字符编码简介
目录
一、ascii编码
二、扩展ascii编码
三、多字节编码(multi bytes)
四、宽字符编码(wide char)
五、unicode编码
六、utf-8编码
七、结语
大家好,我是略游。本文的目的是讲清楚,字符编码的今生来世。看完后你会对字符编码的规则有一个宏观印象。
一、ascii编码
字符(character)是计算机与人交互的媒介,人虽然可以看懂二进制串,但文字是更加直观的。所以需要用数字来表示字符,字符与数字的对应关系就叫编码(coding)。
由于计算机发源于美国,一开始不需要显示其他语言的文字,所以就挑选了常用的128个字符,形成了ASCII码表。其中有一些特殊的字符是不能显示的,例如换行、空、水平制表符等。如下图所示:
 ascii码表
ascii码表
上图是我打印的ascii编码,其中索引32的字符为空格,之前的称为控制字符。但是我们使用isprint函数来判断一个字符是否“可打印的”,就会发现水平制表符(\t)其实是返回的非0。
前辈程序员使用1个字节表示字符,8位二进制一共可表示256个不同的值,但这里只用到了前面的128个位置。在C++里面char是带有符号的,也就是可以是负数,范围为[-128, 127],这样看起来只用[0, 127] ,似乎有点道理(才怪)。
二、扩展ascii编码
128个值当然很快就会不够用了,IBM于是制订了扩展ascii编码,也就是用上另外的128个值。当然这并非标准,到现在已经很少有人使用了,或许在嵌入式单片机等内存紧张的地方还有人使用。
三、多字节编码(multi bytes)
如果要包含中文、日文、韩文、俄文、希腊字母、阿拉伯文和数学符号等字符,明显256个值是不够的(65536个值也够呛),并且为了兼容ascii码表(已有的定义不能修改)。所以又有聪明人发明了双字节编码。
多字节编码大多情况都指双字节编码,但是这个名字并不准确,因为后面所讲的utf-8编码按原理来说也是多字节编码,但人们说多字节字符串的时候,往往是指双字节编码的字符串。
所谓双字节编码,就是用1个或2个char来表示1个字符。当用2个char时,可表示的数量就平方了,也就是65536。但实际并非如此,因为它需要兼容ascii码表。
当程序读取到1个char时,需要先判断它是否小于等于127,如果小于,则说明它是ascii码中的字符,它自己1个就代表了1个字符。如果它的值大于127,则说明它后面的一个char与自己组合起来代表一个字符,所以叫双字节编码。
首先我在vs里输入了一段utf-8编码的字符串(在项目命令行里定义/utf-8,可以使字符串字面量为utf-8编码),可以看到“a中文b”一共占7个char。
 utf-8编码
utf-8编码
随后我转为了双字节编码,可以看到变成了占用6个char。因为每个汉字占2个char,并且它的第一个char一定为大于127(char类型溢出到负数),如下图所示:
 双字节编码
双字节编码
可以看到,这时编译器可以正确识别字符串内的内容。因为它默认string的内容编码是双字节编码。如果要在断点中正确显示utf-8编码,可以使用u8string类型,它基于C++20的char8_t类型。不过到目前为止,需要多次点开才能看到字符串的实际内容。
回到双字节编码,第一个char可表示范围数量是128,而第二个是256,所以双字节编码所能表示的字符数量为128 + 128 * 256,为32896。
双字节编码也可称为本地编码,它有各种不同的规格,比如内地用的gb2312标准,台湾用的big5(大五码)标准。Windows系统在不同的国家和地区便是使用的不同的本地编码,使用记事本和excel导出的文件默认情况下都是双字节编码,当使用另一台非相同本地编码的计算机打开文件时就会出现乱码。使用notepad++可以看到有如下许多不同的本地编码:
 各式不同的双字节编码
各式不同的双字节编码
在vs里面,通过高级保存选项也可以设定代码文件使用的编码,此处并不影响编译,只是设定文件保存时存储数据的方式。可以看到每个编码都拥有代码页的定义值。其中中文(gb2312)是936,utf-8是65001(它不属于本地编码,但也有代码页),还有许多其他国家地区使用的本地编码。
 vs里的代码页
vs里的代码页
通过以上可以清楚的看到双字节编码的缺点,依赖它所编成的程序在换一个环境时就会出现乱码。如果通过指定代码页来保证正确,那么这件事也会变得维护艰难。
除此之外它还有一个严重的缺点,就是汉字被分为2个char,按语义来说“中文”二字的长度为2,但是实际它占4个char,在使用strlen之类的函数时,其含义发生了变化。例如在编写输入框控件时,就需要额外的判断来防止汉字被拆开。当然utf-8编码也有此缺点。
四、宽字符编码(wide char)
意识到以上问题后,为何不干脆直接用2个字节的类型表示字符呢?一共可表示65536个字符呢。于是出现了宽字符编码,也就是char变为了wchar_t。但是wchar_t的大小却没有规定,在windows系列编译器里它是2个字节,但在linux系列编译器里它是4个字节。这个缺点导致代码在跨平台时需要额外处理。
windows平台为了维护自己的正义性,一般称宽字符编码为unicode编码。这个说法没有错误,但是不够严格。
在vs编译器里面,我们可以设置项目的字符集。其中“使用unicode字符集”指的便是基于wchar_t类型的宽字符编码。
 vs设置字符集
vs设置字符集
微软将大部分的函数都写了两个版本,一个为A,一个为W。其中这里对应着char和wchar_t。也对应着双字节编码和宽字符编码。也可以叫多字节编码和unicode编码。在标准库中对应的是string和wstring。针对char的函数大部分都又以wchar_t版本实现了一遍,例如wcscmp与wcslen。
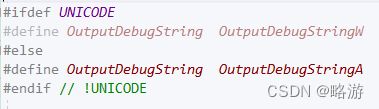 兼容双字节的宽字符写法
兼容双字节的宽字符写法
在代码中我们可以这样定义一个宽字符字符串:
就目前来说,许多旧工程使用的是双字节编码,部分新工程使用的是宽字符编码,然而还有少许人使用utf-8编码。先下一个结论,使用utf-8编码是时代潮流。
宽字符编码有个严重的缺点就是它没有定义大小,并且windows平台的实现是2字节的大小,对于汉语来说,是根本放不下的,比如《康熙字典》就收录了4万7千余汉字,而1994年的《中华字海》便超过了9万字。外国的程序员们在思考这个问题的时候,便出现了不一致的想法。65536绝已囊括大部分的文字,但是又放不下一些比较少用的文字。
五、unicode编码
所谓unicode编码就是每个字都用同样大小的类型保存,目前有基于2字节的UCS-2标准,和基于4字节的UCS-4标准。其中UCS-4是兼容UCS-2的,这意味着UCS-2转为UCS-4后所有高位为0。
其中UCS-2对应2字节的wchar_t,UCS-4对应4字节的wchar_t。但目前用得更多的还是UCS-2,但这并不代表它就应该被用,这有历史因素在里面。个人认为UCS-4优先于UCS-2,因为它们的缺点都是浪费空间,但UCS-4的优点更明显,它能表示的范围又平方了,40多亿的范围。
六、utf-8编码
用4个字节来表示文字,在处理时不会被拆开,一个字就是一个此类型。但是在表示英文和常用符号时却浪费了3倍的空间。于是聪明的程序员发明了utf-8编码,用它来压缩UCS-4编码,根据字符的值来占据不同的字节个数,所以它也可以视为“多字节编码”,叫变长字节编码更合适。
它是以char类型作为基础,这样在兼容ascii码时,就不需要进行截断。首先[0, 127]与ascii编码相同,当大于127时,它的最高位一定是1。
| 二进制 | 十进制 |
| 01111111 | 127 |
| 1000000 | 128 |
| 11111111 | 255 |
所以[0, 127]的值对应[00000000, 01111111],这与ascii码表一致,如果用x来替代可变位,则是0xxxxxxx。
当最高位为1时,如果我们用1xxxxxxx来表示另一堆字符,那么又可表示128个字符。所以一共可以表示256个字符……
很明显,1个char办不到更多的表示了,所以我们后面增加1个char。但是我们怎么知道后面的char是和前面一起的呢?所以我们约定最高位为1时,后面额外有个char。即如下两种情况:
| 二进制范围 | 十进制范围值 |
| 00000000 - 01111111 | 128 |
| 10000000 00000000 - 11111111 11111111 | 32768 |
可以看到双字节编码最多可以表示32896个字符,这与前面的计算结果一致。本身2字节可以表示的范围值为65536,这就是压缩数据带来的范围损耗。如果我们用x来表示可变位,那么根据x的数量计算2^x,则能更清晰的看到范围值:
0xxxxxxx 2^7
1xxxxxxx xxxxxxxx 2^15
这时我们会发现一个问题,此时无法表示后面拥有更多的char。因为第二高位是x,它的数据是变化的,无法作为控制位。假设我们以2位来表示后面所接的char数量:
00xxxxxx 后面0个char
01xxxxxx 后面1个char
10xxxxxx 后面2个char
11xxxxxx 后面3个char
很明显,01xxxxxx会不兼容ascii编码,所以我们总结出:“在有后接char时,最高位必须为1”。所以我们再次修改定义:
0xxxxxxx 后面0个char
100xxxxx 后面1个char
101xxxxx 后面2个char
110xxxxx 后面3个char
111xxxxx 后面4个char
根据x的数量,我们得出各自的表示范围值:
| 首字节二进制 | x数量 | 值 | 值 |
| 0xxxxxxx | 7 | 2^7 | 128 |
| 100xxxxx | 5+8 | 2^13 | 8192 |
| 101xxxxx | 5+16 | 2^21 | 2097152 |
| 110xxxxx | 5+24 | 2^29 | ... |
| 111xxxxx | 5+32 | 2^37 | ... |
通过这个方法,3个char可表示完UCS-2,而5个char才能表示完UCS-4。当字符的unicode编码小于128时,只用1个char。小于8192+128时使用2个char。在约200万的范围内只需要3个char。但要完全涵盖UCS-4,则必须是5个char。
但以上只是我们实验的方法,是数值范围最大的表示情况,实际上utf-8拥有纠错码,所有的后继char都以10开头(10xxxxxx)。它建立在一个断言之上:“字符的首个char必定不是10开头”。如下所示:
| 首字节二进制 | x数量 | 值 | 值 |
| 0xxxxxxx | 7 | 2^7 | 128 |
| 110xxxxx 10xxxxxx | 5+6 | 2^11 | 2048 |
| 1110xxxx 10xxxxxx(x2) | 4+12 | 2^16 | 65536 |
| 11110xxx 10xxxxxx(x3) | 3+18 | 2^21 | 2097152 |
| 111110xx 10xxxxxx(x4) | 2+24 | 2^26 | ... |
| 1111110x 10xxxxxx(x5) | 1+32 | 2^33 |
所以utf-8编码用2个char可以表示2048+128个值,3个char能够表示完UCS-2。要表示完整的UCS-4需要6个char。至于有些文章说utf-8编码的变长范围为[1, 4]是不正确的,由于4个char能表示约200万的字符,在当前看来是正确的。
在实际使用时,我们还会发现utf-8编码有带BOM和不带BOM的。所谓带BOM就是在文件头部多写入几个字节来表示自己是utf-8文件,并且可以标明自身的字节序。有标准推荐使用带BOM的utf-8,而微软也是这么操作的。但是我认为BOM属于文件的元数据(meta),一堆数据在那儿,它是什么取决于程序怎么解读,而一堆数据的一部分内容描述自己是什么,在一定程度上是多此一举。
七、结语
个人认为项目应该统一使用utf-8无BOM编码,在做文本编辑等逻辑时转换到utf-32编码,以进行字符串拆分、排版和显示等操作。
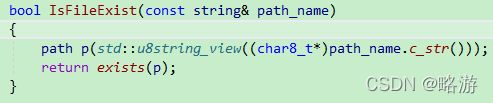
虽然C++20提出了char8_t类型来专门表示utf-8编码,但我们还是可以用char数组和string来表示utf-8字符串,因为编译器依旧支持字符串字面量直接为utf-8编码。在使用std::filesystem时,需要强转指针为u8string,这样标准库才知道你传入的是utf-8字符串,如下所示:
如果你觉得此文章写得不错,可以点击收藏,然后点击关注,这可以极大的支持我发更多的文章。
你还可以加我的QQ群讨论:游戏编程星云阁 170100866