如何使上下文信息更有用? 关于上下文感知的神经对话模型的实证研究
论文标题:How to Make Context More Useful?An Empirical Study on Context-Aware Neural Conversational Models
论文地址:http://www.aclweb.org/anthology/P/P17/P17-2036.pdf
摘要
生成式会话系统在自然语言处理(NLP)领域中日益受到关注。近来,研究人员注意到对话处理中上下文信息的重要性,并建立了各种模型来利用上下文。 然而,没有系统的比较来分析如何有效地使用上下文。在本文中,我们进行实证研究来比较各种模型,并研究对话系统中上下文信息对结果的影响。同时还提出了一种变体方法,通过上下文查询相关性明显地加权上下文向量,其效果超过了其他基准方法。
引言
最近,人机对话由于其巨大的潜力和商业价值受到了越来越多的关注。研究人员提出了自动对话系统的检索方法(Ji et al.,2014; Yan et al., 2016)和生成方法(Ritter等,2011; Shang等,2015)。随着深度学习技术的成功,神经网络已经表现出强大的学习人类对话模式的能力;给定用户发出的话语作为输入查询q,神经网络可以产生回复r,其通常以序列到序列(Seq2Seq)方式完成(Shang等人,2015)。
在文献中,对话系统有两个典型的研究设置:单轮和多轮。单轮谈话是最简单的设置,即模型在产生r时仅需考虑q(Shangetal., 2015; Mou et al., 2016)。然而,大多数现实世界的对话都是包括多轮的情况。以前的话语(在本文中称为上下文)也可以提供关于对话状态的有用信息,并且是相关多轮对话的关键。
现有研究已经意识到上下文的重要性,并提出了几种情境感知对话系统。例如,Yan et al.,(2016)直接连接上下文话语和当前查询;其他人使用分层模型,首先捕捉个人话语的意义,然后将其整合为篇章(Serban等,2016)。目前有多种方式来组合上下文和当前的查询,例如池化或连接(Sordoni等人,2015)。不幸的是,以前的文献缺乏对上述方法的系统比较。
在本文中,我们对Seq2Seq类对话系统中的上下文建模进行了实证研究。我们重点研究了以下问题:
•RQ1 我们如何更好地利用上下文信息?
研究表明,层次模型通常比非分层模型更好。我们还提出了上下文集成的一个变体,通过其相关性度量明显地加权上下文向量,超过简单的向量池化或连接。
•RQ2 上下文对神经对话系统的影响是什么?
我们发现上下文信息对于神经会话模型是有用的。它能产生更长、更多的信息和多样化的回复。
总之,本文的贡献有两个方面:(1)我们对神经会话模型中上下文建模进行了系统研究。(2)我们进一步提出了显式上下文加权方法,效果超过其他基准方法。
模型
非层次模型
为了在当前查询之前对一些话语进行建模,一些研究将这些句子直接连接在一起,并使用单个模型来捕获上下文和查询的含义(Yan et al.,2016; Sordoni et al., 2015)。在本文中,它们被称为非层次模型。这种方法也适用于其他NLP任务,例如文献级情感分析(Xu et al.,2016)和机器理解(Wang andJiang,2017)。
遵循经典的编码解码(encode-decoder)框架,我们使用Seq2Seq网络,其在编码期间通过循环神经网络(RNN)将查询和上下文转换成固定长度的向量venc; 那么在解码阶段,它使用另一个RNN以逐个字的方式产生一个应答r。(见图1a)
在我们的研究中,我们采用门限递归单元的RNN(Cho et al.,2014,GRUs),可以缓解普通RNN的长时间传播问题。解码时,我们应用大小为5的定向搜索。
层次模型
上下文建模的一个更复杂的方法是使用两步策略构建层次模型:一个话语级模型捕获每个单独句子的含义,然后一个话语间模型集成上下文和查询信息(图1b)。
研究人员尝试了在话语间建模中组合信息的不同方法; 本文评估了几种主要的方法。
Sum pooling。 Sum池化(表示为Sum)通过对每个维度中的值求和来集成候选集上的信息(图2a)。给定上下文向量vc1,...,vcn和查询向量vq,编码的向量venc是

Sordoni等人使用Sum pooling (2015),其中简单地添加了上下文和查询的词袋(BoW)特征。在我们的实验中,sumpooling对由上下文和查询语句建模的句子级RNN提取的特征进行操作,因为现代神经网络比BoW特征保留更多的信息。
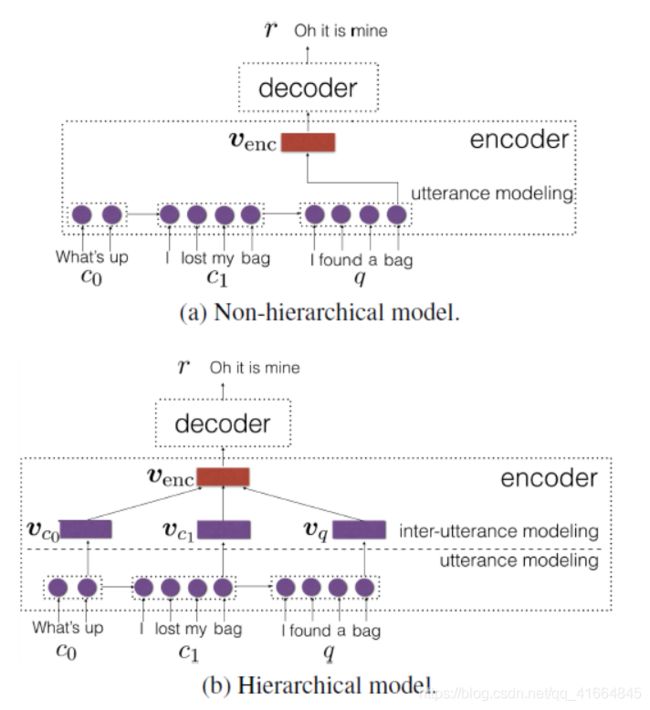
图1 Seq2Seq神经网络基于上下文C = {c1,...,cn}和当前查询q的(a)非分层或(b)分层模型生成回复r。
连接。 连接(Concat)是Sordoni等人(2015)使用的另一种方法。该方法将每个话语级向量vci和vq连接为长向量,即venc = [vc0; ...; vcn; vq]。(见图2b)
与sum pooling相比较,向量连接可以区分上下文和查询的不同角色,因为该操作分别保留输入。然而,一个潜在的缺点是,连接只适用于固定长度的上下文。
顺序整合。 Yao等人(2015)和Serban等人(2015)提出了层次对话系统,其中一个话语间RNN建立在话语级RNN的特征(最后的隐藏状态)上。训练是通过端到端梯度传播实现的,过程如图2c所示。
使用RNN以顺序方式集成上下文和查询向量可实现复杂的信息交互。基于RNN的隐藏状态,Sum和Concat也可以应用于获得编码向量venc。

图2 层次模型中的话语间建模。vci和vq是话语级向量,hci和hq是话语级隐藏状态,αci和αq是明确的权重,而venc是编码器的输出。
然而,我们发现他们的性能比仅使用最后一个隐藏状态(表示为Seq)更差。一个合理的原因可能是句间RNN不长,RNN可以很好地保存这些信息。因此,我们的实验采用了这种变体,如图2c所示。
3 通过上下文查询相关性显式加权
在会话中,上下文内容和语义可能会有所不同:
与查询相关的上下文话语可能是有用的,而不相关的内容可能会带来更多的噪点。按照这种情况,我们提出了一种变体,通过上下文查询相关性的attention分数显式加权上下文向量。
首先,我们用余弦值来计算上下文和查询之间的相似度:

在下面条件下:

也就是说,句子向量是单词向量的总和。
遵循attention机制(Bahdanau et al., 2014),我们希望通过softmax函数对这些相似度进行归一化,并获得attention概率:

其中sq与sci相同的方式计算,并且始终和为1,其为两个相同向量的余弦值。如果上下文不太相关,我们应该主要关注查询本身,但如果上下文是相关的,我们应该更加均匀地集中关注在上下文和查询之间。
换句话说,我们的显式加权方法可以被看作是启发式attention。类似于2.2节,我们通过池化和连接来聚合加权上下文和查询向量,从而产生以下两种变体。
WSeq(sum),其中加权向量相加在一起
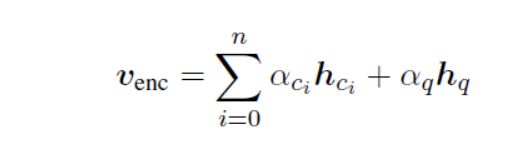
WSeq(concat),其中加权向量被连接

请注意,显式加权方法也可以应用于句子向量(无句子间RNN)。我们分别用WSum和WConcat表示变体;细节不再重复。它们在第3.2节中进行比较。
实验
设置
我们对在线免费聊天平台“百度贴吧”中爬行的中文数据进行了全部实验。为了方便对上下文效果的研究,我们在Sordoni等人(2015)和Serban等人(2015)之后建立了一个多转对话语料库。数据样本包含三个话语,是一个三元组<上下文, 查询, 回复>。总共有50万个训练样本,2000个验证样本,4000个测试样本。神经网络的超参数主要来自Shang etal.,(2015)和Song etal.,(2016):向量表示620d和隐藏状态1000d;我们使用AdaDelta进行优化。

表1 不同模型的性能
结果和分析
我们通过BLEU分数评估模型表现。由于本文比较了各种模型,我们聘请工人手动标注其满意度是无法承受的。BLEU得分虽然对于开放领域的对话系统来说是不完美的,但与人类的满意度有显著的相关性(Liu et al.,2016; Tao et al., 2017)。我们在表1中介绍了第2部分介绍的模型的整体性能,并回答了我们的研究问题如下。
RQ1:我们如何更好地利用上下文信息?
我们首先观察到上下文感知方法通常优于上下文无关的方法。这意味着上下文在开放域聊天风格的对话系统中确实很有用。结果与以前的研究一致(Sordoni等., 2015;Serban等., 2015)。
在上下文感知神经对话模型中,我们有以下发现。
层次结构优于非层次结构
比较非层次结构和层次结构,我们发现(大多数)分层模型大大优于非层次结构。结果表明,对话系统与其他NLP应用程序不同,例如理解(Wang和Jiang,2017),其中采用非曾层次递归神经网络来更好地整合不同句子之间的信息。一个合理的解释,如Meng等人(2017)的话语句子不一定是由同一个发言者发出的,文献明确证明了对话系统中层次化RNN的有效性。
分别保持不同话语的作用很重要
如第2节所述,连接操作(Concat)区分不同话语的角色,而sumpooling Sum以均匀的方式聚合信息。我们看到前者在句子向量和句间RNN水平方面表现优于后者,表明sum pooling并不适合对待对话上下文。我们的猜想是,sumpooling在不太重要的上下文信息上表示查询信息。因此,保持分开通常会有所帮助。
上下文查询相关性分数有益于会话系统
我们的显式加权方法通过上下文查询相关性计算attention概率。在所有变体(Sum, Concat和Seq)中,显式加权大大提高了性能(除了Seq的BLEU-1之外)。结果表明,上下文查询的相关性是有用的,因为它强调了相关上下文信息,并削弱了不相关的上下文信息。

表2 对上下文无关和上下文感知(WSeq,concat)方法的回复的长度、熵和多样性。
RQ2:上下文对神经对话系统的影响是什么?
我们现在好奇上下文信息如何影响神经会话系统。在表2中,我们提出三个辅助度量,即句子长度、熵和多样性。前两者在Serban等人(2016)和Mou等人(2016)中使用,而后者则在Zhang andHurley (2008)中使用。
如图所示,与上下文无关的模型相比,内容感知对话模型倾向于产生更长、更有意义和多样化的回复,因为它们也提高了BLEU分数。
这显示了神经序列生成的一个有趣的现象:编码-解码框架需要足够的源信息来有意义地生成目标;它不是从不太有意义的输入中获取有意义的内容。我们以前的工作也有类似的现象(Mou et al.,2016);我们发现,如果一个相同的网络从给定(有意义的)关键字开始,则会产生更有意义的句子。这些结果也部分解释了为什么seq2seq神经网络趋向于在开放领域谈话中产生短小和普遍相关的回复,尽管它在机器翻译、抽象概括等方面取得了成功。
4 结论
在这项工作中,我们分析了上下文信息对生成式对话模式的影响。我们对现有方法和我们新提出的方法进行了系统比较,通过上下文查询相关性来显式加权上下文向量。
我们表明层次RNN通常优于非层次RNN,显式加权上下文信息可以加强相关的上下文信息,并减弱不太相关的上下文信息。
我们的实验也揭示了一个有趣的现象:通过上下文信息,神经网络往往会产生更长、更有意义和更多样化的回复,从而揭示了神经序列生成的前景。