多模态梳理
一、多模态学习基本概念
1 背景
人们听到的声音、看到的实物、闻到的味道都是一种模态,人们生活在一个多种模态相互交融的环境中。为了使人工智能更好地理解世界,必须赋予人工智能学习、理解和推理多模态信息的能力。多模态学习指建立模型使机器从多模态中学习各个模态的信息,并且实现各个模态的信息的交流和转换。
多模态感知融合是自动驾驶的基础任务,吸引了众多关注。但是,由于原始数据噪声大、信息利用率低以及多模态传感器未对齐等这些原因,要想实现一个好的性能也并非易事。
在复杂的驾驶环境中,单一的传感器信息不足以有效的处理场景的变化。比如在极端恶劣天气中(大暴雨、沙尘暴)能见度较低的情况下,此时只依靠camera的所反馈的RGB图像完全没有办法对环境的变化做出反馈。而在普通的道路环境中,如红绿灯、色锥等,只依靠Lidar的信息也是无法进行有效识别的,也需要结合camera所带来的RGB信息,才能有效的处理。因此,在自动驾驶感知场景的任务中,不同模态信息的互补会更加的重要。
2 模态
模态是指一些表达或感知事物的方式,语音语言等属于天然的、初始的模态,情绪等属于抽象的模态。对每一种信息的来源或者形式,都可以称为一种模态(Modality)。
3 多模态
多模态是从多个模态表达或感知事物。多个模态也可归类为同质性的模态,例如从两台相机中分别拍摄的图片,异质性的模态,即图片与文本语言的关系。目前研究领域中主要是对图像,文本,语音三种模态的处理。之所以要对模态进行融合,是因为不同模态的表现方式不一样,看待事物的角度也会不一样,所以存在一些交叉(所以存在信息冗余),互补(所以比单特征更优秀)的现象,甚至模态间可能还存在多种不同的信息交互,如果能合理的处理多模态信息,就能得到丰富特征信息。即概括来说多模态的显著特点是:余度性 和 互补性 。
多模态融合重点关注深度学习模型中融合特征的阶段,无论是数据级、特征级还是建议级。
4 多模态机器学习
多模态学习(Multimodal Machine Learning, MML):是从多种模态的数据中学习并且提升自身的算法。
5 案例
案例1:人感知外部世界,可以从多种信号中感知环境(注意力/记忆力、声音、味道、触觉、视觉、气味)
视觉2:人和人进行交流
文本:单词、句法、语用学
声音:韵律、声调、笑声语气
视觉:手势姿态、肢体语言、眼神交流、面部情绪
二、多模态机器学习的核心技术挑战
多模态深度学习在不同的多模态组合和学习目标下,主要包含四项关键技术。具体如下。
1 多模态表示学习
- 多模态表示学习(Multimodal Representation):对不同模态数据提取特征,学习跨模态数据的信息交互,以及多模态数据的共同表示。该问题可以分为两个子问题:
(1)联合表示(Joint Representation):已有模态数>特征表示(需要解决的问题数目),联合表示将多个模态的信息一起映射到一个统一的多模态向量空间。多模态数据共同为同一任务合作和融合,例如使用文字、语音、视频共同识别情感。
(2)协作(协同)(Coordination Representation):模态数=特征表示,两种数据在两种任务之间协作。协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)。

2 多模态转化
- 模态转化 Translation/映射 Mapping:转化也称为映射,负责将一个模态的信息转换为另一个模态的信息。常见的应用包括:
(1)机器翻译(Machine Translation):将输入的语言A(即时)翻译为另一种语言B。类似的还有唇读(Lip Reading)和语音翻译 (Speech Translation),分别将唇部视觉和语音信息转换为文本信息。
(2)图片描述(Image captioning) 或者视频描述(Video captioning): 对给定的图片/视频形成一段文字描述,以表达图片/视频的内容。
(3)语音合成(Speech Synthesis):根据输入的文本信息,自动合成一段语音信号。
3 多模态对齐
- 模态对齐 Alignment:负责对来自同一个实例的不同模态信息的子分支/元素寻找对应关系。
(1)对应关系可以是时间维度的。如,将一组动作对应的视频流同骨骼图片对齐。类似的还有电影画面-语音-字幕的自动对齐。
(2)对齐又可以是空间维度的,比如图片语义分割 (Image Semantic Segmentation),尝试将图片的每个像素对应到某一种类型标签,实现视觉-词汇对齐。
4 多模态融合
- 多模态融合 Multimodal Fusion:负责联合多个模态的信息,进行目标预测(分类或者回归),属于 MMML 最早的研究方向之一,也是目前应用最广的方向,它还存在其他常见的别名,例如多源信息融合(Multi-source Information Fusion)、多传感器融合(Multi-sensor Fusion)。按照融合的层次,可以将多模态融合分为:
- pixel level:应对原始数据进行融合。
- feature level :对抽象的特征进行融合
- early:表示融合发生特征抽取的早期
- late fusion:表示融合发生特征抽取的晚期 - decision level:对决策结果进行融合
- hybrid:混合融合多种融合方法
5 协同学习
-
协同学习 Co-learning:协同学习是指使用一个资源丰富的模态信息来辅助另一个资源相对贫瘠的模态进行学习。
迁移学习(Transfer Learning)如初学者尝试将 ImageNet 数据集上学习到的权重,在自己的目标数据集上进行微调。迁移学习和协同训练(Co-training)。
迁移学习比较常探讨的方面目前集中在领域适应性(Domain Adaptation)问题上,即如何将train domain上学习到的模型应用到 application domain。
迁移学习中还有零样本学习(Zero-Shot Learning)和一样本学习(One-Shot Learning)协同训练(Co-training ),它负责研究如何在多模态数据中将少量的标注进行扩充,得到更多的标注信息。
三、常见多模态任务
1. 跨模态预训练
- 图像/视频与语言预训练
- 跨任务预训练
2. Language-Audio
- Text-to-Speech Synthesis: 给定文本,生成一段对应的声音。
- Audio Captioning:给定一段语音,生成一句话总结并描述主要内容。(不是语音识别)
3. Vision-Audio
- Audio-Visual Speech Recognition(视听语音识别):给定某人的视频及语音进行语音识别。
- Video Sound Separation(视频声源分离):给定视频和声音信号(包含多个声源),进行声源定位与分离。
- Image Generation from Audio: 给定声音,生成与其相关的图像。
- Speech-conditioned Face generation:给定一段话,生成说话人的视频。
- Audio-Driven 3D Facial Animation:给定一段话与3D人脸模版,生成说话的人脸3D动画。
4. Vision-Language
- Image/Video-Text Retrieval (图(视频)文检索): 图像/视频<–>文本的相互检索。
- Image/Video Captioning(图像/视频描述):给定一个图像/视频,生成文本描述其主要内容。
- Visual Question Answering(视觉问答):给定一个图像/视频与一个问题,预测答案。
- Image/Video Generation from Text:给定文本,生成相应的图像或视频。
- Multimodal Machine Translation:给定一种语言的文本与该文本对应的图像,翻译为另外一种语言。
- Vision-and-Language Navigation(视觉-语言导航): 给定自然语言进行指导,使得智能体根据视觉传感器导航到特定的目标。
- Multimodal Dialog(多模态对话): 给定图像,历史对话,以及与图像相关的问题,预测该问题的回答。
5. 定位相关的任务
- Visual Grounding:给定一个图像与一段文本,定位到文本所描述的物体。
- Temporal Language Localization: 给定一个视频即一段文本,定位到文本所描述的动作(预测起止时间)。
- Video Summarization from text query:给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,预测视频关键帧(或关键片段)组合为一个短的摘要视频。
- Video Segmentation from Natural Language Query: 给定一段话(query)与一个视频,分割得到query所指示的物体。
- Video-Language Inference: 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义。
- Object Tracking from Natural Language Query: 给定一段视频和一些文本,进行定位匹配。
- Language-guided Image/Video Editing: 一句话自动修图。给定一段指令(文本),自动进行图像/视频的编辑。
6. 更多模态
- Affect Computing (情感计算):使用语音、视觉(人脸表情)、文本信息、心电、脑电等模态进行情感识别
- Medical Image:不同医疗图像模态如CT、MRI、PET
- RGB-D模态:RGB图与深度图(感兴趣)
- RGB-T模态:RGB图与热红外图 (感兴趣)
- RGB-L模态:RGB图与LIDAR (感兴趣)
四、单模态特征表示
- 模态表示是多模态深度学习的基础,可以分为单模态表示和多模态表示。
- 单模态表示是指对单个模态信息进行线性或者非线性映射,产生单个模态信息的高阶语义特征表示。
- 多模态表示基于单模态表示,并对单模态表示的结果进行约束。
1. 文本模态的表示
(1)文本模态的独热表示
- 矩阵 X = [ x 1 , x 2 , . . . . . . , x n ] T X=[x_1,x_2,......,x_n]^T X=[x1,x2,......,xn]T表示一个句子,其中 x i x_i xi是第i个单词的独热表示向量。 x i x_i xi是一个维度等于词典包含的单词个数且元素取值为0,1的向量,且只有一个元素值为1,其余都为0。值为1的元素在向量中的位置与 x i x_i xi所表示的单词在词典中的位置坐标相同。
(2)文本模态的低维空间表示
- 分布性假设指一个单词或字包含的信息被其上下文中的单词确定, 而不是由单词或字本身决定, 例如北京、东京等首都城市名称上下文中的单词相似程度较高, 这类单词或字的语义信息就相近。
- 用 x ′ = x W x'=xW x′=xW线性方程创建一个语义空间,其中 x x x为一个单词或字的独热表示向量, W W W为一个在神经网络模型上学习得到的转换矩阵, x ′ x' x′是该单词或字在语义空间中的向量, 在语义空间中, 包含的信息相近的单词或字的表示向量距离较近。
(3)文本序列模态的词袋表示
- 单词序列指长度不定的, 单词顺序明确的单词串, 包括短语、句子、段落和文档。假定 x x x表示一个单词序列, x x x是一个维度等于词典包含的单词个数,且元素取值为 0,1 的向量, 值为1的元素在向量中的位置与单词序列中包含的所有单词在词典中的位置相同, 其余元素为 0 。
- 词袋表示忽略了词语在单词序列中的先后顺序, 考虑词语顺序后, 词袋模型衍生出句子 n-grams 词袋模型。词袋表示和 n-grams 词袋表示的语言模型常能获得较准确的结果, 但是都没有考虑单词的语义信息。
(4)文本序列模态的低维空间表示
- 指获取文本序列模态的语义表示,即将文本序列映射到语义空间中。在早期的获取单词序列模态的语义表示的探索中,最简单的方法就是加权平均单词序列中各单词的语义表示向量,还有一种较复杂的方法是按照句子解析树的单词顺序,将句子组织为矩阵。这两种方法都有各自的缺点,前者在加权平均的过程中忽略了单词先后顺序, 后者的核心是句子的解析, 其适用对象局限于句子。
- 为解决这些不足, 研究人员提出了递归神经网络,由于递归神经网络的输入序列长度可变以及当前输出与之前输入有关等特性, 递归神经网络成为句子模态处理中非线性映射的主流模型,而目前主流的表示方法是预训练文本模型例如:BERT。
2. 视觉模态的表示
-
视觉模态分为图像模态和视频模态,视频模态在时间维度上展开后是一个图像序列。因此,学习视觉模态的向量表示的关键问题是学习图像模态的向量表示。
(1)图像模态的表示 -
在深度学习中,卷积神经网络是在多层神经网络的基础上发展起来针对图像而特别设计的一种深度学习方法。
-
经典的卷积神经网络如 LeNet-5、AlexNet、 VGG、GoogLeNet、ResNet和CapsNet,将卷积神经网络的卷积和池化操作理解为产生图像模态矩阵表示的过程,将全连接层或全局均值池化层的输入理解为图像模态的向量表示。
LeNet-5
- 能以极高的精度实现手写体数字和字母的识别,且应用于信封邮编识别和车牌识别中.
- LeNet-5 的输入为包含数字或字母的灰度图像,经过卷积和池化后产生特征图像,即图像模态的矩阵表示,特征图像经过维度变化后获得全连接层的输入,即图像模态的向量表示。
AlexNet
- 通过更多的卷积和池化操作以及归一化处理和 dropout 等训练方法,在网络深层的卷积层和池化层获得图像的矩阵表示, 即通过增加网络深度获取了包含图像深度语义信息的特征表示。
VGG
- 与 AlexNet 增加神经网络深度的方式不同,VGG通过构建含有多个卷积子层的卷积层实现网络深度的拓展,它每层都有 2~4 个卷积子层,用较小的卷积核和多个卷积层实现了对图片特征的精细抓取。
- VGG 的结构使得其能深度提取图像中的精细的语义特征,获得更好的图像模态表示。 为获得更好的图像模态表示,研究者不断地尝试增加网络的深度,但是发现当网络深度增加到一定程度后网络性能逐渐变差,获得的图像模态表示反而不能更好地提取图像模 态信息。
ResNet
- 是在增加网络深度的研究方向上进行了突破性探索的深度卷积网络,由融合了恒等映射和残差映射的 构造性模块堆栈后构成。
- 当在网络已经到达最优情况下继续向深层网络运算时,构造性模块中的残差映射将被置 0,只剩下恒等映射,这样使网络在更深的网络层上也处于最优。
NIN
- 提出了卷积层 的改进算法 Mlpconv 层,Mlpconv 层在每个感受野中进行更 加复杂的运算,获得高度非线性的图像的矩阵表示,并且 NIN 还使用全局均值池化代替全连接层,产生图像的向量表示, 并提高网络的泛化能力。
GoogLeNet
- GoogLeNet提出 Inception 模块。Inception 模块具有高效表达特征的能力,它包含 1x1、3x3、5x5 三种尺寸的卷积核,以及一个 3x3 的下采样,不同尺寸的卷积核赋给 Inception 模块提取不同尺寸的特征的能力。Inception 模块从纵向和横向上,增加了卷积层 的深度,使得 GoogLeNet 能够产生更抽象的图像模态的矩阵 表示。
CapsNet
- 尽管卷积神经网络提取的特征表示已经能够很好地包含图像中的语义信息,但是它并没有包含图像中实例的方向和空间信息,并且池化层必然会损失一些有效信息。
- CapsNet 是卷积神经网络 的一种拓展,它的基本组成单元是 capsule。capsule是一组 神经元,其输入和输出都是向量形式,向量中的每个元素都是图像中某个实体特征的参数表示,并且相邻的两个 capsule 层通过动态路由算法相连,实现参数选择。因此, CapsNet能够在每个 capsule 层上产生包含图像中实例的方向和空间信息的向量表示,并且使用动态路由算法代替池化层,避免了有效信息的损失。
(2)视频模态的表示
-
视频为在时间维度上的图像序列,它自然地拥有空间属性和时间属性。
- 空间属性指图像序列中每个图像包含的信息
- 时间属性指图像序列中相邻图像的相互作用信息
- 视频模态的表示应该包含视频的空间和时间两个属性信息
-
视频的空间属性主要由卷积神经网络提取,时间属性由卷积神经网络或长短记忆神经网络对视频中邻近的图像帧包含的运动信息提取。
-
视频模态的表示分成单通道卷积神经网络、双通道卷积神经网络和混合神经网络三种。下图分别表示单通道卷积神经网络和双通道卷积神经网络的结构。

单通道卷积神经网络
- 处理对象为视频中一段连续的图像帧,它用一个卷积神经网络完成这段连续的图像中的时间和空间信息融合,并在卷积神经网络的全连接层前产生这段连续的图像帧的向量表示。
- 单通道卷积神经网络提取视频的时空属性常有两种方式:
a) 改变卷积神经网络的结构,在其输入端或输出端融合视频的时间属性和空间属性。
b) 采用3D 卷积核,使用卷积计算融合视频的时间属性和空间属性。
双通道卷积神经网络
- 处理对象也是视频中一段连续的图像帧,它用两个卷积神经网络分别学习这段连续的图像帧中的时间属性和空间属性,并在两个网络的全连接层前产生这段连续的图像帧的时间属性表示和空间属性表示。
- 双通道卷积神经网络的输入包含图像帧输入和运动图像输入,图像帧输入为这段连续的图像帧中的一个图像,其包含这段图像帧中的空间信息,运动图像输入为这段连续的图像帧通过光学等技术处理产生后的向量图,如光流位移场叠加等,其包含了这段图像帧中的时间信息。
混合神经网络
- 由于 LSTM 神经网络对时间序列拟合的优秀性能,研究者将 LSTM 引入到上述两种网络结构中,构造混合神经网络。 混合神经网络的基本思想是将卷积神经网络的输出作为 LSTM 神经网络的输入,将视频中的图像帧或运动图像按照时间顺序依次输入卷积神经网络,卷积神经网络在每个时刻都会产生输入的图像帧或运动图像的向量表示;同时 LSTM会读取每个时刻的图像帧或运动图像的向量表示并产生一个隐变量,该隐变量随着时间更新。
3. 声音模态的表示
- 与其他信号一样,声音模态的表示就是提取声音信号的语义特征向量。在当前的包含神经网络结构的声音处理模型 中,声音模态的表示主要包含两个过程:
- 声音模拟信号转换为声音数字信号并完成特征向量的提取;
- 提取特征向量的高阶表示。
声音特征向量的提取
声音是模拟信号,声音的时域波形只代表声压随时间变化的关系,不能很好地体现声音的特征。因此,在声音特征提取时,首先应将采集到的语音信号数字化,转换为便于计算机存储和处理的离散的数字信号序列;然后利用数字信号处理技术对离散的数字信号序列进行声学特征向量的提取。当前的声音信号的处理技术主要有傅里叶变换、线性预测以及倒谱分析等。
声音特征向量的提取
提取特征向量的高阶表示在用神经网络识别声音时,提取特征向量的高阶表示是指使用神经网络对提取的声音特征向量进行多级非线性映射, 学习特征向量中包含的不同抽象层次的信息。
4. 深度图模态的表示
- 在3D计算机图形中,Depth Map(深度图)是包含与视点的场景对象的表面的距离有关的信息的图像或图像通道。其中,Depth Map 类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系。
5. 热红外模态的表示
- Cross-Modality Image Matching Network With Modality-Invariant Feature Representation for Airborne-Ground Thermal Infrared and Visible Datasets
- 关于红外行人重识别的模型方案
- [2020 AAAI] Cross-Modality Paired-Images Generation for RGB-Infrared Person Re-Identification
- [2020 arxiv] Cross-Spectrum Dual-Subspace Pairing for RGB-infrared Cross-Modality Person Re-Identification
- [2020 CVPR] Hi-CMD Hierarchical Cross-Modality Disentanglement for Visible-Infrared Person Re-Identification
- [2020 arxiv] RGB-IR Cross-modality Person ReID based on Teacher-Student GAN Model
- [2020 IJCAI] A Similarity Inference Metric for RGB-Infrared Cross-Modality Person Re-identification
(待完善)
6. 多光谱模态的表示
(待完善)
7. LIDAR模态的表示
(待完善)
五、多模态特征表示(Multimodal Representation)
-
表征学习是多模态任务的基础,特征表示主要任务是学习如何更好的提取和表示多模态数据的特征信息,以利用多模态数据的互补性。其中包含了一些开放性问题,例如:
- 如何结合来源不同的异质数据,
- 如何处理不同模态的不同噪声等级,
- 测试样本的某种模态缺失怎么办。
-
Joint 注重不做多模态的互补性,融合多个输入模态 x 1 , x 2 x_1,x_2 x1,x2获得多模态表征 x m = f ( x 1 , x 2 , . . . , x n ) x_m=f(x_1,x_2,...,x_n) xm=f(x1,x2,...,xn),从而使用 x m x_m xm完成某种预测任务。网络优化目标是某种预测任务的性能。
-
Coordinated结构并不寻求融合而是建模多重模态数据间的相关性,他讲多个(通常为两个)模态映射到协作空间,表示为 f ( x 1 ) g ( x 2 ) f(x_1)~g(x_2) f(x1) g(x2),其中~表示一种协作关系。网络优化目标是这种协作关系(通常是相似性,即最小化cosine距离等变量)
-
Joint Representation和Coordinated Representation区别
(1)联合特征表示将各模态信息映射到相同的特征空间中,而协同特征表示分别映射每个模态的信息,但是要保证映射后的每个模态之间存在一定的约束,使它们进入并行的相互映射的协同空间。(投影到分离但相关的空间)
(2)联合特征表示主要用于在训练和测试阶段都是多模态数据的任务。
(3)协同特征表示是为每个模态学习单独的特征提取模型,通过一个约束来协同不同的模态,更适合于在测试时只有一种模态数据的任务,如:多模态检索和翻译。
(4)协同架构包括跨模态相似模型和典型相关分析,其目的是寻求协调子空间中模态间的关联关系;由于不同模态包含的信息不一样,协同方法有利于保持各单模态独有的特征和排它性:- 协同架构在跨模态学习中已经得到广泛应用,主流的协同方法是基于交叉模态相似性方法,该方法旨在通过直接测量向量与不同模态的距离来学习一个公共子空间。而基于交叉模态相关性的方法旨在学习一个共享子空间,从而使不同模态表示集的相关性最大化。
- 交叉模态相似性方法在相似性度量的约束下保持模态间和模态内的相似性结构,期望相同语义或相关对象的跨模态相似距离尽可能小,不同语义的距离尽可能大。
- 与其它框架相比,协同架构的优点是每个单模态都可以独立工作,这一特性有利于跨模式迁移学习,其目的是在不同的模态或领域之间传递知识。缺点是模态融合难度较大,使跨模态学习模型不容易实现,同时模型很难在两种以上的模态之间实现转移学习。
五、跨模态对齐(Multimodal Alignment)
- 跨模态对齐目的是挖掘多模态数据的子元素之间的关联性(辨别来自两个或两个以上的不同模态元素之间的关系),例如visual grounding(视觉定位)任务。
-
对齐广泛应用于多模态任务中,根据对齐任务的分类,具体的应用方式包括显式对齐和隐式对齐:
(1)显式对齐
- 显式对齐。如果一个模型的优化目标是最大化多模态数据的子元素的对齐程度,则称为显示对齐。包括无监督和有监督方法。无监督对齐:给定两个模态的数据作为输入,希望模型实现子元素的对齐,但是训练数据没有“对齐结果”的标注,模型需要同时学习相似度度量和对齐方式。而有监督方法存在标注,可训练模型学习相似度度量。Visual grounding便是有监督对齐的任务,而weakly-supervised visual grounding是无监督对齐的任务。
(2)隐式对齐
- 隐式对齐。如果模型的最终优化目标不是对齐任务,对齐过程仅仅是某个中间(或隐式)步骤,则称为隐式对齐。早期基于概率图模型(如HMM)的方法被应用于文本翻译和音素识别中,通过对齐源语言和目的语言的单词或声音信号与音素。但是他们都需要手动构建模态间的映射。最受欢迎的方式是基于注意力机制的对齐,我们对两种模态的子元素间求取注意力权重矩阵,可视为隐式地衡量跨模态子元素间的关联程度。在图像描述,这种注意力被用来判断生成某个单词时需要关注图像中的哪些区域。在视觉问答中,注意力权重被用来定位问题所指的图像区域。很多基于深度学习的跨模态任务都可以找到跨模态注意力的影子。
-
根据对齐的方法,将模态对齐分为:注意力对齐和语义对齐。
(1)注意力对齐
注意力对齐,对于机器翻译、图像标注、语音识别等模态传译的任务上应用较多,因为模态传译的过程中存在模态元素之间的转换,转换结果的对齐要通过对齐算法,尤其是注意力对齐算法。分为软注意力,硬注意力。

以机器翻译为例,如上图所示,这是软注意力模型,这种注意力利用解码器——即双向RNN提取单词的上下文语义特征表示,后通过解码器——即RNN将上次预测的单词与注意力加权下的单词特征表示输入预测这次单词(最大后验概率)完成对齐。(2)语义对齐
语义对齐最主要的实现方式就是处理带有标签的数据集并产生语义对齐数据集,用深度学习模型去学习语义对齐数据集中的语义对齐信息。
3 讨论
- 讨论:对齐可以作为一个单独的任务,也可以作为其他任务的隐式特征增强手段。多模态对齐可挖掘子元素间的细粒度交互,同时有可解释性,被广泛应用。但多模态对齐面临如下挑战:仅有少量数据集包含显式的对齐标注;跨模态度量难以设计;可能存在多种对齐,也可能存在某些元素无法在其他模态中找到。
六、多模态融合
1 前言
- 多模态融合的主要目标是缩小模态间的异质性差异,同时保持各模态特定语义的完整性,并在深度学习模型中取得最优的性能。
- 多模态融合离不开数据表达形式,图像分支的数据表示较简单,一般均指RGB格式或灰度图,但激光雷达分支对数据格式的依赖度较高,不同的数据格式衍生出完全不同的下游模型设计,总结来说包含三个大方向:基于点、基于体素和基于二维映射的点云表示。
2 多模态融合架构(神经网络模型的基本结构形式)
- 多模态融合架构分为三类联合(Joint)架构、协作(Coordinated)架构和编解码(Encode-Decode)架构。
- 三种融合架构在视频分类、情感分析、语音识别等许多领域得到广泛应用,且涉及图像、视频、语音、文本等融合内容,具体应用情况如下表所示。

联合架构
-
多模态联合架构的关键是实现特征“联合”,具体有“加”联合和“乘”联合。
-
-“加”联合方法:属于最简单的方法是直接连接,该方法在不同的隐藏层实现共享语义子空间,将转换后的各个单模态特征向量语义组合在一起,从而实现多模态融合,如公式:
z = f ( w 1 T v 1 + . . . + ( w n T v n ) z = f(w^T_1v_1+...+(w^T_nv_n) z=f(w1Tv1+...+(wnTvn)
上式中,z是共享语义子空间中的输出结果,v是各单模态的输入,w是权重,下标表示不同的模态,通过映射f将所有支模太语义转换到共享子空间。 -
“乘”联合方法:将语言、视频和音频等模态融合在统一的张量中,而张量是所有单模态特征向量的输出乘积构成的,如下公式所示:
z = [ v 1 1 ] ⊗ . . . ⊗ [ v n 1 ] z=\begin{bmatrix} v^1\\ 1 \end{bmatrix} \otimes ...\otimes \begin{bmatrix} v^n\\ 1 \end{bmatrix} z=[v11]⊗...⊗[vn1]
其中,z表示融合张量后的结果输出,v表示不同的模态, ⊗ \otimes ⊗表示外积算子。 -
尽管加联合简单且容易实现,但是其特征向量语义组合易造成后期语义丢失,使模型性能降低。而“乘”联合方法弥补了这一不足,通过张量计算使特征语义得到更“充分”融合,最常见的方法是深度神经网络, 如的多模态情感预测模型由包括许多内部乘积的连续神经层组成,充分利用深度神经网络的多层性质,将不同模态有序安排在不同层中,并在模型训练过程中动态实现向量语义组合。
-
多模态联合框架的优点是融合方式简单,且共享子空间往往具备语义不变性,有助于在机器学习模型中将知识从一种模态转移到另一种模态。缺点是各单模态语义完整性不易在早期发现和处理。
协同架构
- 协同架构包括跨模态相似模型和典型相关分析,其目的是寻求协调子空间中模态间的关联关系;由于不同模态包含的信息不一样,协同方法有利于保持各单模态独有的特征和排它性。

- 协同架构在跨模态学习中已经得到广泛应用,主流的协同方法是基于交叉模态相似性方法,该方法旨在通过直接测量向量与不同模态的距离来学习一个公共子空间。而基于交叉模态相关性的方法旨在学习一个共享子空间,从而使不同模态表示集的相关性最大化。
- 交叉模态相似性方法在相似性度量的约束下保持模态间和模态内的相似性结构,期望相同语义或相关对象的跨模态相似距离尽可能小,不同语义的距离尽可能大。 模态间排名方法用于完成视觉和文本融合任务,将视觉和文本的匹配嵌入向量表示为, 融合目标用一个损失函数表示。
- 与其它框架相比,协同架构的优点是每个单模态都可以独立工作,这一特性有利于跨模式转移学习,其目的是在不同的模态或领域之间传递知识。缺点是模态融合难度较大,使跨模态学习模型不容易实现,同时模型很难在两种以上的模态之间实现转移学习。
编解码架构(自监督)
- 编解码器架构是用于将一个模态映射到另一个模态的中间表示。编码器将源模态映射到向量 v 中,解码器基于向量 v 将生成一个新的目标模态样本。该架构在图像标注、图像合成、视频解码等领域有广泛应用。

- 目前,编解码器架构在研究中重点关注共享语义捕获和多模序列的编解码两个问题。为了更有效地捕获两种模态的共享语义,一种流行的解决方案是通过一些正则化术语保持模态之间的语义一致性。必须确保编码器能正确地检测和编码信息,而解码器将负责推理高级语义和生成语法,以保证源模态中语义的正确理解和目标模态中新样本的生成。为了解决多模序列的编码和解码问题,关键是训练一个灵活的特征选择模块,而训练序列的编码或解码可以看作一个顺序决策问题,因此通常会采用决策能力强的模型和方法解决。例如,深度强化学习(Deep Reinforcement Learning,DRL)是一种常用的多模序列编解工具。
- 与其它框架相比,编解码器框架的优点是能够在源模态基础上生成新的目标模态样本。其缺点是每个编码器和解码器只能编码其中一种模态。
3 分类方式
分类方式一
多模态数据融合主要可分为三种方式:
- 前端融合(early-fusion)或数据水平融合(data-level fusion):通过空间对齐直接融合不同模态的原始传感器数据。
- 前端融合将多个独立的数据集融合成一个单一的特征向量,然后输入到机器学习分类器中。
- 由于多模态数据的前端融合往往无法充分利用多个模态数据间的互补性,且前端融合的原始数据通常包含大量的冗余信息。
- 因此,多模态前端融合方法常常与特征提取方法相结合以剔除冗余信息,如主成分分析(PCA)、最大相关最小冗余算法(mRMR)、自动解码器(Autoencoders)等。
- 中间融合(深度融合\特征级融合):指通过级联或者元素相乘在特征空间中融合跨模态数据。
- 需要将不同的模态数据先转化为高维特征表达,再于模型的中间层进行融合。
- 以神经网络为例,中间融合首先利用神经网络将原始数据转化成高维特征表达,然后获取不同模态数据在高维空间上的共性。中间融合方法的一大优势是可以灵活的选择融合的位置。
- 后端融合(late-fusion)或决策水平融合(decision-level fusion):指将各模态模型的预测结果进行融合,做出最终决策。即将不同模态数据分别训练好的分类器输出打分(决策)进行融合。这样做的好处是,融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关、互不影响,不会造成错误的进一步累加。
- 常见的后端融合方式包括最大值融合(max-fusion)、平均值融合(averaged-fusion)、 贝叶斯规则融合(Bayes’rule based)以及集成学习(ensemble learning)等。
- 其中集成学习作为后端融合方式的典型代表,被广泛应用于通信、计算机识别、语音识别等研究领域。
分类方式二
也可分为强融合、弱融合,强融合进一步细分为:前融合、深度融合、不对称融合和后融合。
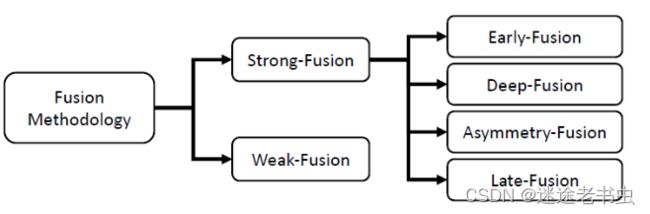
强融合:

前融合案例:

深度融合案例:

后融合案例:

不对称融合案例:

分类方式三
- 模型无关的方法(Model-agnostic approaches)不依赖具体机器学习方法(可以兼容任何一种分类器或者回归器)
(1)早期融合:提取特征后简单连接,利用低水平特征间的相关性和相互作用,训练容易(特征级的融合,多模态表示的前期尝试)不过无法充分利用多个模态数据间的互补性,且存在信息冗余问题(可由PCA,AE等方法缓解)
(2)晚期融合:针对不同的模态训练不同的模型,然后进行集成,更好地对每种模态数据进行建模(不融合,类似继承学习),模型独立,鲁棒性强。融合的方式即在特征生成过程中(如多层神经网络的中间)进行自由的融合,从而实现更大的灵活性,本质上忽略了模态之间的低水平交互作用,即底层特征之间的关系(推理结果融合)可以较简单地处理数据的异步性。
(3)混合融合:多者结合 - 基于模型的方法(Model-based approaches)
(1)基于内核的方法(Multiple kernel learning):SVM的扩展,不同模态不同内核,灵活选择kernel可以更好的融合异构数据,主要优势是MKL的损失函数是凸函数,可以得到全局最优解,模型训练可以使用标准的优化package和全局优化方法,劣势在于测试时对于数据集的依赖推理速度慢,缺点在于测试期间依赖于训练数据(sv),测试慢内存大。
(2)概率图模型(Graphical models):生成模型(联合概率)和概率模型(条件概率),耦合和阶乘隐马尔可夫模型以及动态贝叶斯网络,CRF图模型能够很容易的发掘数据中的空间和时序结构,同时可以将专家知识嵌入到模型中,模型也可解释。
(3)神经网络模型(Neural networks):多模态特征提取部分和多模态融合部分可以进行端到端的训练且能够学习其他方法难以处理的复杂决策边界。神经网络方法的主要缺点就是可解释性差以及需要依赖大量高质量的训练数据。
- 讨论:多模态融合是依赖于任务和数据的,现有工作中常常是多种融合手段的堆积,并未真正统一的理论支撑。对于这种由任务/数据所导致的融合策略的选择问题,十分适合用Neural Architecture Search高效且自动地搜索。当然,多模态融合仍存在的挑战:
- 不同模态的序列信息可能没有对齐;
- 信号间的关联可能只是补充(仅提高鲁棒性而无法增大信息量)而不是互补;
- 不同数据可能存在不同程度的噪声。
七、多模态模型
(待完善)
八、多模态应用
多模态融合是将来自多种不同模态的信息进行整合,用于分类任务或回归任务。值得注意的是,在最近的工作中,对于像深度神经网络这样的模型,多模态表示和融合之间的界限已经模糊了,其中表示学习与分类或回归目标交织在一起。优点有三,一是对比单模态更加鲁棒,二是模态信息互补,三是其一模态信息缺失仍能运行。
1 视觉-音频识别
- 视觉-音频识别(Visual-Audio Recognition): 综合源自同一个实例的视频信息和音频信息,进行识别工作。

2 多模态情感分析
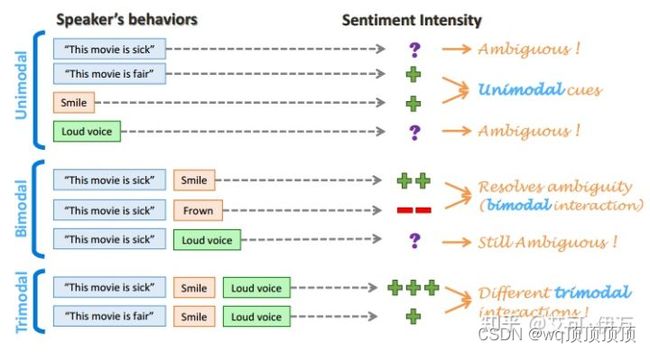
- 多模态情感分析(Multimodal sentiment analysis): 综合利用多个模态的数据(例如下图中的文字、面部表情、声音),通过互补,消除歧义和不确定性,得到更加准确的情感类型判断结果。
3 手机身份认证
- 手机身份认证(Mobile Identity Authentication): 综合利用手机的多传感器信息,认证手机使用者是否是注册用户。

九、多模态总结
1 多模态融合研究的难点
- 如何判断每个模态的置信水平
- 如何判断模态间的相关性
- 如何对多模态的特征信息进行降维
- 如何对非同步采集的多模态数据进行配准等
2 融合挑战
- 不同模态的信息在时间上可能不是完全对齐的,同一时刻有的模态信号密集,有的模态信号稀疏
- 融合模型很难利用模态之间的互补性
- 不同模态数据的噪音类型和强度可能不同
3 存在的问题
-
传感器固有问题:域偏差和分辨率与现实世界的场景和传感器高度相关[26]。这些缺陷阻碍了自动驾驶深度学习模型的大规模训练和实时。
-
域偏差:在自动驾驶感知场景中,不同传感器提取的原始数据伴随着严重的领域相关特征。不同的摄像头有不同的光学特性,而LiDAR可能会从机械结构到固态结构而有所不同。更重要的是,数据本身会存在域偏差,例如天气、季节或地理位置[6,71],即使它是由相同的传感器捕获的。这就导致检测模型的泛化性受到影响,无法有效适应新场景。这类缺陷阻碍了大规模数据集的收集和原始训练数据的复用性。因此,未来可以聚焦于寻找一种消除域偏差并自适应集成不同数据源的方法。
-
分辨率冲突:不同的传感器通常有不同的分辨率。例如,LiDAR的空间密度明显低于图像的空间密度。无论采用哪种投影方式,都会因为找不到对应关系而导致信息损失。这可能会导致模型被一种特定模态的数据所主导,无论是特征向量的分辨率不同还是原始信息的不平衡。因此,未来的工作可以探索一种与不同空间分辨率传感器兼容的新数据表示系统。
4 多模态融合首要解决的问题
- 如何获取多模态的表示【learn multimodal representations】
- 如何做各个模态的融合【fuse multimodal signals at various levels】
- 多模态的应用【multimodal applications】
十、推荐论文
相关综述:
- Atrey P K, Hossain M A, El Saddik A, et al. Multimodal fusion for multimedia analysis: a survey[J]. Multimedia systems, 2010, 16(6): 345-379.
- Ramachandram D, Taylor G W. Deep multimodal learning: A survey on recent advances and trends[J]. IEEE Signal Processing Magazine, 2017, 34(6): 96-108.
- Baltrušaitis T, Ahuja C, Morency L P. Multimodal machine learning: A survey and taxonomy[J]. IEEE Transactions on Pattern Analysis and - Machine Intelligence, 2018.
- Multimodal Machine Learning: A Survey and Taxonomy
- Representation Learning: A Review and New Perspectives
引用:
- https://zhuanlan.zhihu.com/p/497058659
- https://zhuanlan.zhihu.com/p/389287751
- https://zhuanlan.zhihu.com/p/475734302
- https://blog.csdn.net/weixin_42455006/article/details/124250910