当作衔接图像的视觉特征以及识别预测之间的桥梁,能够捕获字符的上下文信息用于下一时间阶段的字符预测,因此比独立的字符预测效果要好
双向LSTM:能捕获长序列依赖,但是由于RNN结构特性,无法并行化
- Siwei Wang, Yongtao Wang, Xiaoran Qin, Qijie Zhao, and Zhi Tang. 2019. Scene Text Recognition via Gated Cascade Attention. In Proceedings of ICME. 1018–1023.
- Mingkun Yang, Yushuo Guan, Minghui Liao, Xin He, Kaigui Bian, Song Bai, Cong Yao, and Xiang Bai. 2019. Symmetry-constrained rectification network for scene text recognition. In Proceedings of ICCV. 9147–9156.
- Tianwei Wang, Yuanzhi Zhu, Lianwen Jin, Canjie Luo, Xiaoxue Chen, Yaqiang Wu, Qianying Wang, and Mingxiang Cai. 2020. Decoupled Attention Network for Text Recognition. In Proceedings of AAAI.
- Jeonghun Baek, Geewook Kim, Junyeop Lee, Sungrae Park, Dongyoon Han, Sangdoo Yun, Seong Joon Oh, and Hwalsuk Lee. 2019. What is wrong with scene text recognition model comparisons? dataset and model analysis. In Proceedings of ICCV. 4714–4722.
- Canjie Luo, Lianwen Jin, and Zenghui Sun. 2019. MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition. Pattern Recognition 90 (2019), 109–118.
CNN:CNN可以通过感受野控制进行长文本上下文信息建模,能并行化处理
- Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, and Errui Ding. 2020. Towards Accurate Scene Text Recognition with Semantic Reasoning Networks. In Proceedings of CVPR.
- Zhi Qiao, Yu Zhou, Dongbao Yang, Yucan Zhou, and Weiping Wang. 2020. SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition. In Proceedings of CVPR.
transformer:采用Attention机制进行图像的序列化编码,能并行化处理
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of NIPS. 5998–6008.
(4)文本识别
对文本图像的编码特征进行解码成对应的字符序列,主流的两种方法为基于CTC和基于Attention机制
基于CTC方法:
CTC在语音识别和在线手写识别上均有广泛的应用,在STR中,CTC通过计算条件概率来实现识别这一任务,基于约定的映射关系,最大化输入到输出的所有可能路径的条件概率和。此外,无需数据对齐标注就可以完成训练过程。
- Yunze Gao, Yingying Chen, Jinqiao Wang, Ming Tang, and Hanqing Lu. 2019. Reading scene text with fully convolutional sequence modeling. Neurocomputing 339 (2019), 161–170
- Baoguang Shi, Xiang Bai, and Cong Yao. 2017. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell 39, 11 (2017), 2298–2304.
CTC存在的问题:
- CTC计算较为复杂,对于长文本计算量较大
- 峰值分布问题,对于重复模块(重复字符)识别效果显著下降
Alex Graves, Santiago Fernández, Faustino Gomez, and Jürgen Schmidhuber. 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of ICML. 369–376. - CTC倾向于输出过度自信、呈尖峰分布的预测结果,容易过拟合
-Hu Liu, Sheng Jin, and Changshui Zhang. 2018. Connectionist temporal classification with maximum entropy regularization. In Proceedings of NIPS. 831–841.
-code: https://github.com/liuhu-bigeye/enctc.crnn
提出一种基于最大熵的正则化方法对CTC算法进行改进 - 无法进行二维方向识别,对非常规文本行,纵向堆叠文本行无法识别
-Zhaoyi Wan, Fengming Xie, Yibo Liu, Xiang Bai, and Cong Yao. 2019. 2D-CTC for Scene Text Recognition. CoRR abs/1907.09705 (2019).
尝试在高度方向增加一个维度计算CTC,但是最终改善效果有限
对CTC方法的其它改进:
- Xinjie Feng, Hongxun Yao, and Shengping Zhang. 2019. Focal CTC Loss for Chinese Optical Character Recognition on Unbalanced Datasets. Complexity 2019 (2019), 9345861:1–9345861:11.
提出一种融合焦点损失的方法解决识别样本不均衡的问题 - Wenyang Hu, Xiaocong Cai, Jun Hou, Shuai Yi, and Zhiping Lin. 2020. GTC: Guided Training of CTC Towards Efficient and Accurate Scene Text Recognition. In Proceedings of AAAI.
采用图卷积网络提升CTC的准确率和鲁棒性
基于Attention的方法:
Attention最初被[1]提出来用来做机器翻译,后来也被用在图像标题[2]、文本识别[3]、遥感影像分类[4]等场景,在STR场景中,通常与RNN结构相结合作为识别模块,Attention机制通过对目标字符之前的输出信息结合编码过程中输出的特征向量学习对齐特征
- [1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of ICLR.
- [2] Xinwei He, Yang Yang, Baoguang Shi, and Xiang Bai. 2019. VD-SAN: Visual-Densely Semantic Attention Network for Image Caption Generation. Neurocomputing 328 (2019), 48–55.
- [3] Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2019. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell 41, 9 (2019), 2035–2048.
- [4] Qi Wang, Shaoteng Liu, Jocelyn Chanussot, and Xuelong Li. 2018. Scene classification with recurrent attention of VHR remote sensing images. IEEE Transactions on Geoscience and Remote Sensing 57, 2 (2018), 1155–1167.
Attention应用于STR场景:
- Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2019. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell 41, 9 (2019), 2035 2048.
- Xiao Yang, Dafang He, Zihan Zhou, Daniel Kifer, and C Lee Giles. 2017. Learning to read irregular text with attention mechanisms. In Proceedings of IJCAI. 3280–3286.
- Canjie Luo, Lianwen Jin, and Zenghui Sun. 2019. MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition. Pattern Recognition 90 (2019), 109–118.
- Mingkun Yang, Yushuo Guan, Minghui Liao, Xin He, Kaigui Bian, Song Bai, Cong Yao, and Xiang Bai. 2019. Symmetry constrained rectification network for scene text recognition. In Proceedings of ICCV. 9147–9156.
基于Attention模型所进行的改进:
- Applying to 2D prediction problems(应用于二维预测问题)
-Xiao Yang, Dafang He, Zihan Zhou, Daniel Kifer, and C Lee Giles. 2017. Learning to read irregular text with attention mechanisms. In Proceedings of IJCAI. 3280–3286.
-Hui Li, Peng Wang, Chunhua Shen, and Guyu Zhang. 2019. Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of AAAI. 8610–8617.
-Yunlong Huang, Zenghui Sun, Lianwen Jin, and Canjie Luo. 2020. EPAN: Effective parts attention network for scene text recognition. Neurocomputing 376 (2020), 202–213. - Improving the construction of implicit language model(用于隐式语言模型构建)
提出一种高阶字符语言模型
-Xiaoxue Chen, Tianwei Wang, Yuanzhi Zhu, Lianwen Jin, and Canjie Luo. 2020. Adaptive Embedding Gate for
Attention-Based Scene Text Recognition. Neurocomputing 381 (2020), 261–271.
ASTER方法构建双向注意力解码器
-Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. 2019. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell 41, 9 (2019), 2035–2048. - Improving parallelization and reducing complexity(模型并行化)
transformer方法抛弃掉传统的RNN结构,实现并行化处理
-Yiwei Zhu, Shilin Wang, Zheng Huang, and Kai Chen. 2019. Text Recognition in Images Based on Transformer with Hierarchical Attention. In Proceedings of ICIP. 1945–1949.
-Peng Wang, Lu Yang, Hui Li, Yuyan Deng, Chunhua Shen, and Yanning Zhang. 2019. A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition. CoRR abs/1904.01375 (2019).
-Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, and Errui Ding. 2020. Towards Accurate Scene Text Recognition with Semantic Reasoning Networks. In Proceedings of CVPR. - Addressing attention drift(解决注意力偏移问题)
-Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, and Shuigeng Zhou. 2017. Focusing attention: Towards accurate text recognition in natural images. In Proceedings of ICCV. 5086–5094
-Yunlong Huang, Zenghui Sun, Lianwen Jin, and Canjie Luo. 2020. EPAN: Effective parts attention network for scene text recognition. Neurocomputing 376 (2020), 202–213.
Attention存在的问题:
- 依赖于attention模块进行标签对齐,需要较大的内存和算力开销
- 对于长文本从头开始训练较为困难(注意力偏移导致)
- 目前基于attention的研究主要集中在字符类别较少的语言上,在中文识别领域,目前还没有取得较好的应用
CTC和Attention结合:
- Wenyang Hu, Xiaocong Cai, Jun Hou, Shuai Yi, and Zhiping Lin. 2020. GTC: Guided Training of CTC Towards Efficient and Accurate Scene Text Recognition. In Proceedings of AAAI.
- Ron Litman, Oron Anschel, Shahar Tsiper, Roee Litman, Shai Mazor, and R. Manmatha. 2020. SCATTER: Selective Context Attentional Scene Text Recognizer. In Proceedings of CVPR.
CTC和Attention对比:
单词级别:Attention效果更好
句子级别:CTC效果更好
- Fuze Cong, Wenping Hu, Huo Qiang, and Li Guo. 2019. A Comparative Study of Attention-based Encoder Decoder Approaches to Natural Scene Text Recognition. In Proceedings of ICDAR. 916–921.
端到端系统:
非端到端系统通常是将检测和识别当作两个独立的子任务进行串联起来,实现图像中文本内容的定位与识别,而端到端的系统检测和识别则是共享同一个网络,共同参与网络的训练过程,通常也包括文本框的定位,文本内容的识别以及后处理三个部分
端到端系统的优点:
(1)将检测和识别拆分为两个独立的任务,会产生累计误差,端到端由于是同时训练检测和识别部分,因此不会产生累计误差
(2)检测和识别部分共享网络参数,共享训练数据,因此可以整体进行优化
(3)在不同的场景中能快速地迁移应用,数据依赖程度较低
(4)执行速度快,内存开销小
缺陷:
(1)网络结构设计较难,检测和识别之间的衔接及信息共享
(2)检测和识别任务在网络学习及收敛过程中存在明显的差异性,较难权衡二者之间的关系
(3)联合训练的存在较大的优化空间
端到端的方法比较
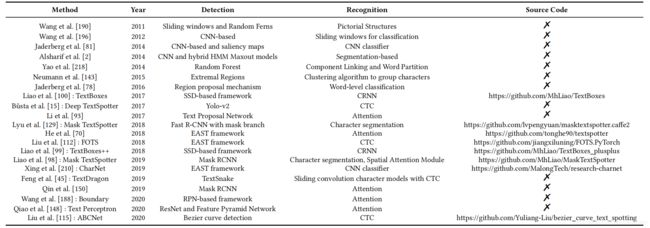
EVALUATIONS AND PROTOCOLS
数据集:包含合成数据集和真实数据集
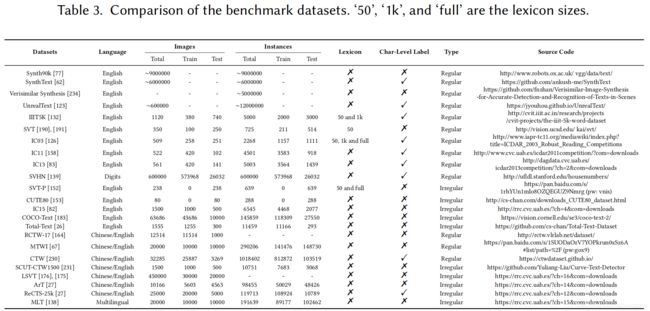
合成数据集:Synth90k, SynthText, Verisimilar Synthesis, UnrealText
真实数据集:常规拉丁文(IIIT5K-Words (IIIT5K), Street View Text (SVT), ICDAR 2003 (IC03), ICDAR 2011 (IC11), ICDAR 2013 (IC13), Street View House Number (SVHN)); 非常规拉丁文(SVT-P, CUTE, IC15, COCO-Text, Total-Text);中文自然场景数据集(RCTW-17), MTWI, CTW, LSVT, ArT等)
识别评价指标:
- 单词识别准确率: W R A = W r W WRA = \frac {W_r}{W} WRA=WWr , 其中 W r W_r Wr表示识别正确的单词, W W W表示所有待识别的单词
- 编辑距离: N E D = 1 N ∑ ︁ i = 1 N D ( s i , s i − ) / m a x ( l i , l i − ) NED= \frac{1}{N} ∑︁^N_{i=1}D(s_i, \overset{-}{s_i})/max(l_i, \overset{-}{l_i}) NED=N1∑︁i=1ND(si,si−)/max(li,li−), 其中 s i s_i si和 s i − \overset{-}{s_i} si−分别表示预测的结果和真实标签, l l l代表字符串长度
端到端的系统评价指标:
- 从多个方面综合评价,包括准确率,召回率,以及基于NED计算的F1指标
- A E D AED AED:计算每一张图像的NED,累加起来除以测试图像数量
DISCUSSION AND FUTURE DIRECTIONS
STR尽管已经取得非常明显的突破,但是还有许多需要进步的地方,STR在未来的发展方向可以有以下几个方面:
- 通用能力的提升:在特定简单场景下,STR能取得较好的效果,但是当场景发生改变,且更加复杂,STR训练的模型往往需要重新推倒重来,这不符合人类语言学习的方式,没有从根本上理解语言信息,因此,除了加入更多更加复杂的数据之外,还需要继续探索模型在图像视觉和语义上的理解能力
- 评估指标:尽管许多模型都宣称自身达到了state-of-the-art的效果,但是由于其采用的训练数据集不统一,先验条件和测试环境不一致,因此很难公平的评估模型之间的差异性
- 数据问题:由于真实标注数据的缺失,目前主流的方法都是基于大量的合成数据上训练,在真实数据上验证,这将使得模型的效果受限,而标注大规模高质量的真实数据代价十分昂贵,因此,后续的工作可以考虑(1)尽可能合成更加真实的数据,缩小合成数据与真实数据之间的距离,(2)充分利用起未标注的真实数据来(3)更好的数据增强方式
- 应用场景:目前STR在特定理想化的场景中效果较好,但在真实场景中往往表现较差,因此,更加通用化的模型以及具体场景中精度更高的模型需要继续探索研究
- 图像处理:一些图像处理技术比如背景移除,图像超分等可以帮助我们的模型提升识别精度
- 端到端系统:相较于独立的检测和识别任务,端到端的优势在于模型执行速度更快,内存开销更小,不会产生累计偏差,但是,目前端到端的性能相对较差,没有一个好的方法将检测部分和识别部分更好地融合起来,充分共享网络参数,降低检测任务和识别任务本身特性产生的学习差异性
- 不同的语言:目前基于拉丁语言开发出的模型不能很好的应用到其它语言中,比如中文包含几千类字符,面对大规模字符集的语言,相关研究缺乏
- 安全性:通过对图像添加一些人眼看不出来的噪声,就可以使得目前深度学习的模型失效,因此,模型的安全性研究也是未来的一个方向
- STR+NLP:自然语言处理是建立起人类与计算机之间沟通的桥梁,STR与NLP相结合也是未来发展的一大趋势,如文档理解,问答系统,信息提取等
资料
论文地址:https://arxiv.org/abs/2005.03492
https://github.com/HCIILAB/Scene-Text-Recognition