数据挖掘竞赛——糖尿病遗传风险检测挑战赛进阶
本次比赛是一个数据挖掘赛,需要选手通过训练集数据构建模型,然后对验证集数据进行预测,预测结果进行提交。
本题的任务是构建一种模型,该模型能够根据患者的测试数据来预测这个患者是否患有糖尿病。这种类型的任务是典型的二分类问题(患有糖尿病 / 不患有糖尿病),模型的预测输出为 0 或 1 (患有糖尿病:1,未患有糖尿病:0)
赛事链接:https://challenge.xfyun.cn/topic/info?type=diabetes&option=tjjg
这次竞赛是来自DataWhale的一份数据挖掘相关的竞赛教程:
https://xj15uxcopw.feishu.cn/docx/doxcn5bbI3eupMF95XW5Y5ZM6jd
进阶版:https://xj15uxcopw.feishu.cn/docx/doxcnt2nNQXshdIU5IEQhjSfLcc
赛事Baseline请参考:https://blog.csdn.net/cyj972628089/article/details/125829573?spm=1001.2014.3001.5501
我在Datawhale提供的进阶版程序的基础上添加了一些自己的优化方法和思考,希望能跟大家一起分享。
糖尿病遗传风险检测挑战赛进阶
- 1. 数据预处理
- 2. 模型训练及预测
-
- 2.1 探究不同模型的效果
- 2.2 对排名前三的模型进行参数优化
- 2.3 对最佳模型(随机森林)进行进一步参数优化
- 2.4 模型训练和保存
-
- 2.4.1 训练所有数据集并保存
- 2.4.2 训练k个模型的结果取平均
- 最后
以下代码,请在jupyter notbook或python编译器环境中实现。
1. 数据预处理
导入第三方库:
import pandas as pd
import numpy as np
from sklearn import svm
import lightgbm
from lightgbm import LGBMClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
from sklearn.metrics import f1_score
导入数据并查看数据大小和类型:
train_df=pd.read_csv('data/train.csv',encoding='gbk')
test_df=pd.read_csv('data/test.csv',encoding='gbk')
print('训练集的数据大小:',train_df.shape)
print('测试集的数据大小:',test_df.shape)
print('-'*30)
print('训练集的数据类型:')
print(train_df.dtypes)
print('-'*30)
print(test_df.dtypes)
查看数据是否有缺失值:
#----------------查数据的缺失值----------------
print(train_df.isnull().sum())
print('-'*30)
print(test_df.isnull().sum())
#可以看到 训练集和测试集中都是舒张压有缺失值
对数据进行特征工程:
#这里将文本数据转成数字数据
#train_df['糖尿病家族史'].value_counts() #发现这一类有四个标签
dict_糖尿病家族史 = {
'无记录': 0,
'叔叔或姑姑有一方患有糖尿病': 1,
'叔叔或者姑姑有一方患有糖尿病': 1,
'父母有一方患有糖尿病': 2
}
train_df['糖尿病家族史'] = train_df['糖尿病家族史'].map(dict_糖尿病家族史)
test_df['糖尿病家族史'] = test_df['糖尿病家族史'].map(dict_糖尿病家族史)
#考虑到舒张压是一个较为重要的生理特征,并不能适用于填充平均值,这里采用填充为0的方法
train_df['舒张压'].fillna(0, inplace=True)
test_df['舒张压'].fillna(0, inplace=True)
#将数据中的出生年份换算成年龄
train_df['出生年份'] = 2022 - train_df['出生年份']
test_df['出生年份'] = 2022 - test_df['出生年份']
#将年龄进行一个分类
"""
>50
<=18
19-30
31-50
"""
def resetAge(input):
if input<=18:
return 0
elif 19<=input<=30:
return 1
elif 31<=input<=50:
return 2
elif input>=51:
return 3
train_df['rAge']=train_df['出生年份'].apply(resetAge)
test_df['rAge']=test_df['出生年份'].apply(resetAge)
#将体重指数进行一个分类
"""
人体的成人体重指数正常值是在18.5-24之间
低于18.5是体重指数过轻
在24-27之间是体重超重
27以上考虑是肥胖
高于32了就是非常的肥胖。
"""
def BMI(a):
if a<18.5:
return 0
elif 18.5<=a<=24:
return 1
elif 24<a<=27:
return 2
elif 27<a<=32:
return 3
else:
return 4
train_df['BMI']=train_df['体重指数'].apply(BMI)
test_df['BMI']=test_df['体重指数'].apply(BMI)
#将舒张压进行一个分组
"""
舒张压范围为60-90
"""
def DBP(a):
if a==0:#这里为数据缺失的情况
return 0
elif 0<a<60:
return 1
elif 60<=a<=90:
return 2
else:
return 3
train_df['DBP']=train_df['舒张压'].apply(DBP)
test_df['DBP']=test_df['舒张压'].apply(DBP)
#删除编号
train_df=train_df.drop(['编号'],axis=1)
test_df=test_df.drop(['编号'],axis=1)
#这里计算相对糖尿病家族史进行分组求平均值后的差值
"""train_df['口服耐糖量测试_diff'] = abs(train_df['口服耐糖量测试'] - train_df.groupby('糖尿病家族史').transform('mean')['口服耐糖量测试'])
test_df['口服耐糖量测试_diff'] = abs(test_df['口服耐糖量测试'] - test_df.groupby('糖尿病家族史').transform('mean')['口服耐糖量测试'])
train_df['胰岛素释放实验_diff'] = abs(train_df['胰岛素释放实验'] - train_df.groupby('糖尿病家族史').transform('mean')['胰岛素释放实验'])
test_df['胰岛素释放实验_diff'] = abs(test_df['胰岛素释放实验'] - test_df.groupby('糖尿病家族史').transform('mean')['胰岛素释放实验'])
train_df['舒张压_diff'] = abs(train_df['舒张压'] - train_df.groupby('糖尿病家族史').transform('mean')['舒张压'])
test_df['舒张压_diff'] = abs(test_df['舒张压'] - test_df.groupby('糖尿病家族史').transform('mean')['舒张压'])"""
#这里计算口服耐糖量相对年龄进行分组求平均值后的差值
train_df['口服耐糖量测试_diff'] = abs(train_df['口服耐糖量测试'] - train_df.groupby('rAge').transform('mean')['口服耐糖量测试'])
test_df['口服耐糖量测试_diff'] = abs(test_df['口服耐糖量测试'] - test_df.groupby('rAge').transform('mean')['口服耐糖量测试'])
train_df['胰岛素释放实验_diff'] = abs(train_df['胰岛素释放实验'] - train_df.groupby('rAge').transform('mean')['胰岛素释放实验'])
test_df['胰岛素释放实验_diff'] = abs(test_df['胰岛素释放实验'] - test_df.groupby('rAge').transform('mean')['胰岛素释放实验'])
train_df['舒张压_diff'] = abs(train_df['舒张压'] - train_df.groupby('rAge').transform('mean')['舒张压'])
test_df['舒张压_diff'] = abs(test_df['舒张压'] - test_df.groupby('rAge').transform('mean')['舒张压'])
构建训练集和测试集:
# 构建训练集和测试集
train_label=train_df['患有糖尿病标识']
train=train_df.drop(['患有糖尿病标识'],axis=1)
test=test_df
查看所有指标与标签之间的相关性:
print('查看训练集中数据的相关性')
print(train_df.corr()['患有糖尿病标识'])
运行后结果为:
查看训练集中数据的相关性
性别 0.031480
出生年份 0.068225
体重指数 0.377919
糖尿病家族史 0.005897
舒张压 0.098353
口服耐糖量测试 0.178133
胰岛素释放实验 0.156656
肱三头肌皮褶厚度 0.410667
患有糖尿病标识 1.000000
rAge 0.060672
BMI 0.183523
DBP 0.092075
口服耐糖量测试_diff 0.119368
胰岛素释放实验_diff 0.167193
舒张压_diff 0.008376
Name: 患有糖尿病标识, dtype: float64
剔除相关性低的指标,加快训练:
train=train.drop(['性别','糖尿病家族史','舒张压_diff'],axis=1)
test=test.drop(['性别','糖尿病家族史','舒张压_diff'],axis=1)
2. 模型训练及预测
2.1 探究不同模型的效果
#参数`random_state`用于控制随机状态,并没有一个确定的值
train_x,val_x,train_y,val_y=train_test_split(train,train_label,test_size=0.25,random_state=2020) #分割训练集和验证集
model={}
model['rfc']=RandomForestClassifier(random_state=2020)
model['gdbt']=GradientBoostingClassifier(random_state=2020)
model['lgbm']=LGBMClassifier(random_state=2020)
model['cart']=DecisionTreeClassifier(random_state=2020)
model['knn']=KNeighborsClassifier()
model['svm']=svm.SVC(random_state=2020)
model['lr']= make_pipeline(MinMaxScaler(),LogisticRegression(random_state=2020))
for i in model:
model[i].fit(train_x,train_y)
score=cross_val_score(model[i],val_x,val_y,cv=5,scoring='f1')
print('%s的f1为:%.3f'%(i,score.mean()))
运行后输出:
rfc的f1为:0.936
gdbt的f1为:0.930
lgbm的f1为:0.928
cart的f1为:0.910
knn的f1为:0.817
svm的f1为:0.767
lr的f1为:0.728
由此可得随机森林(rfc)、梯度提升决策树(gdbt)和轻量级的高效梯度提升树(lgbm)在参数默认时的表现最好。
2.2 对排名前三的模型进行参数优化
接下来可以在此基础上对他们分别进行参数调优,想要优化的参数可以自己确定。
#以上都是默认参数下的运行结果,发现rfc、gdbt、lgbm运行的效果最好,于是我们对可以搜索三个模型的最佳参数
model=['rfc','gbdt','lgbm']
temp=[]
rfc=RandomForestClassifier(random_state=0)
params={'max_depth':[1,3,5,7,9,11,13,15,17,19],'min_samples_leaf':[1,2,4,6]}
temp.append([rfc,params])
gbt=GradientBoostingClassifier(random_state=0)
params={'learning_rate':[0.01,0.05,0.1,0.15,0.2],'max_depth':[1,3,5,7,9]}
temp.append([gbt,params])
cart=LGBMClassifier(random_state=0)
params={'learning_rate':[0.01,0.05,0.1,0.15,0.2],'max_depth': range(3,8,2),'num_leaves':range(50, 170, 30)}
temp.append([cart,params])
for i in range(len(model)):
best_model=GridSearchCV(temp[i][0],param_grid=temp[i][1],refit=True,cv=5).fit(train,train_label)
print(model[i],':')
print('best parameters:',best_model.best_params_,best_model.best_score_)
运行后输出:
rfc :
best parameters: {'max_depth': 11, 'min_samples_leaf': 2} 0.9593688362919133
gbdt :
best parameters: {'learning_rate': 0.2, 'max_depth': 7} 0.9587771203155819
lgbm :
best parameters: {'learning_rate': 0.01, 'max_depth': 7, 'num_leaves': 50} 0.9568047337278106
得到最优参数后,将参数带回模型中,看看模型的优化效果:
# 带入上面得到的最优参数训练,看看优化效果
model={}
model['rfc']=RandomForestClassifier(max_depth=11,min_samples_leaf=2,random_state=2020)
model['gdbt']=GradientBoostingClassifier(learning_rate=0.2,max_depth=7,random_state=2020)
model['lgbm']=LGBMClassifier(learning_rate=0.01,max_depth=7,num_leaves=50,random_state=2020)
for i in model:
model[i].fit(train_x,train_y)
score=cross_val_score(model[i],val_x,val_y,cv=5,scoring='f1')
print('%s的f1为:%.3f'%(i,score.mean()))
运行后输出:
rfc的f1为:0.940
gdbt的f1为:0.937
lgbm的f1为:0.929
可以看到,参数优化后的参数与默认参数相比,效果都得到了不同程度的提升:
- rfc:0.936 → 0.94
- gdbt:0.930 → 0.937
- lgbm:0.928→0.929
如果我们增加待优化的参数数量,扩大参数的区间,可以获得更好的优化效果,但是会大大提高训练时间。
2.3 对最佳模型(随机森林)进行进一步参数优化
可以看到随机森林(rfc)的训练效果依然是最好的,因此我们可以对其更进一步的参数优化。
调参的方式总是根据数据的状况而定,没有办法一概而论。通过画学习曲线或者网格搜索,能够探索到调参边缘(代价是花费时间长),实际中,高手调参主要是依赖于经验。
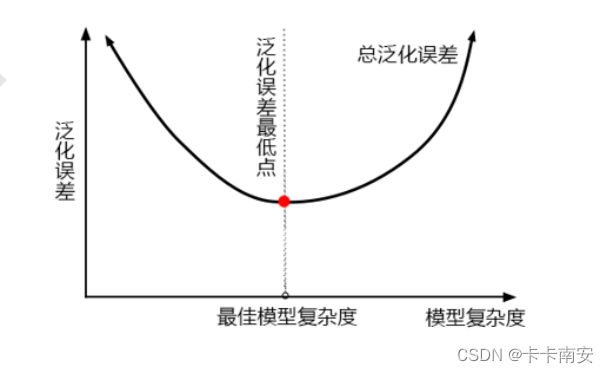
正确的模型调参思路:第一步是找准目标,一般来说这个目标是提升某个模型评估指标。例如对随机森林来说想要提升在未知数据上的准确率,找准目标后需要思考,模型在未知数据上的准确率受什么因素的影响。在机器学习中,用来衡量模型在未知数据上的准确率的指标,叫做泛化误差(Genelization Error)。
当模型在未知数据(测试集或者袋外数据)上表现糟糕时,认为模型的泛化程度不够,泛化误差大,模型的效果不好。泛化我误差受到模型的结构(复杂度)影响。
随机森林的参数详解可以参考:http://www.manongjc.com/detail/19-zloqbgaaxaqivmy.html
其中几个关键参数的含义为:
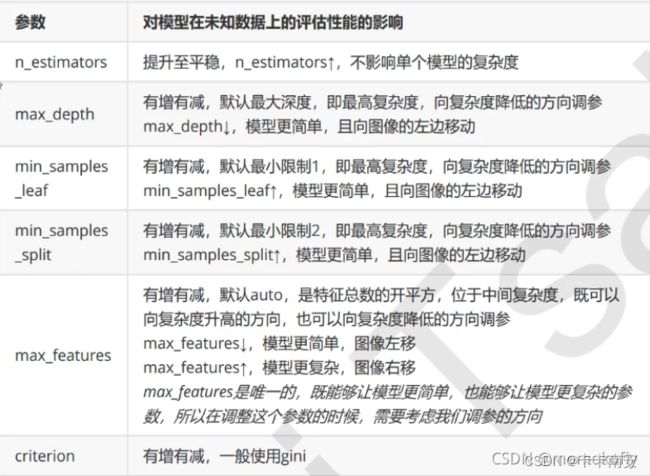
在前面我们调节了参数max_depth和min_sample_leaf后,模型的得分上升,这两个是用于降低模型复杂度的参数,因此我们的模型还处于最佳模型复杂度的右侧,因此我们可以在此基础上优化min_sample_split参数。
rfc=RandomForestClassifier(max_depth=11,min_samples_leaf=2,random_state=2020)
params={'min_samples_split':np.arange(2,10+2,2)}
best_model=GridSearchCV(rfc,param_grid=params,refit=True,cv=5).fit(train,train_label)
print('best parameters:',best_model.best_params_,best_model.best_score_)
运行后结果为:
best parameters: {'min_samples_split': 2} 0.9593688362919133
可以看到参数min_samples_split的大小为默认值,min_samples_split是减小模型复杂度的参数,说明模型已经处于最佳模型复杂度的左侧。大家还可以继续优化max_features和n_estimators等参数,这里我就不再演示。
2.4 模型训练和保存
2.4.1 训练所有数据集并保存
# 调好超参数后,训练所有的训练集
# 调好超参数后,训练所有的训练集
model=RandomForestClassifier(max_depth=11,min_samples_leaf=2,min_samples_split=2,random_state=2020)
model.fit(train,train_label)
pre_y=model.predict(test)
result=pd.read_csv('data/submit.csv')
result['label']=pre_y
result.to_csv('result.csv',index=False)
提交后分数为:0.93898
2.4.2 训练k个模型的结果取平均
这个也可用于模型超参数调优,每次将数据集分为K份,K-1份用于训练,1份用于验证,每训练一个模型得到一个测试结果,最终k个测试结果取平均作为最终结果。
下面程序中k为100:
n_splits = 100
def select_by_lgb(train_data,train_label,test_data,random_state=2020,n_splits=n_splits):
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
fold=0
result=[]
score=0
for train_idx, val_idx in kfold.split(train_data):
random_state+=1
train_x = train_data.loc[train_idx]
train_y = train_label.loc[train_idx]
test_x = train_data.loc[val_idx]
test_y = train_label.loc[val_idx]
#Ramdom Forest
clf=RandomForestClassifier(max_depth=11,min_samples_leaf=2,min_samples_split=2,random_state=2020)
model = clf.fit(train_x,train_y)
#gdbt
# clf=GradientBoostingClassifier(learning_rate=0.05,max_depth=7,n_estimators=500,random_state=0)
# model = clf.fit(train_x,train_y)
#lbgm
# clf=LGBMClassifier(objective='regression',learning_rate=0.01,metric='auc',max_depth=7,num_leaves=50,random_state=0)
# model = clf.fit(train_x,train_y)
val = model.predict(test_x)
y = np.int64(val>= 0.5)
a = f1_score(test_y, y, average='binary')
print("fl_score分数为:",a)
score += a
#分数高于0.9的才参与预测
if a > 0.9:
pre_y=model.predict(test_data)
result.append(pre_y)
fold+=1
print("fl_score平均分数为:",score/n_splits)
return result
#test_data就是100个模型的预测结果
test_data=select_by_lgb(train,train_label,test)
运行后输出为:
fl_score分数为: 0.9523809523809523
fl_score分数为: 0.9411764705882353
fl_score分数为: 0.9333333333333332
fl_score分数为: 0.9230769230769231
fl_score分数为: 0.9333333333333332
fl_score分数为: 1.0
fl_score分数为: 0.9333333333333333
···
fl_score分数为: 0.9714285714285714
fl_score分数为: 0.8837209302325583
fl_score分数为: 0.9444444444444444
fl_score分数为: 0.9387755102040816
fl_score分数为: 0.9545454545454545
fl_score平均分数为: 0.9440605311056551
pre_y=pd.DataFrame(test_data).T
#将预测的结果求取平均值,当然也可以使用其他的方法
pre_y['averge']=pre_y[[i for i in range(len(test_data))]].mean(axis=1)
#因为竞赛需要你提交最后的预测判断,而模型给出的预测结果是概率,因此我们认为概率>0.5的即该患者有糖尿病,概率<=0.5的没有糖尿病
pre_y['label']=pre_y['averge'].apply(lambda x:1 if x>=0.5 else 0)
#保存结果
result=pd.read_csv('data/submit.csv')
result['label']=pre_y['label']
result.to_csv('result.csv',index=False)
提交后分数为:0.92695
最后
虽然最终的分数也不是特别理想,但是也提供了一个优化的思路,通过参加这个比赛自己真的学到了很多关于数据挖掘、模型、优化等方面的知识,在这里非常感谢DataWhale,希望这个系列能一直做下去,越办越好!