机器学习在癌症数据集上的应用实践
在本文中,我们一起学习如何将机器学习应用于癌症数据集。

1.摘要
支持向量机(SVM)是机器学习中最流行的有监督学习算法之一。许多研究人员都通过实践证明了该算法的优异性。
SVM既可以应用于回归问题,也可以应用于分类问题,本文以癌症数据集为例,描述了SVM在分类问题上的应用。
2.简介
SVM算法的应用十分广泛,目前已经应用到医学研究,面部识别,垃圾邮件分类,文档分类,手写识别等方面。在医学研究领域,SVM已被从业人员应用于:
- 白细胞分类
- 癌症预测
- 基因分类
部分研究人员声称,SVM在这些研究方面比逻辑回归、决策树甚至神经网络的预测效果更好。
3.SVM的线性应用
SVM算法在线性应用中非常流行的主要原因是,在先验知识较少的情况下,其在统计问题上的泛化性能依旧很好,并且输入空间(特征)维数很高时也是如此。
4.SVM的非线性应用
在解决非线性问题时,SVM通过核映射方法将其转换到高维度空间,从而可以轻松地定义最优超平面。SVM通过最优超平面来分离数据,使用核映射方法可以提高数据分类的能力。
如果超平面离数据点比较近,则我们认为他不是一个良好分类超平面,因为他对噪声数据比较敏感,SVM的目的是找到最大边距超平面(maximum margin hyperplane,MMH)。
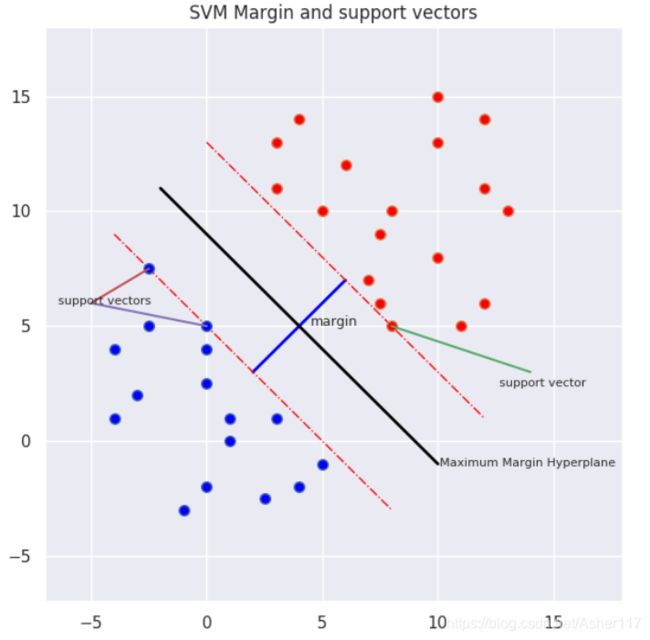
SVM算法试图找到两个类别数据中最接近的那些点,这些点称为支持向量。然后,SVM寻找支持向量和分割超平面之间的最佳间隔(margin)。 SVM算法力图使margin最大化, 此时,最优超平面是具有最大间隔的超平面。
5.几种SVM核函数
核函数的主要思想是对训练数据进行变换,以提高其与线性可分离数据集的相似度。 对数据的变换通过增加数据的维数来实现数据集的可分离。几种常见的核函数,每种都有自己的优势。
- 线性核
- 多项式核
- RBF-径向基函数核
- 高斯核
- 双曲正切核
我将在以后的文章中介绍这些核函数和典型应用场景。
我通常首先使用线性核,它的运行速度快,并且效果也不错。然后,我会运行RBF核函数以比较结果。在下面的示例中,线性核提供了更好的结果。
6.应用案例–癌症数据集
Python的sklearn扩展包中包含了“威斯康星州乳腺癌”数据集,其中详细记录了威斯康星大学附属医院的乳腺癌测量数据。数据集包括569行和31个特征,特征如下:
这段代码Cancer = datasets.load_breast_cancer()返回一个Bunch对象,我将其转换为dataframe数据类型。可以使用print(df.shape)检查数据,在输出中,可以看到(569,31),这意味着数据有569行和31列。使用print(df.head())列出数据集的前五行。
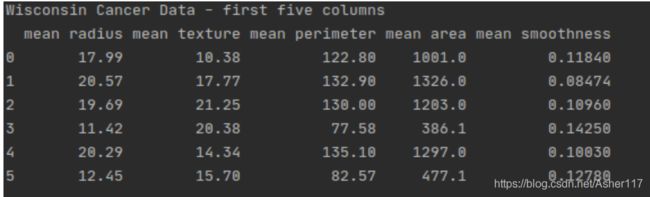
癌症数据集来自医务人员记录的肿瘤图像,并标记了恶性或良性。 数据集的特征(列)如下所示:
[‘mean radius’ ‘mean texture’ ‘mean perimeter’ ‘mean area’
‘mean smoothness’ ‘mean compactness’ ‘mean concavity’
‘mean concave points’ ‘mean symmetry’ ‘mean fractal dimension’
‘radius error’ ‘texture error’ ‘perimeter error’ ‘area error’
‘smoothness error’ ‘compactness error’ ‘concavity error’
‘concave points error’ ‘symmetry error’ ‘fractal dimension error’
‘worst radius’ ‘worst texture’ ‘worst perimeter’ ‘worst area’
‘worst smoothness’ ‘worst compactness’ ‘worst concavity’
‘worst concave points’ ‘worst symmetry’ ‘worst fractal dimension’]
这些特征分别表示:
[‘平均半径’‘平均纹理’‘平均周长’‘平均面积’
‘平均光滑度’‘平均紧密度’‘平均凹度’
‘平均凹点’,‘平均对称性’,‘平均分形维数’
‘半径误差’‘纹理误差’‘周边误差’‘区域误差’
‘光滑度错误’‘紧密度错误’‘凹度错误’
‘凹点误差’‘对称误差’‘分维误差’
‘最差的半径’,‘最差的纹理’,‘最差的周长’,‘最差的区域’
‘最差的光滑度’‘最差的紧密度’‘最差的凹度’
‘最差的凹点’,‘最差的对称性’,‘最坏的分形维数’]
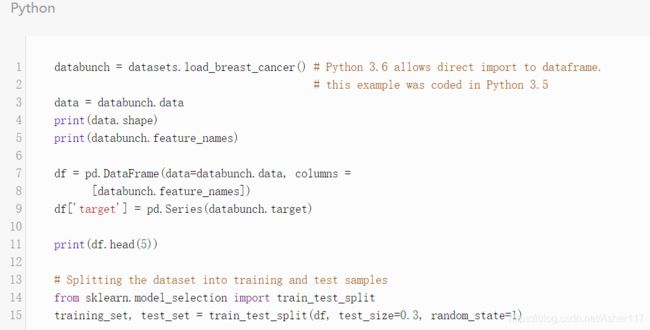
scikit-learn库的model selection部分提供了train_test_split()方法,该方法可以将数据划分为训练数据和测试数据。
7.训练算法模型
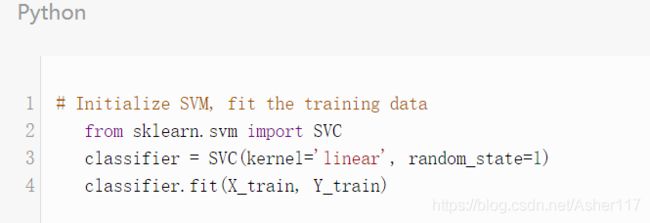
现在我们将数据集分为训练集和测试集了,我们准备训练模型。scikit-learn包含了SVM库,该库包含针对不同SVM算法的内置方法。第一个参数是核函数类型,此处选择了线性核函数。

调用SVM类的fit()方法训练数据。
评估算法的质量
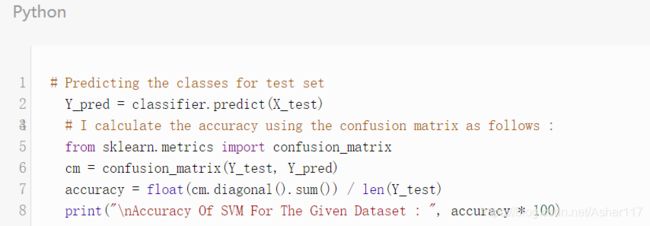
这里使用混淆矩阵评估预测的准确性,混淆矩阵能得到算法预测的错误分类和正确分类。
在这里,可以看到使用线性核函数得到的准确率为94.7%,算法达到了很好的预测效果。
8.总结
SVM算法的优缺点
SVM的优点
研究者报告显示,SVM的性能优于许多较早建立的机器学习算法,例如神经网络和决策树等。
SVM算法预测的准确性通常取决于选择的核函数。许多研究人员发现,径向基函数(RBF)核在许多问题都具有健壮性。
SVM的缺点
当特征数量大于每个类别训练样本数据时,SVM的性能可能会很差。
9.参考链接
https://scikit-learn.org/0.23/modules/generated/sklearn.datasets.load_breast_cancer.html
O. L. Mangasarian and W. H. Wolberg: “Cancer diagnosis via linear programming”, SIAM News, Volume 23, Number 5, September 1990, pp 1 & 18.
William H. Wolberg and O.L. Mangasarian: “Multisurface method of pattern separation for medical diagnosis applied to breast cytology”, Proceedings of the National Academy of Sciences, U.S.A., Volume 87, December 1990, pp 9193-9196.
本文翻译自dzone,原文链接
码字不易,喜欢请点赞!!!
我们共同学习,共同进步!!!