kaggle_Titanic练习经验
借助网上的教学文章对kaggle 进行了学习,并对基础项目,Titanic之灾进行复现。现将我的学习过程记录下来,以备后来学习借鉴。
1、环境的配置
使用的编译软件是python、pycharm。首先需要检查pip是否是最新版本,因为需要安装其他的第三方库,最新版本便于安装。若遇见问题,可参考我之前关于pip更新解决的经验贴。
接下来,是安装第三方库,主要需要pandas、numpy、ipython等。可上网查找ipython相关的库,一同安装。
2、数据集下载
需要进入kaggle的官网,进行下载,此时需要注册新的kaggle账号,
此处会遇见新的问题:人工识别验证不显示,这是由于kaggle网站服务器不在国内的问题。
解决方法:安装插件(一个H开头的插件,可百度。)

点击此处即可。
3、实际运用
已经下载了数据集,那么如何运用呢。下面进行展示(此处需要已经安装好各种库。)
import pandas as pd #数据分析
import matplotlib.pyplot as plt
import numpy as np #科学计算
from pandas import Series,DataFrame
# 设置中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
pd.set_option('max_colwidth', 100)
# 设置1000列的时候才换行
pd.set_option('display.width', 1000)
#读取下载的数据集
data_train = pd.read_csv("E:/Chen Jingwen's folder/untitled/dateset_cjw/Titanic/Dataset/train.csv")
#打印数据集
print(data_train)pandas是常用的python数据处理包,把csv文件读入成dataframe各式,我们在ipython notebook中,看到data_train如下所示: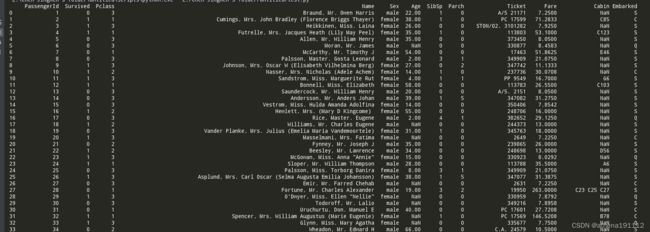
这就是dateframe,其实类似于表格。不要害怕
我们看到,总共有12列,其中Survived字段表示的是该乘客是否获救,其余都是乘客的个人信息,包括:
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
891条数据,一条条看,实在太多了。有没有可以让我们获取大概信息的方法?
有!!!
print(data_train.info())
通过这条语句,我们可以看到,每列下的数据总数,奇怪的事发生了,Age的数据不全。
- Age(年龄)属性只有714名乘客有记录
- Cabin(客舱)更是只有204名乘客是已知的
那此时我们想了解一些数值上的东西,比如说:平均值。该怎么办呢?
print(data_train.describe())这样我们就可以看见数值信息了: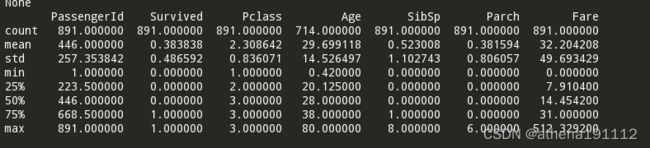
这里只能看见数据信息,而字符信息是看不见的。
mean字段告诉我们,大概0.383838的人最后获救了,2/3等舱的人数比1等舱要多,平均乘客年龄大概是29.7岁(计算这个时候会略掉无记录的)等等…
4、数据分析
到这一步了,然后呢?我们怎么用这些数据,这密密麻麻的,怎么分析?此时,我们就需要可视化的手段了(这里只是一些简单的图像转化,类似matlab)
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
#分为2*3=6个部分,此处为0.0 第一部分
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
#分析:数据集名字.幸存者.值.计数函数.绘图(类型为柱状图)
plt.title(u"获救情况 (1为获救)") # 标题
#标题在上方,也有相关的语句,下次遇见再记录
plt.ylabel(u"人数")
#xlabel 表示横坐标标注, ylabel 表示纵坐标标注。
plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
#scatter()函数表示为寻找变量之间的关系
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(visible=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
#colspan=2,代表它需要占用两个单元格的位置,有点像合并单元格的意思
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
#类型为折线图 Pclass是乘客几等舱的变量名 Age[](年龄的列表),即选取1等舱的乘客年龄
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
#legend()即指明每条线是什么线。loc=' '表示该方框的位置,有很多参数。best 表示不设置
plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()
代码自行解读,运行的图像为:

我们可以从图上直观地获得信息,不是吗?
获救人数只有300+,未获救的占了一大半。
乘客的等级大部分在第3级。
年龄和获救情况好像没什么关系,各年龄段都有,但是80~60的老人出现了断档。(值得思考)
年龄和等级的关系图:年长的似乎大多在头等舱,年轻点的在2、3。
港口:明显S港的人最多。
思考一下:
- 不同舱位/乘客等级可能和财富/地位有关系,最后获救概率可能会不一样
- 年龄对获救概率也一定是有影响的,毕竟前面说了,副船长还说『小孩和女士先走』呢
- 和登船港口是不是有关系呢?也许登船港口不同,人的出身地位不同?
口说无凭,空想无益。老老实实再来统计统计,看看这些属性值的统计分布吧
先看,获救与乘客等级的情况。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
#未获救的乘客等级 的数据统计。 数据集名.乘客登记列表[数据集名.未获救的].数据统计
#data_train.Pclass[].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
###给了两个变量,需要绘制百分比柱状图
df.plot(kind='bar', stacked=True)
#当需要绘制百分比柱状图时,需要传入参数stacked=True,否则就是默认普通柱状图
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
如果需要plot()函数相关的知识,可以看:#18 可视化基础4-簇形柱状图、百分比堆积柱状图、并列子图_Ag_MoonLi的博客-CSDN博客_堆积柱状图并列
另一个很奇怪的地方,为什么这里没有使用legend,但是最终却有相关的标注。
估计是因为
pd.DataFrame的缘故。
.DataFrame()函数将各个等级的乘客的获救情况记录下来。在绘制图像时,直接绘制三个等级下,获救与未获救的情况。
可看下面的链接。
pd.DataFrame()函数解析(最清晰的解释)_我是管小亮的博客-CSDN博客_pd.dataframe什么意思
上图可以看出:钱和其地位可以决定舱位,更会和获救情况挂钩。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
#此处的代码和上面乘客等级的代码 ,有所不同。数据集名.获救【数据集.性别 】
#所以最终绘制图像时,得到图像的横轴就是以获救与否为指标。而解释的标记就变为(男、女)
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()

获救情况可以看出,获救里的大部分都是女性。,所以性别也是其中的一个干扰因素。
从上面的简单分析,看出来舱位和性别对于是否能获救都有影响,现在将两者都考虑上,来看看相关性。
对比,女性高级仓、女性低级舱、男性高级舱、男性低级舱分别作图,对照比较。
###########舱位和性别的影响#############
fig=plt.figure()
fig.set(alpha=0.65) # 设置图像透明度,无所谓
plt.title(u"根据舱等级和性别的获救情况")
ax1=fig.add_subplot(141)
#将一幅图分为四个部分,此处为第一部分
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass != 3].value_counts().plot(kind='bar', color='#FA2479')
#数据集名.获救【女性】【舱位不为第三等】(此处的高级仓Wie1、2)
ax1.set_xticklabels([u"获救", u"未获救"], rotation=0)
#rotation=0 表示将下标改为横向的
ax1.legend([u"女性/高级舱"], loc='best')
ax2=fig.add_subplot(142, sharey=ax1)
data_train.Survived[data_train.Sex == 'female'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='female, low class', color='pink')
ax2.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"女性/低级舱"], loc='best')
ax3=fig.add_subplot(143, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass != 3].value_counts().plot(kind='bar', label='male, high class',color='lightblue')
ax3.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/高级舱"], loc='best')
ax4=fig.add_subplot(144, sharey=ax1)
data_train.Survived[data_train.Sex == 'male'][data_train.Pclass == 3].value_counts().plot(kind='bar', label='male low class', color='steelblue')
ax4.set_xticklabels([u"未获救", u"获救"], rotation=0)
plt.legend([u"男性/低级舱"], loc='best')
plt.show()此处的高级指的是舱位为1或者2。
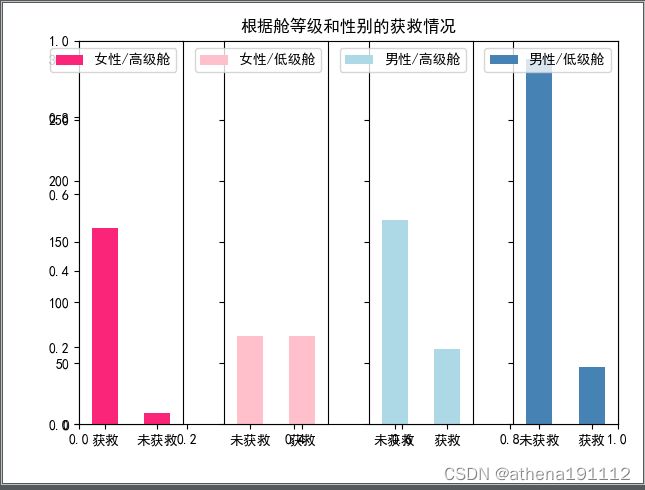
可以看出女性高级仓的获救比例最高。女性低级舱的对半。
接下来是测试登陆港口。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况")
plt.xlabel(u"登录港口")
plt.ylabel(u"人数")
plt.show()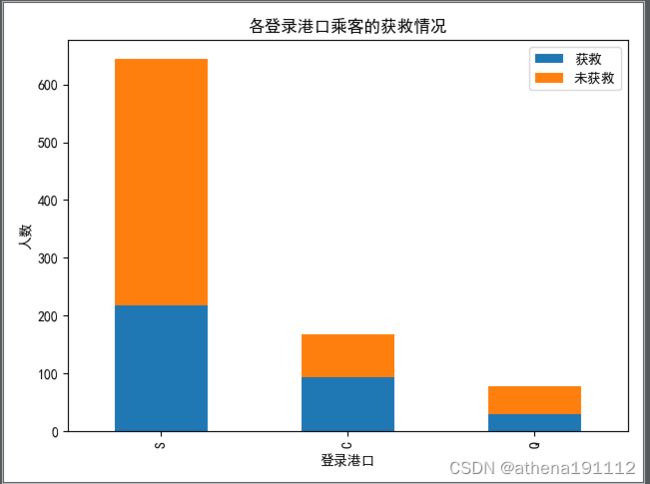
港口好像没什么关系啊。
后面再看看确实严重的cabin。。。。,因为缺失的太多了,我也不知道能干啥了。
关键是Cabin这鬼属性,应该算作类目型的,本来缺失值就多,还如此不集中,注定是个棘手货…第一感觉,这玩意儿如果直接按照类目特征处理的话,太散了,估计每个因子化后的特征都拿不到什么权重。加上有那么多缺失值,要不我们先把Cabin缺失与否作为条件(虽然这部分信息缺失可能并非未登记,maybe只是丢失了而已,所以这样做未必妥当),先在有无Cabin信息这个粗粒度上看看Survived的情况好了。
对于缺失很多的数据,我们可以利用pd.notnull和pd.isnull来将这个数据变为粗粒度的有无。来分析这个数据(当然这是不恰当的处理方式)
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
#此处.transpose()的作用就是映射坐标轴,将横坐标修改为,有和无。
# 如果没有,就将按照Survived_cabin和Survived_nocabin的外层变量来制定。
df.plot(kind='bar', stacked=True)
plt.title(u"按Cabin有无看获救情况")
plt.xlabel(u"Cabin有无")
plt.ylabel(u"人数")
plt.legend((u'未获救', u'获救'),loc='best')
plt.show()

这么看,有信息的获救率高一点?看起来有cabin的获救的人数更多。(是不是因为低等舱的没有啊???)
5、简单数据预处理
搞了这么多,下一步该干啥了?先预处理相关的数据,为建模打基础。(对缺失数据进行处理)
先从最突出的数据属性开始吧,对,Cabin和Age,有丢失数据实在是对下一步工作影响太大。
Cabin:
暂时我们就按照刚才说的,按Cabin有无数据,将这个属性处理成Yes和No两种类型吧。
Age:
最开始我们就知道了Age的数据缺失了,但是并不是特别多。对于遇见 的年龄缺失,我们通常采取以下几个方法。
1、若缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
2、缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,(有无)加到类别特征中。(类目型数据是指类别变量,只能将事物进行区分,不能进行计算)
3、缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
4、有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
对于本例,可使用后两种。(因为Age是连续值特征属性,并且缺失的个数不算太多。而且年龄确实很重要,毕竟说过“老人小孩先走!”)
机器学习之特征工程_Ouyangjianxiu的博客-CSDN博客
(对Age的处理)
使用随机森林的方法拟合一下缺失的年龄Age数据。
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进RandomForgestRegressor
age_df = df[['Age','Fare','Parch','SibSp','Pclass']]
#这里的所有数据都是显示了数据型的内容,不需要字符串型的。相当于简化了数据集。
known_age = age_df[age_df.Age.notnull()].values
#notnull()与isnull()函数的功能是一样的,都可以判断数据中是否存在空值或缺失值,
#不同之处在于,前者发现数据中有空值或缺失值时返回False,后者返回的是True。
unknown_age = age_df[age_df.Age.isnull()].values
#.values 使得返回一个年龄的多维数据,一个是有Age的,一个是没有Age的
y = known_age[:,0]
#取多维数据中每一行的第一个数据,即将所有已知年龄提取出来
# y是目标年龄
x = known_age[:,1:]
# 提取多维数据中的 每一行第一个数据之后的所有数据。
# x是特征属性值
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
#对于随机森林这个模型,它本质上是随机的,
# 设置不同的随机状态(或者不设置random_state参数)可以彻底改变构建的模型。
#n_jobs=1: 并行job个数。
# 这个在ensemble算法中非常重要,尤其是bagging(而非boosting,因为boosting的每次迭代之间有影响,所以很难进行并行化),
# 因为可以并行从而提高性能。
# 1=不并行;
# n:n个并行;
# -1:CPU有多少core,就启动多少job
##n_estimators=10: 决策树的个数,越多越好,但是性能就会越差,
# 至少100左右可以达到可接受的性能和误差率。
rfr.fit(x, y)
# fit到RandomForestRegressor之中
# fit(特征属性,目标年龄)
# 用得到的模型来进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:,1::])
#.predict()返回的是类别标签,也就是属于哪个年龄。
df.loc[(df.Age.isnull()),'Age'] = predictedAges
#这一步将已经获得类别标签(年龄),放回年龄最原始的df.Age下,
# df.loc[]函数,方括号里,可以放条件句子,或者直接跟‘名字’,指定该列。
return df
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
#修改了原始df中Cabin的数据。
return df
data_train = set_missing_ages(data_train)
data_train_over = set_Cabin_type(data_train)
print(data_train_over)
print(data_train_over.info())

现在数据就已经是完整的了。
其中一些知识的理解:
known_age的输出:

unknown_age的输出:

x的输出:

随机森林算法(Random Forest)原理分析及Python实现_卓小白…的博客-CSDN博客_随机森林算法实现
RandomForestRegressor的参数设置及定义。
RandomForestRegressor 参数_*Snowgrass*的博客-CSDN博客_randomforestregressor
代码思想:
先找所有数值型的数据,提出来构成一个新的dataframe;
按照年龄的有无进行数据的提取。分别存储为known_age和unknown_age;
从known_age提取所有的目标年龄,作为目标年龄。
从known_age提取除年龄外的其他数据,作为特征值。(突然明白,目标年龄像一个“靶子”,我一一列出来,然后用他们所对应的其他数据作为特征“箭”,然后进行模型训练(随机森林),相当于把这些“箭”射向“靶子”,当所有“箭”都射完了。那每个“靶子”上是不是就插了很多的“箭”,根据每个“靶子”上“箭”的共同特征,为这个“靶子”设置一个特征集合“磁铁”。当我输入没有年龄的数据时(“铁箭”),会自动归类到吸引力最大的“磁铁靶子”上(即有最多相同特征的“靶子”),最后把这个“靶子”所代表的年龄付给被他所吸引的“铁箭上。”)
因为逻辑回归建模时,需要输入的特征都是数值型特征(就是数字数据),我们通常会先对类目型的特征因子化。
什么叫做因子化呢?举个例子:
以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,‘no’],而将其平展开为’Cabin_yes’,'Cabin_no’两个属性
原本Cabin取值为yes的,在此处的"Cabin_yes"下取值为1,在"Cabin_no"下取值为0
原本Cabin取值为no的,在此处的"Cabin_yes"下取值为0,在"Cabin_no"下取值为1

我们使用pandas的"get_dummies"来完成这个工作,并拼接在原来的"train"之上,如下所示。
相关函数讲解链接:
特征提取之pd.get_dummies()用法_那记忆微凉的博客-CSDN博客_pd.get_dummies
pandas数据合并与重塑(pd.concat篇)_码不停题Elon的博客-CSDN博客_pd.concat函数
[Pandas] DataFrame.drop() 删除数据_山茶花开时。的博客-CSDN博客_dataframe drop
dummies_Cabin = pd.get_dummies(data_train_over['Cabin'], prefix= 'Cabin')
#此处使用了函数get_dummies(data,prefix=None, prefix_sep='_'),
# 来将字符型数据(分类型变量)哑变量处理。转变为数值型数据。
#1.ata : array-like, Series, or DataFrame
#2.prefix : 给输出的列添加前缀,如prefix="A",输出的列会显示类似列名
#3.prefix_sep : 设置前缀跟分类的分隔符sepration,默认是下划线"_"
dummies_Embarked = pd.get_dummies(data_train_over['Embarked'], prefix= 'Embarked')
#每次只调用了其中一列,并指定了前缀名。
dummies_Sex = pd.get_dummies(data_train_over['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train_over['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
#pd.concat(objs, axis=0/1,join='outer')
# objs: series,dataframe或者是panel构成的序列lsit
#axis: 需要合并链接的轴,0是行,1是列
#join:连接的方式 inner,或者outer
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
#df.drop(labels = None, axis = 0,
#index = None, columns = None,
#level = None, inplace = False,
#errors = 'raise')
#1.labels:要删除的列或者行,如果要删除多个,传入列表
#2.axis:轴的方向,0为行,1为列,默认为0
#3.index:指定的一行或多行
#4.columns:指定的一列或多列
#5.level:索引层级,将删除此层级
#6.inplace:布尔值,是否生效
#7.errors:ignore或raise,默认为raise,如果为ignore,则容忍错误,仅删除现有标签
print(df)
通过上述代码的演算,实现了分类型数据转换为数值型数据,并与原来的数据dataframe合并,然后删除原有的字符型数据列。
到这一步,我们就可以进行建模,输入特征了。
马上就要进行建模了,但是我们发现,数据里的 Age 和 Fare 各值之间的跨度太大,太分散。根据逻辑回归和梯度下降,我们知道了。如果各属性值之间scale差距太大,将对收敛速度造成严重影响!!!甚至不收敛!!!所以我们先用scikit-learn里面的preprocessing模块对这俩货做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
逻辑回归(Logistic Regression)详解_生信小兔的博客-CSDN博客_逻辑回归
(以后再看吧,全是公式。)
import sklearn.preprocessing as preprocessing
#######数据标准化,StandardScaler##################
#使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
scaler = preprocessing.StandardScaler()
#相当于把所有数据都标准化了。
df['Age_scaled'] = scaler.fit_transform(df[['Age']])
df['Fare_scaled'] = scaler.fit_transform(df[['Fare']])
#这里只需要增加两列即可。
print(df)
标准化之后,Age和Fare的数据值就变化到了,【-1,1】之间,这里并不是说把这两种数据之间完全改变,我们只是改变了数据的数值,但是空间分布并没有改变。
即使得不同度量(类似:岁、元)之间的特征具有可比性。同时不改变原始数据的分布(不改变分布,那么其特征还是存在的)。
关于标准化的介绍可以看这个:
真的明白sklearn.preprocessing中的scale和StandardScaler两种标准化方式的区别吗?_翻滚的小@强的博客-CSDN博客_standardscaler
fit,transform,fit_transform详解_Mingsheng Zhang的博客-CSDN博客_transform 。fit
6、逻辑回归建模
现在开始建模!!!!!!提取出我们需要的一些数据。转成numpy格式,使用scikit-learn中的LogisticRegression建模。
from sklearn import linear_model
# 用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
#切片出我们需要的属性数据。*代指任意,只要满足前者,均可使用。
#train_np = train_df.as_matrix()
train_np = train_df.values
#.as_matrix()做完在训练模型之前要将数据数组化,以防万一。
# 但现在这个已经不再使用了,改用 .values 没有括号!
#
# y即获救与否的结果
y = train_np[:, 0]
# X即特征属性值(除去获救信息的其余所有数据)
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6,solver='liblinear')
#逻辑回归分类器,逻辑回归模型。
# C参数:设置正则化强度的逆,值越小,正则化越强,设置正则化强度的逆,值越小,正则化越强
# penalty参数:‘l1’ or ‘l2’,选择正则化参数,str类型,可选L1和L2正则化,默认是L2正则化。
# tol参数:对停止标准的容忍,即求解到多少的时候认为已经求得最优解,并停止,默认值为1e-4
#solver参数:{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, 即选择逻辑回归损失函数优化算法的参数。对于小型数据集来说,选择‘liblinear’更好
clf.fit(X, y)
print(clf)
train_df 的输出结果:

train_np的输出结果:这里要仔细看,因为并没有列名了,只有一些数据,但其实是一样的。

相关参数介绍:
sklearn.linear_model.LogisticRegression模型参数详解与predict、predict_proba区别以及源码解析_月上流骚头的博客-CSDN博客__predict_proba_lr

我们就得到了上面这个模型,终于要结束了!!!!
0.0.00..00
什么鬼,我们现在只是对训练集做了操作,接下来需要对测试集也做同样的工作。才能适用于我们的模型。幸好采取的方法也只是之前的一些方法和函数。
test = pd.read_csv("E:/Chen Jingwen's folder/untitled/dateset_cjw/Titanic/Dataset/test.csv")
test.loc[ (test.Fare.isnull()), 'Fare'] = 0
test = set_missing_ages(test)
test_over = set_Cabin_type(test)
print(test_over)
dummies_Cabin = pd.get_dummies(test_over['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(test_over['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(test_over['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(test_over['Pclass'], prefix= 'Pclass')
df = pd.concat([test_over, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
scaler = preprocessing.StandardScaler()
df['Age_scaled'] = scaler.fit_transform(df[['Age']])
df['Fare_scaled'] = scaler.fit_transform(df[['Fare']])
print(df)基础的输出:
修改后的输出:
再补充预测代码即可!!!!!!
###########测试结果#############
test_end = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test_end.values)
#这里需要给test_end加一个values,因为输入模型的数据应该是数值型的,
#但原来的是带有字符列名,需要转换。
result = pd.DataFrame({'PassengerId':test['PassengerId'].values, 'Survived':predictions.astype(np.int32)})
result.to_csv("E:/Chen Jingwen's folder/untitled/dateset_cjw/Titanic/Dataresult/logistic_regression_predictions.csv", index=False)
print('预测完成') 
到这里可以告一段落了!!!!
出现userwarning的解决方法。
https://www.jianshu.com/p/fc3d3c2cd3ca