深度学习基础:实现线性回归
一、说在前面
上一节总结了线性回归的基本要素。这一次用代码实现线性回归。在实际训练一个模型的时候,需要有以下一些步骤:

实际上,每个部分都有一些小技巧在里面。只能慢慢学了~
二、代码实现
1. 数据
由于是自己学习,将随机生成数据。在线性回归中具体是生成哪些数据呢?我们要达到的目的,给定影响一个房子放假的若干因素,比如面积和房龄,来预测出其房价。所以,我们需要生成以下数据:
- 很多很多个房子的面积和房龄,记为 x 1 , x 2 \boldsymbol{x_1,x_2} x1,x2
- 这些房子的真实价格,记为 y \boldsymbol{y} y
- 由于是线性回归,所以真实价格和面积、房龄之间存在线性关系。所以还需要这个关系中的权重 w \boldsymbol w w和偏差 b i a s \boldsymbol{bias} bias
- 由于实际情况中,影响房价的因素有很多,也不可能全包括进来。所以加入一个随机产生的扰动项 ϵ \boldsymbol{\epsilon} ϵ
实际上可以看出,房子的真实价格是通过第1、3、4个数据计算得出的,并不是生成的。
## 生成数据集
from mxnet import autograd, nd
num_inputs = 2 # 特征个数
num_examples = 1000 # 样本数量
true_w = [2, -3.4]
true_b = 4.2 # 真实的参数
features = nd.random.normal(scale=1, shape=(num_examples, num_inputs)) # 生成x
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b # 计算真实价格y
labels += nd.random.normal(scale=0.01, shape=labels.shape) # 加上扰动项
## 读取数据
from mxnet.gluon import data as gdata
batch_size = 10 # 批量大小
dataset = gdata.ArrayDataset(features, labels) # 获取数据特征和标签的组合
data_iter = gdata.DataLoader(dataset, batch_size, shuffle=True) # 随机读取小批量,返回若干个小批量
2. 模型准备
在这一小节,我们需要:定义模型、初始化模型参数、定义损失函数、定义优化算法。
## 模型定义
from mxnet.gluon import nn
net = nn.Sequential() # 可以看成一个容易,可以串联模型(网络)的所有层
# 在gluon中,不需要指定每一层输入的形状,模型会自动进行推断
net.add(nn.Dense(1)) # 线性规划只有一个全连接层,其输出是1维的
## 初始化模型参数
net.initialize(init.Normal(sigma=0.01)) # 生成均值为0,标准差为0.01的权重。偏差默认为0
## 定义损失函数
from mxnet.gluon import loss as gloss
loss = gloss.L2Loss() # 平方误差又称L2范数误差
## 定义优化算法
# 生成一个Trainer实例,将sgd作为优化算法,学习率为0.03
# net.collect_params()可以获取网络中所有层的所有参数
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning rate': 0.03})
3. 模型训练
在这一小节,我们需要:迭代训练模型、计算损失函数、对参数进行优化
## 模型训练
num_epochs = 3 # 迭代次数
for epoch in range(num_epochs):
for X, y in data_iter:
with autograd.record(): # 记录与梯度相关的计算
y_hat = net(X)
l = loss(y_hat, y)
l.backward() # 求导
trainer.step(batch_size) # 优化。所求梯度会被1/batch_size标准化
# 利用优化过的参数计算预测值,观察损失的变化
l = loss(net(features), labels) # 所有样本的loss值。还需要求一个平均值
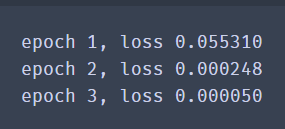
print('epoch %d, loss %f' % (epoch + 1, l.mean().asnumpy()))
三、完整代码及输出结果
from mxnet import autograd, nd
num_inputs = 2 # 特征个数
num_examples = 1000 # 样本数量
true_w = [2, -3.4]
true_b = 4.2 # 真实的参数
features = nd.random.normal(scale=1, shape=(num_examples, num_inputs)) # 生成x
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b # 计算真实价格y
labels += nd.random.normal(scale=0.01, shape=labels.shape) # 加上扰动项
## 读取数据
from mxnet.gluon import data as gdata
batch_size = 10 # 批量大小
dataset = gdata.ArrayDataset(features, labels) # 获取数据特征和标签的组合
data_iter = gdata.DataLoader(dataset, batch_size, shuffle=True) # 随机读取小批量,返回若干个小批量
## 模型定义
from mxnet.gluon import nn
net = nn.Sequential() # 可以看成一个容易,可以串联模型(网络)的所有层
net.add(nn.Dense(1)) # 线性规划只有一个全连接层,其输出是1维的
## 初始化模型参数
net.initialize(init.Normal(sigma=0.01)) # 生成均值为0,标准差为0.01的权重。偏差默认为0
## 定义损失函数
from mxnet.gluon import loss as gloss
loss = gloss.L2Loss() # 平方误差又称L2范数误差
## 定义优化算法
# 生成一个Trainer实例,将sgd作为优化算法,学习率为0.03
# net.collect_params()可以获取网络中所有层的所有参数
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning rate': 0.03})
## 模型训练
num_epochs = 3 # 迭代次数
for epoch in range(num_epochs):
for X, y in data_iter:
with autograd.record(): # 记录与梯度相关的计算
y_hat = net(X)
l = loss(y_hat, y)
l.backward() # 求导
trainer.step(batch_size) # 优化。所求梯度会被1/batch_size标准化
# 利用优化过的参数计算预测值,观察损失的变化
l = loss(net(features), labels) # 所有样本的loss值。还需要求一个平均值
print('epoch %d, loss %f' % (epoch + 1, l.mean().asnumpy()))