HRNet人体关键点检测
Deep High-Resolution Representation Learning for Human Pose Estimation (CVPR 2019 oral)
文章地址:https://arxiv.org/abs/1902.09212
源码:GitHub - leoxiaobin/deep-high-resolution-net.pytorch: The project is an official implementation of our CVPR2019 paper "Deep High-Resolution Representation Learning for Human Pose Estimation"
1、 引言
HRNet(High-Resolution Net)针对2D人体姿态估计(Human Pose Estimation或Keypoint Detection)任务提出的,且该网络主要是针对单一个体的姿态评估。即网络输入只能是单个人。人体姿态估计主要的应用场景为:人体行为动作识别、人机交互、动画制作(比如根据人体的关键点信息生成对应卡通人物的动作)等等。

对于Human Pose Estimation任务,现在基于深度学习的方法主要有两种:
1)基于regressing的方式,即直接预测每个关键点的位置坐标。
2)基于heatmap的方式,即针对每个关键点预测一张热力图(预测出现在每个位置上的分数)。
注:当前检测效果最好的一些方法基本都是基于heatmap的,所以HRNet也是采用基于heatmap的方式。
2、HRNet网络结构
现在存在的大多数方法,都是提取图象的低分辨率特征,然后恢复成高分辨率特征进行预测。我们提出的方法,在整个网络中,主要以高分辨率为主。论文的核心思想就是不断地去融合不同尺度上的信息,也就是论文中所说的Exchange Blocks。
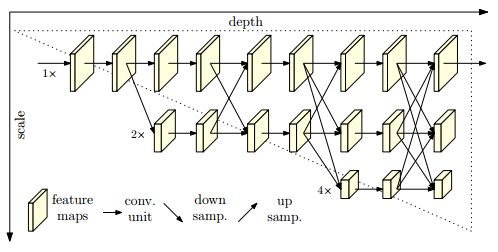
HRNet的架构。它由并行的高分辨率到低分辨率的子网组成,在多分辨率子网之间进行重复的信息交换(多尺度融合)。水平方向和垂直方向分别对应网络的深度和特征图的尺度。
3、相关工作
传统的单人位姿估计方法大多采用概率图形模型或图形结构模型,最近通过深度学习,自动提取特征方式,相对于传统的算法,提升是比较明显的。现在深度学习提出的解决方式主要分为两类,分别为关键点位置回归,以及估算关键点热图。
大多数网络都包含了一个主干网络,类似于分类网络一样,其降低了分辨率。以及另外一个主干网络,其产生与其输入具有相同分辨率的特征图。然后利用该特征去回归关键点或者估算热图。其主要是采用了分辨率 high-to-low 以及 low-to-high 的结构。可能增加多尺度融合和中间(深层)监督。
4、实现方法
人类姿态估算,关键点检测,输入为一张行人图像,输出为与关键点个数相同的特征图数量,由每个特征图预测对应的关键点。首先使用2个strided的卷积,减少输入图像的分辨率,获得初步特征图,然后把该特征图作为一个主体网络的输入,该主体网络的输出和输入的分辨率一样,其会其估算关键点的heatmaps。
4.1、连续多分辨率子网络
有的位姿估计网络是通过串联高分辨率子网来建立的,每个子网形成一个stage,由一系列卷积组成,并且在相邻的子网之间有一个下样本层来将分辨率减半。
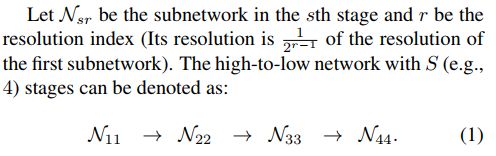
4.2、并行多分辨率子网
首先我们在第一个 stage 开始了一个高分辨率的网络分支,然后逐步增加高分辨率到低分辨率的子网路,形成一个新的 stages,并将多分辨率子网并行连接。因此,后一阶段并行子网的分辨率由前一阶段的分辨率和一个更低的分辨率组成,一个包含4个并行子网络的网络结构示例如下:
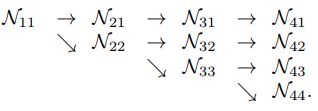
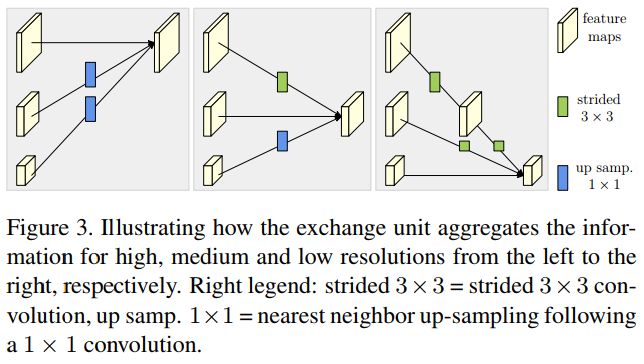
4.3、重复的多尺度融合
我们引入了平行网络信息交换单元,比如每个子网络重复接受来自其他平行子网络的信息。下面是一个例子,展示了信息交换的方案。我们将第三 stage 分为几个(例如3个)交换模块,每个模块由3个并行卷积单元和一个跨并行单元的交换单元组成,其结构如下:
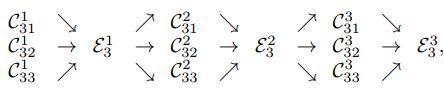
卷积实现如下形式:
5、损失设计
均方差。一些细节,在真值周围做高斯运算得到点的扩展,防止仅有一个关键点时训练难收敛的问题。
6、评价指标
数据集使用coco集。标准的量化评估是基于 Object Keypoint Similarity (OKS),计算公式如下:
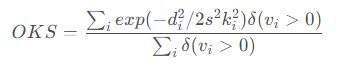
其中,di是预测值与真实值的欧式距离,vi表示真值是否可见标志。s是目标缩放的比例,ki是一个控制衰减的每个关键点长度。
Training: 按照等比例,将人体检测结果扩展到高度:宽度 = 4 :3,然后剪裁到固定尺寸256×192或者384×288。
使用了 Adam 优化器,基础学习率设置为1e-3,在迭代170个 epochs 以及 200 个 epoch 进行10倍的学习率衰减。训练过程在210个epochs 内结束。
Testing: 使用2个阶段的方式 - 使用person检测器检测person实例,然后预测检测关键点。对于验证集和测试开发集,我们使SimpleBaseline2提供的person检测器。计算了原图,和水平反转图估算出来 heatmap 的平均值。每个关键点的位置,都是通过调整最高热值来进行判断的。
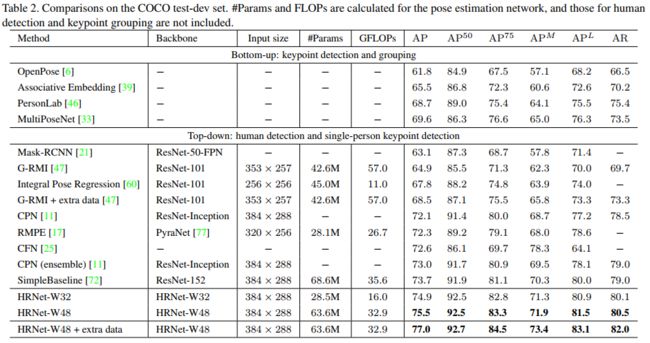
结果:
论文中更多的是思想描述, 更多细节可查看代码获得,下面是模型结构: