论文分享:可微分架构搜索(DARTS)
目录
- 0 题目(期刊,团队)
- 1 背景
- 2 问题
- 3 现状&GAP
-
- 3.1 基于RL的NAS
- 3.2 基于进化算法的NAS
- 3.3 GAP
- 4 难点
- 5 创新点
- 6 内容
-
- 6.1 定义搜索空间
- 6.2 搜索空间连续化
- 6.3 近似梯度优化
- 7 验证
-
- 7.1 CNN验证
- 7.2 RNN验证
- 8 提问
-
- 8.1 关于背景、问题
- 8.2 关于现状、GAP、难点、创新点
- 8.3 关于内容
- 8.4 关于验证
0 题目(期刊,团队)
(1)题目
DARTS:Differential Architecture Search
(2)期刊
ICLR2019
(3)团队
卡耐基梅陇,deepmind
1 背景
图像识别
设计NN耗时——》AutoML
AutoML:自动特征工程,超参优化(NAS),算法选择
NAS:网络结构优化

2 问题
如何高效地搜索到一个性能良好的神经网络结构
3 现状&GAP
3.1 基于RL的NAS
NASNet、BlockQNN
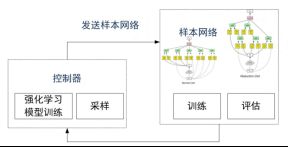
GAP:耗时,耗力
GPU days:使用一块GPU运行的天数
3.2 基于进化算法的NAS
AmoebaNet

GAP:耗时,耗力
3.3 GAP
计算量大,搜索效率极低
4 难点
搜索空间离散,结构参数爆炸性组合
每次迭代,从搜索空间采样评估网络,搜索效率低
5 创新点
将搜索空间连续化,用GD对参数连续优化

6 内容
6.1 定义搜索空间
启发式:
一个cell:具有n个节点的DAG,边=操作,节点=NN的层(特征图谱)
堆叠cell

6.2 搜索空间连续化
用softmax将α转成概率
将问题转换成权重、操作权重的共同学习

6.3 近似梯度优化
双层优化很难计算

实际计算时,没有等w收敛到最优解,只进行一次GD
7 验证
7.1 CNN验证
网络:
normal:输入维度不变,每个cell包含8个节点
reduction:输入维度减少一半
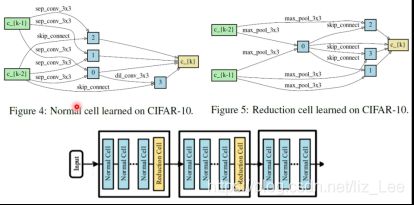
数据集:CIFAR10

7.2 RNN验证
单个cell
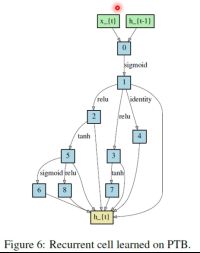
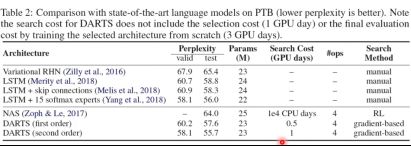
数据集:PTB
8 提问
8.1 关于背景、问题
(1)自动特征工程举例?
人工选择特征
自动特征选择:用NN去提取
(2)搜索空间大小是如何确定的,候选项是如何选择的?
人工确定
(3)深度和宽度超参,优化哪个好?
优化深度
(4)找到网络结构,需要训练吗?
有一篇文章:通过设计网络结构和激活函数,取消权重可以和带权重的有一样的效果,这篇不需要训练权重。
(5)对于CNN,需不需要自动特征工程环节?
深度学习可以自动提取特征,但是特征个数的无法确定
-对于CNN,特征的个数指的是什么?
(6)如何评估性能?因为评估不仅和架构有关,也和训练,样本集相关。
选择一个网络架构,训练,再用验证集去评估
(7)自动搜索网络结构,是否依旧需要调参?
仅实现了部分参数的自动选取,只关心结构
(8)试错法?
有策略
(9)网络结构选取,需要依赖什么专业知识,跟问题相关吗?
算法和ML领域的知识,和具体问题的机理模型相关知识也有关。
应用到新领域,陌生问题,不需要考虑物理知识?
(10)选出来的架构会不会和专业知识相悖?
验证结果发现性能相当
(11)需要完全重新训练吗?
一开始需要重新训练,后来会在评估策略上有一些创新
(12)输入变化,feature map大小变化,它怎么解决?
padding
(13)评估的时候,学习率等人工超参会不会优化,不同网络结构用统一的学习率?
学习率固定
两种对比方式:控制变量的对比、两种结构最佳超参的对比
8.2 关于现状、GAP、难点、创新点
(1)怎么保证α在空间中连续?
α是一个矢量,它本身连续
-怎么保证α可微?
把它softmax化,变成了概率
(2)创新点?怎么使它连续?
softmax公式
(3)α的定义是人工定义吗,需要先验吗?
是人工定义,也需要一定专业知识
-只针对CNN?
主要是CNN,也在RNN上做了验证
(4)α向量中的顺序也是可以优化的,文中是否没有考虑?
是的
(5)对操作做加权平均的含义?
对每个操作做加权平均,相当于对每个输出做加权平均
系数是需要被学出来
(6)和现状相比,文中结构变化很大了,搜索空间更大?
搜索空间没有变大,采样的子网络变多了
现状中的方法,不是网络结构复杂使得它效率低,而是它离散采样
8.3 关于内容
(1)cell具体指什么?
一个小型的NN
(2)softmax是推导出来,还是本身存在?
只是用了
(3)操作的选择是近似比如,0.7,那多个近似叠加不会对结果又影响吗?
不会
(4)cell是定好的,cell的个数是定好的?
是的
-相当于把大量超参,变为少量超参
(5)训练的时候,是先更新网络参数w,再更新α?
双层优化
-怎么保证收敛?
文中表明,不能保证一定收敛
(6)cell中为什么会有不连接的边?
有0操作
(7)目标是优化cell,那cell间如何连接,网络深度,宽度是定好的吗?
cell是串联起来的
一个cell的输出是下一个cell的输入
深度是cell个数,是定好的
宽度是cell中节点
(8)为什么剪枝,而不直接用0.8、0.2这些系数,要把0.2踢掉?
有可能是有计算效率的考虑
8.4 关于验证
(1)为什么要分为normal和reduction两种?
为了网络扩展,适用更多数据集,一个trick
-一个方法显著超越人类,那有没有被tensorflow收录,封装?