Fisher线性判别
Fisher线性判别
一、算法介绍
1.背景:
在应用统计方法解决模式识别问题时,一再碰到的问题之一就是维度问题,在低维空间里解析上或计算上行得通的方法,在高维空间里往往行不通。降低维度有时会成为处理实际问题的关键。
对于两分类问题,考虑把d维空间的样本投影到一条直线上,形成一维空间,即把数据压缩到一维,同时保持好的分类性能。
对于d维空间的样本,投影到一维坐标上,样本特征将混杂在一起,难以区分。Fisher判别法的目的就是要找到一个最适合的投影轴w,使两类样本在该轴上投影的交叠部分最少,从而使分类效果最佳。
2.Fisher线性判别:
Fisher判别法所要解决的基本问题:如何根据实际数据找到一条最好的、最易于分类的投影方向。
Fisher准则函数的基本思路:向量w的方向选择应能使两类样本投影的均值之差尽可能大些,而使类内样本的离散程度尽可能小。
3.Fisher分类器设计:

二、数据集描述:
1、Sonar数据集:
这是一个通过声纳声音从不同曲面反弹后返回的信息判断物质是金属还是岩石的数据集。
这个数据集共有208条记录,每条数据记录了60种不同的声纳探测的数据和一个分类结果,若是岩石则标记为R,若是金属则标记为M。
2、iris数据集:
iris数据集包含3类共150条记录,每类50个数据,每条记录都有4项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花属于(iris-setosa,iris-versicolour,iris-virginica)中的哪一品种。


三、在sonar数据集上验证算法
1、分离数据集 — 划分训练样本和测试样本:
选择将数据随机分成训练和测试,测试结果取10次平均。
划分的过程如下:
首先将两类样本分开,之后进行10次循环,每次在顺序被打乱的样本中取出训练样本,剩下的数据作为测试样本。分别取R类训练样本73个,M类训练样本84个。(按照训练数据75%,测试数据25%)。
2、实现过程
import numpy as np
import pandas as pd
dataset = pd.read_csv('/(你的路径)/sonar.all-data',header=None)
array = dataset.values
X = array[:,0:60].astype(float)#数据
Y = array[:,60]#类别
sonar1 = X[:97]
sonar2 = X[97:]
a = []
for i in range(10):
np.random.shuffle(sonar1)
np.random.shuffle(sonar2)
sonar1_train = sonar1[:73]
sonar2_train = sonar2[:84]
m1 = np.mean(sonar1,axis = 0)#计算样本均值
m2 = np.mean(sonar2,axis = 0)
mean_m1 = sonar1_train-m1#每类样本的类内离散度矩阵
s1 = np.zeros((60,60))
for i in range(73):
t = mean_m1[i]
s1 = s1 + t*t.reshape(60,1)
mean_m2 = sonar2_train-m2
s2 = np.zeros((60,60))
for i in range(84):
t = mean_m2[i]
s2 = s2 + t*t.reshape(60,1)
sw = s1+s2#总样本类内离散度矩阵
sw = np.linalg.inv(sw)#
w = np.dot((sw),(m1-m2))#最佳变换方向
w0 = 0.5*(np.dot(w.T,m1+m2))#阈值
#测试
kind1 = 0
kind2 = 0
test1 = sonar1[73:]
test2 = sonar2[84:]
for i in range(24):
y = np.dot(w.T,test1[i])
if y>=w0:
kind1 = kind1+1
for i in range(27):
y = np.dot(w.T,test2[i])
if y<w0:
kind2 = kind2+1
correct = (kind1 +kind2)/51
a.append(correct)
print(np.mean(a))
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
dataset = pd.read_csv('/ /sonar.all-data',header=None)
array = dataset.values
#分离两类数据集
X = array[:,0:60].astype(float)#数据
Y = array[:,60]#类别
sonar1 = X[:97]
sonar2 = X[97:]
a = []
t1 = []
t2 = []
fig = plt.figure()
for i in range(10):
count = i+1
np.random.shuffle(sonar1)
np.random.shuffle(sonar2)
sonar1_train = sonar1[:73]
sonar2_train = sonar2[:84]
#计算样本均值
m1 = np.mean(sonar1,axis = 0)
m2 = np.mean(sonar2,axis = 0)
#每类样本的类内离散度矩阵
mean_m1 = sonar1_train-m1
s1 = np.zeros((60,60))
for i in range(73):
t = mean_m1[i]
s1 = s1 + t*t.reshape(60,1)
mean_m2 = sonar2_train-m2
s2 = np.zeros((60,60))
for i in range(84):
t = mean_m2[i]
s2 = s2 + t*t.reshape(60,1)
sw = s1+s2
#最佳变换方向
sw = np.linalg.inv(sw)
w = np.dot((sw),(m1-m2))
#阈值
w0 = 0.5*(np.dot(w.T,m1+m2))
#print(w0)
#测试
t1 = []
t2 = []
kind1 = 0
kind2 = 0
test1 = sonar1[73:]
test2 = sonar2[84:]
for i in range(24):
y = np.dot(w.T,test1[i])
t1.append(y)
if y>=w0:
kind1 = kind1+1
#print(kind1)
for i in range(27):
y = np.dot(w.T,test2[i])
t2.append(y)
if y<w0:
kind2 = kind2+1
#print(kind2)
correct = (kind1 +kind2)/51
#print("第 %d 次测试的准确率:%d",%(count,correct))
a.append(correct)
#fig = plt.figure(figsize = (6,3))
ax = fig.add_subplot(5,2,count)
plt.ylim(0,2)
#plt.xlabel("test data")
b1 = [1 for i in range(24)]
b2 = [1 for i in range(27)]
plt.scatter(t1,b1,marker="*")
plt.scatter(t2,b2,marker="^")
plt.scatter(w0,1)
plt.tight_layout()
plt.title("10 tests in sonar")
plt.show()
c = np.mean(a)
print("准确率:")
print(c)

结果分析:
由于sonar数据集维数过多,而数据量相对较少,所以实现的准确率不到80%。由课上讨论的 c=2(k+1) 可知,当训练数据达到1200时,可以取得很好的效果。Sonar数据集只有208条记录。
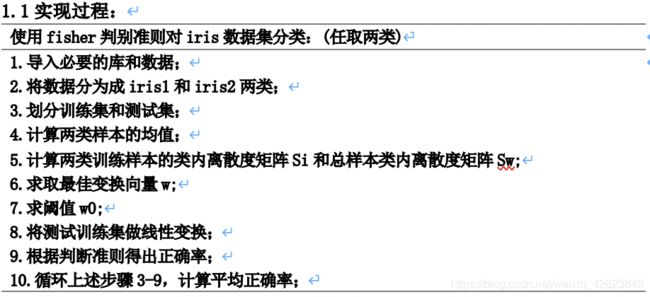
四、在iris数据集上验证算法
1、使用iris数据集的任意两类: 实现过程与sonar数据集的过程完全一致,只是在iris数据集上使用每50类数据中的随机30类作为训练数据,剩余为测试数据。