机器学习笔记之马尔可夫链蒙特卡洛方法(一)蒙特卡洛方法介绍
机器学习笔记之马尔可夫链蒙特卡洛方法——蒙特卡洛方法介绍
- 引言
-
- 回顾:近似推断
- 蒙特卡洛方法
- 采样方法介绍
-
- 基于概率分布的采样方法
- 拒绝采样
- 拒绝采样的缺陷与自适应拒绝采样
- 重要性采样
- 附:自适应拒绝采样代码
引言
从本节开始,将介绍马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,MCMC)
回顾:近似推断
推断(Inference)的本质是基于给定样本数据 X \mathcal X X的条件下,设定概率模型 P ( X ) P(\mathcal X) P(X)中包含隐变量 Z \mathcal Z Z,并给予 Z \mathcal Z Z一些先验信息 P ( Z ) P(\mathcal Z) P(Z),基于先验信息 P ( Z ) P(\mathcal Z) P(Z),通过贝叶斯定理求解出样本数据 X \mathcal X X条件下,隐变量 Z \mathcal Z Z的后验概率分布 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)。
P ( Z ∣ X ) = P ( X ∣ Z ) ⋅ P ( Z ) P ( X ) P(\mathcal Z \mid \mathcal X) = \frac{P(\mathcal X \mid \mathcal Z) \cdot P(\mathcal Z)}{P(\mathcal X)} P(Z∣X)=P(X)P(X∣Z)⋅P(Z)
基于真实情况的原因, P ( X ) P(\mathcal X) P(X)在求解过程中出现积分难的问题(例如隐变量 Z \mathcal Z Z的 维度过高):
P ( X ) = ∫ z 1 ∫ z 2 ⋯ ∫ z K P ( X , Z ) d z 1 , z 2 , ⋯ , z K P(\mathcal X) = \int_{z_1} \int_{z_2}\cdots \int_{z_{\mathcal K}} P(\mathcal X,\mathcal Z) dz_1,z_2,\cdots,z_{\mathcal K} P(X)=∫z1∫z2⋯∫zKP(X,Z)dz1,z2,⋯,zK
至此,我们很难通过贝叶斯定理求出 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)的精确解。因此,通过近似推断(Approximate Inference)来求解 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)的近似解。
一般情况下,近似推断主要分为两种方法:
- 确定性近似:其主要代表方法有变分推断(Variational Inference,VI)
- 随机近似:其主要代表方法有 马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,MCMC)。
蒙特卡洛方法
一开始需要注意的问题:蒙特卡洛方法 和 马尔可夫链蒙特卡洛方法 两者之间虽然存在关联,但本质上是两个概念,不要将其混为一谈。
关于蒙特卡洛方法(Monte Carlo Method),我们在蒙特卡洛方法求解强化学习任务中介绍过这种方法。这种方法最开始是为了求解积分问题。
示例1:在某二维平面中存在一个不规则区域,目标是求解不规则区域的面积。具体图像表示如下:
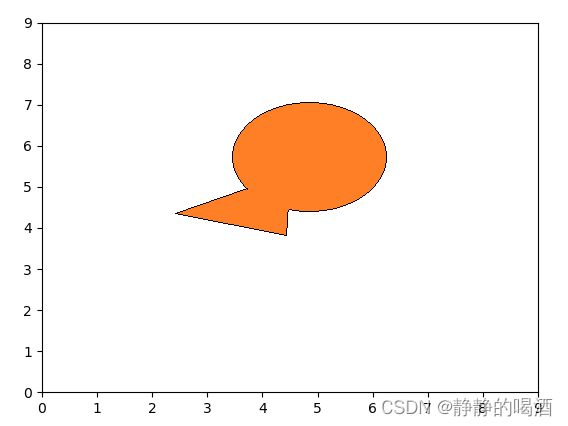
基于该图形的公式并不规范,因此很难通过积分方式求解图形面积。
现在有一种方法:
- 向上述 10 × 10 10 \times 10 10×10的平面区域内随机投掷质点,并记录质点落在图形区域内的次数;
- 通过计算 质点落在图形内的次数与总投掷次数的比值,估计图形区域占整个平面区域的比例;
- 平面区域面积乘以该比例,即可近似得到不规则区域的面积。
蒙特卡洛方法的核心是大数定律——在大量重复试验中所产生样本的算数平均值向数学期望收敛的规律。
基于上面描述,我们可以对蒙特卡洛方法有一个简单的认识:
- 可以使用蒙特卡洛方法求解期望;
- 求解期望的方式是基于采样的随机近似求解,而不是精确求解。
在推断过程中,通常使用 蒙特卡洛方法 近似求解后验分布 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)的相关期望信息:
E Z ∣ X [ f ( Z ) ] = ∫ Z P ( Z ∣ X ) ⋅ f ( Z ) d Z ( Z → C o n t i n u o u s ) = ∑ Z P ( Z ∣ X ) ⋅ f ( Z ) ( Z → D i s c r e t e ) \begin{aligned} \mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal Z)] & = \int_{\mathcal Z} P(\mathcal Z \mid \mathcal X) \cdot f(\mathcal Z) d\mathcal Z \quad (\mathcal Z \to Continuous) \\ & = \sum_{\mathcal Z} P(\mathcal Z \mid \mathcal X) \cdot f(\mathcal Z) \quad (\mathcal Z \to Discrete) \end{aligned} EZ∣X[f(Z)]=∫ZP(Z∣X)⋅f(Z)dZ(Z→Continuous)=Z∑P(Z∣X)⋅f(Z)(Z→Discrete)
上述积分求解的复杂程度取决于 隐变量 Z \mathcal Z Z或者模型参数 的维度,如果 Z \mathcal Z Z或者模型参数维度较高,极难求解;因此,通过蒙特卡洛方法通过采样方式近似求解期望:
- 假设从分布 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)中采样出 K \mathcal K K个样本点:
z ( 1 ) , z ( 2 ) , ⋯ , z ( K ) ∼ P ( Z ∣ X ) z^{(1)},z^{(2)},\cdots,z^{(\mathcal K)} \sim P(\mathcal Z \mid \mathcal X) z(1),z(2),⋯,z(K)∼P(Z∣X) - 那么期望结果 E Z ∣ X [ f ( Z ) ] \mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal Z)] EZ∣X[f(Z)]可近似表示为:
E Z ∣ X [ f ( Z ) ] ≈ 1 N ∑ i = 1 K f ( z ( i ) ) \mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal Z)] \approx \frac{1}{N} \sum_{i=1}^{\mathcal K} f(z^{(i)}) EZ∣X[f(Z)]≈N1i=1∑Kf(z(i))
至此,我们将求解 E Z ∣ X [ f ( Z ) ] \mathbb E_{\mathcal Z \mid \mathcal X} [f(\mathcal Z)] EZ∣X[f(Z)]转化为 如何从 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)中进行采样 的问题。
采样方法介绍
基于概率分布的采样方法
如果 P ( Z ∣ X ) P(\mathcal Z \mid \mathcal X) P(Z∣X)是一个较简单的概率分布,如一维高斯分布。其概率密度函数(Probability Density Function,PDF) P ( x ) P(x) P(x)表示如下:
P ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 P(x) = \frac{1}{\sqrt{2\pi} \sigma} e^{-\frac{(x - \mu)^2}{2\sigma^2}} P(x)=2πσ1e−2σ2(x−μ)2
其对应的累积分布函数(Cumulative Distribution Function,CDF) ϕ ( x ) \phi(x) ϕ(x)表示如下:
e r f ( x ) = 2 π ∫ 0 x e − η 2 d η ϕ ( x ) = 1 2 [ 1 + e r f ( x − μ 2 σ ) ] \begin{aligned} erf(x) & = \frac{2}{\sqrt{\pi}} \int_0^{x} e^{-\eta^2} d\eta \\ \phi(x) & = \frac{1}{2} \left[1 + erf\left(\frac{x - \mu}{\sqrt{2} \sigma}\right)\right] \end{aligned} erf(x)ϕ(x)=π2∫0xe−η2dη=21[1+erf(2σx−μ)]
累积分布函数与概率密度函数图像及代码表示如下:
import math
import matplotlib.pyplot as plt
import numpy as np
def pdf(mu,sigma,x):
return (1 / (math.sqrt(2 * math.pi) * sigma)) * math.exp(-1 * (((x - mu) ** 2) / (2 * (sigma ** 2))))
def func(x):
return math.exp(-1 *(x ** 2))
def erf(x):
if x > 0:
x_l = np.arange(0,x,0.01)
y_l = np.array([func(i) for i in x_l])
else:
x_l = np.arange(x,0,0.01)
y_l = np.array([-1 * func(i) for i in x_l])
res = (2 / (math.sqrt(math.pi))) * np.trapz(y_l,x_l)
return res
def cdf(mu,sigma,x):
input_x = (x - mu) / (sigma * (2 ** 0.5))
return 0.5 * (1 + erf(input_x))
if __name__ == '__main__':
mu_0,sigma_0 = 0,1
mu_1,sigma_1 = 0.8,1.5
x = list(np.linspace(-6,6,300))
y = [cdf(mu_0,sigma_0,i) for i in x]
y_pdf = [pdf(mu_0,sigma_0,i) for i in x]
y_1 = [cdf(mu_1,sigma_1,j) for j in x]
y1_pdf = [pdf(mu_1,sigma_1,j) for j in x]
plt.plot(x,y,c="tab:blue")
plt.plot(x,y_1,c="tab:orange")
plt.plot(x,y_pdf,c="tab:blue")
plt.plot(x,y1_pdf,c="tab:orange")
plt.show()
图像返回结果如下:

如果待采样分布可以知道它的概率密度函数,可以通过采样对期望进行求解。
- 从 ( 0 , 1 ) (0,1) (0,1)均匀分布中随机获取一个样本点;
u ( i ) ∼ U ( 0 , 1 ) ( i = 1 , 2 , ⋯ , N ) u^{(i)} \sim \mathcal U(0,1) \quad (i=1,2,\cdots,N) u(i)∼U(0,1)(i=1,2,⋯,N) - 将该样本点带入累积分布函数的反函数中,得到样本点对应在原始概率分布的样本点;
x ( i ) = ϕ − 1 [ u ( i ) ] ( i = 1 , 2 , ⋯ , N ) x^{(i)} = \phi^{-1}\left[u^{(i)}\right] \quad (i=1,2,\cdots,N) x(i)=ϕ−1[u(i)](i=1,2,⋯,N) - 重复执行上述操作,最终获取近似于原始概率分布的样本点集合,通过蒙特卡洛方法,可求解该集合的期望结果。
x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) E P ( x ) [ X ] ≈ 1 N ∑ i = 1 N x ( i ) x^{(1)},x^{(2)}, \cdots ,x^{(N)} \\ \mathbb E_{P(x)} [\mathcal X] \approx \frac{1}{N} \sum_{i=1}^N x^{(i)} x(1),x(2),⋯,x(N)EP(x)[X]≈N1i=1∑Nx(i)
这种基于概率分布的采样方法必然存在很多弊端:
- 针对高斯分布的概率密度函数,可以通过误差函数来 近似求解它的累积分布函数,但一些复杂的概率分布,它的累积分布函数是无法求解的;
- 就如上述高斯分布的累积分布函数,针对误差函数中的积分部分:
∫ 1 x e − η 2 d η \int_1^{x} e^{-\eta^2}d\eta ∫1xe−η2dη
该积分结果不是初等函数,无法求出该积分的解。至此可能出现: 知道累积分布函数的表示形式,但无法求解其反函数。
拒绝采样
拒绝采样(Rejection Sampling)的基本思想是通过对相对容易采样的分布进行采样,通过拒绝/接收该样本的方式近似待采样分布。
假设待采样分布为 P ( x ) \mathcal P(x) P(x),而该分布不容易直接进行采样,因此已知找到一个容易采样的候选分布(Proposal Distribution) Q ( x ) \mathcal Q(x) Q(x), P ( x ) \mathcal P(x) P(x)和 Q ( x ) \mathcal Q(x) Q(x)之间满足:
M ⋅ Q ( x ) ≥ P ( x ) \mathcal M \cdot \mathcal Q(x) \geq \mathcal P(x) M⋅Q(x)≥P(x)
M \mathcal M M本身是一个常数。使用该常数的原因在于:
无论什么形式的概率分布,其积分结果必然是1:
∫ x P ( x ) d x = ∫ x Q ( x ) d x = 1 \int_{x} \mathcal P(x) dx = \int_{x} \mathcal Q(x) dx = 1 ∫xP(x)dx=∫xQ(x)dx=1
因此, Q ( x ) \mathcal Q(x) Q(x)的概率密度函数所包围的区域 必然无法将 P ( x ) \mathcal P(x) P(x)的概率密度函数所包围的区域完全覆盖。
但如果乘以一个常数 M \mathcal M M,就可以对包围的区域进行放缩,直至 M ⋅ Q ( x ) \mathcal M \cdot\mathcal Q(x) M⋅Q(x)围成的区域覆盖 P ( x ) \mathcal P(x) P(x)围成的区域。即任意样本点 x x x,都有 M ⋅ Q ( x ) ≥ P ( x ) \mathcal M \cdot \mathcal Q(x) \geq \mathcal P(x) M⋅Q(x)≥P(x)。
其采样步骤表示如下:
- 从候选分布 Q ( x ) \mathcal Q(x) Q(x)中采出样本 x ( i ) x^{(i)} x(i);
- 求解 x ( i ) x^{(i)} x(i)对应 Q ( x ) \mathcal Q(x) Q(x)的概率结果 Q ( x ( i ) ) \mathcal Q(x^{(i)}) Q(x(i));
- 从均匀分布 U [ 0 , M ⋅ Q ( x ( i ) ) ] \mathcal U[0,\mathcal M\cdot \mathcal Q(x^{(i)})] U[0,M⋅Q(x(i))]中随机产生一个系数结果 u u u;
- 计算 u u u和 P ( x ( i ) ) M ⋅ Q ( x ( i ) ) \frac{\mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} M⋅Q(x(i))P(x(i))之间大小关系:
- 如果 u < P ( x ( i ) ) M ⋅ Q ( x ( i ) ) u < \frac{\mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} u<M⋅Q(x(i))P(x(i)),则接受此次采样;
- 如果 u ≥ P ( x ( i ) ) M ⋅ Q ( x ( i ) ) u \geq \frac{\mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} u≥M⋅Q(x(i))P(x(i)),则拒绝此次采样;
- 重复上述步骤,直到采集足够的样本数量。
需要解释一下均匀分布 U [ 0 , M ⋅ Q ( x ( i ) ) ] \mathcal U[0,\mathcal M \cdot \mathcal Q(x^{(i)})] U[0,M⋅Q(x(i))]的作用:
- 从均匀分布 U ( 0 , M ⋅ Q ( x ( i ) ) ) \mathcal U(0,\mathcal M \cdot \mathcal Q(x^{(i)})) U(0,M⋅Q(x(i)))采集的样本 u u u自身没有任何实际意义,该结果只作为评价 P ( x ( i ) ) M ⋅ Q ( x ( i ) ) \frac{\mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} M⋅Q(x(i))P(x(i)) 的一个工具。
- 而计算 u u u和 P ( x ( i ) ) M ⋅ Q ( x ( i ) ) \frac{\mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} M⋅Q(x(i))P(x(i))的大小关系就是模拟 P ( x ( i ) ) M ⋅ Q ( x ( i ) ) \frac{\mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} M⋅Q(x(i))P(x(i))和 M ⋅ Q ( x ( i ) ) − P ( x ( i ) ) M ⋅ Q ( x ( i ) ) \frac{\mathcal M \cdot \mathcal Q(x^{(i)}) - \mathcal P(x^{(i)})}{\mathcal M \cdot \mathcal Q(x^{(i)})} M⋅Q(x(i))M⋅Q(x(i))−P(x(i))之间的大小关系。
- 从而通过各位置接受样本点的数量对 P ( x ) \mathcal P(x) P(x)的情况进行估计,最终使用蒙特卡洛方法可以近似求解该分布的期望。
拒绝采样的缺陷与自适应拒绝采样
拒绝采样的缺陷也是比较明显的:如果想要使用拒绝采样得到较准确的分布 P ( x ) \mathcal P(x) P(x),那么必然要选择好候选分布 Q ( x ) \mathcal Q(x) Q(x)和超参数 M \mathcal M M。
如果我们选择的 M ⋅ Q ( x ) \mathcal M \cdot \mathcal Q(x) M⋅Q(x)总是使得:对于大多数 x ( i ) x^{(i)} x(i), M ⋅ Q ( x ) \mathcal M \cdot \mathcal Q(x) M⋅Q(x)总是和 P ( x ) \mathcal P(x) P(x)差距较大,即采样后被拒绝的次数很多。这种采样方式即便是采样通过的样本其准确率也同样很差。
如果能够找到一个和 P ( x ) \mathcal P(x) P(x)非常接近的候选分布,那么采样被拒绝的概率将极大的降低。
如果 P ( x ) \mathcal P(x) P(x)是一个 log C o n c a v e \log Concave logConcave形式的函数,可以采用自适应拒绝采样(Adaptive Rejection Sampling)方法进行采样。
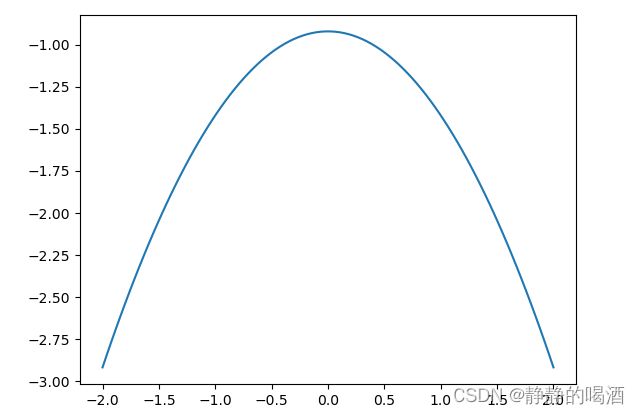
- 依然使用高斯分布(Gaussian Distribution)进行示例。设置均值 μ = 0 \mu=0 μ=0,方差 σ 2 = 1 \sigma^2 = 1 σ2=1的高斯分布对应 log \log log结果图像表示如下:
文章最后附完整代码~
- 在上述凸函数中任意选取几个点(3个点示例),并且过该点在凸函数上做切线,并求出该直线的判别式。最后选在凸函数上的切线表示如下:

- 通过图像发现,这三条直线已经和凸函数相切在选择的三个点上。至此,将 log \log log去掉,将凸函数与对应三条切线还原为原始状态:
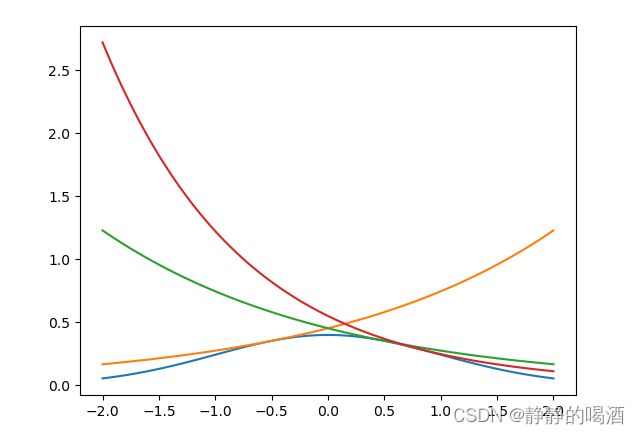
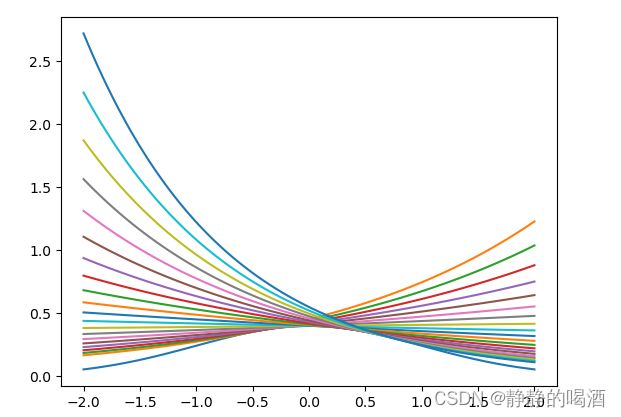
观察上图,蓝色线是高斯分布(这里是待求解的分布),红色、橙色、绿色线是上述三条切线还原后的结果。明显可以发现:三条线所围成的区域已经和待求解分布围成的区域已经非常接近了(图像下方部分)。 - 如果步骤2中选取的点足够多,围成的部分就越近待求解分布的积分区域:(对比一下选取20个点的具体效果):
重要性采样
相比于上述基于概率分布采样,拒绝采样等,重要性采样(Importance Sampling)并不是针对概率分布进行采样,而是针对概率分布的期望进行采样:
- 假设当前存在概率分布 P ( x ) \mathcal P(x) P(x), P ( x ) \mathcal P(x) P(x)分布下某函数 f ( x ) f(x) f(x)的期望结果表示如下:
E P ( x ) [ f ( x ) ] = ∫ x P ( x ) ⋅ f ( x ) d x \mathbb E_{\mathcal P(x)} [f(x)] = \int_{x} \mathcal P(x)\cdot f(x) dx EP(x)[f(x)]=∫xP(x)⋅f(x)dx - 由于无法直接对 P ( x ) \mathcal P(x) P(x)进行采样,因此引入一个候选分布 Q ( x ) \mathcal Q(x) Q(x),有:
E P ( x ) [ f ( x ) ] = ∫ x [ P ( x ) Q ( x ) ⋅ f ( x ) ] Q ( x ) d x \begin{aligned} \mathbb E_{\mathcal P(x)}[f(x)] & = \int_{x} \left[\frac{\mathcal P(x)}{\mathcal Q(x)}\cdot f(x)\right] \mathcal Q(x) dx \end{aligned} EP(x)[f(x)]=∫x[Q(x)P(x)⋅f(x)]Q(x)dx - 通过蒙特卡洛方法, E P ( x ) [ f ( x ) ] \mathbb E_{\mathcal P(x)}[f(x)] EP(x)[f(x)]结果表达如下:
E P ( x ) [ f ( x ) ] ≈ 1 N ∑ i = 1 N [ f ( x ( i ) ) ⋅ P ( x ( i ) ) Q ( x ( i ) ) ] \mathbb E_{\mathcal P(x)}[f(x)] \approx \frac{1}{N} \sum_{i=1}^N \left[f(x^{(i)}) \cdot \frac{\mathcal P(x^{(i)})}{\mathcal Q(x^{(i)})}\right] EP(x)[f(x)]≈N1i=1∑N[f(x(i))⋅Q(x(i))P(x(i))]
并且称 P ( x ( i ) ) Q ( x ( i ) ) \frac{\mathcal P(x^{(i)})}{\mathcal Q(x^{(i)})} Q(x(i))P(x(i))为重要性权重(Importance Weight)。需要注意的是,在步骤2中从 Q ( x ) \mathcal Q(x) Q(x)中进行采样。即:
x ( i ) ∼ Q ( x ) ( i = 1 , 2 , ⋯ , N ) x^{(i)} \sim \mathcal Q(x) \quad (i=1,2,\cdots,N) x(i)∼Q(x)(i=1,2,⋯,N)
因此,重要性采样的思想在于:在知晓重要性权重的条件下,通过对 Q ( x ) \mathcal Q(x) Q(x)进行采样,从而近似得到 P ( x ) \mathcal P(x) P(x)的期望信息。
实际上,重要性采样的弊端和拒绝采样类似,引入的候选分布 Q ( x ) \mathcal Q(x) Q(x)和待求解分布 P ( x ) \mathcal P(x) P(x)之间存在较高的相似性。即:
P ( x ) Q ( x ) → 1 \frac{\mathcal P(x)}{\mathcal Q(x)} \to 1 Q(x)P(x)→1
如果引入的 Q ( x ) \mathcal Q(x) Q(x)对上述条件偏离程度较高,采样的效率同样是非常低下的。
下一节将介绍马尔可夫链(Markov Chain)的相关性质。
附:自适应拒绝采样代码
import math
import numpy as np
import matplotlib.pyplot as plt
def pdf(mu,sigma,x):
return (1 / (math.sqrt(2 * math.pi) * sigma)) * math.exp(-1 * (((x - mu) ** 2) / (2 * (sigma ** 2))))
def log_pdf(mu,sigma,x):
return math.log(pdf(mu,sigma,x))
def d_log_pdf(mu,sigma,x):
return -1 * (1 / (sigma ** 2)) * (x - mu)
def get_point_tangent(mu,sigma,x_sample,x):
y = log_pdf(mu,sigma,x_sample)
k = d_log_pdf(mu,sigma,x_sample)
b = y - (k * x_sample)
return k * x + b,k,b
def get_primitive(x_sample,x):
_,k,b = get_point_tangent(0,1,x_sample,x)
return np.exp(k * x + b)
if __name__ == '__main__':
x = list(np.linspace(-2,2,100))
y = [pdf(0,1,i) for i in x]
log_y = [log_pdf(0,1,i) for i in x]
x_sample_l = list(np.linspace(-0.5,0.8,20))
# plt.plot(x,log_y)
plt.plot(x,y)
for x_sample in x_sample_l:
tangent_y = []
# for i in x:
# out,_,_ = get_point_tangent(0,1,x_sample,i)
# tangent_y.append(out)
# plt.plot(x,tangent_y)
y_primitive = [get_primitive(x_sample,i) for i in x]
plt.plot(x,y_primitive)
plt.show()
相关参考:
机器学习-白班推导系列-蒙特卡洛方法1(Monte Carlo Method)-基础采样方法