将目标检测SSD模型移植到Android手机上+调用摄像头拍照进行目标识别
续我的6月15号的博客,原本准备将我自己训练的YOLO V3的模型移植到手机上,但是尝试了几次都不成功,发现自己训练的模型,在转换成.pb文件之后,创建tensorflow接口总是失败,估计时我模型保存时有其他的问题,故想先移植一个官方demo能够运行的SSD模型。
目录
- 1.安卓手机显示的效果图
- 2.移植步骤-添加依赖和配置
-
- 2.1 将想要移植的模型放到指定位置
- 2.2 添加.so和 .jar的依赖
- 2.3 app\build.gradle(Module:app)配置
- 3.移植步骤-模型调用
-
- 3.1首先创建一个Classifier.java的接口
- 3.2创建一个类继承Classifier接口
- 3.3 调用模型,并传出识别结果
- 4.移植步骤-结果显示
-
- 4.1 图片传入模型前的处理
- 4.2 取出模型的识别结果
- 4.3 在原图上画出识别结果
- 5.总结
1.安卓手机显示的效果图
话不多说,先上我的手机最终显示的效果图。
这个图是我用摄像头进行拍照,然后调用模型进行识别,将结果在原图上进行显示并传送到ImageView上,最终使用保存按钮,保存的图片。
2.移植步骤-添加依赖和配置
我前期主要参考http://www.voidcn.com/article/p-rbnqjtim-brt.html,这篇中的第2 和第3部分
2.1 将想要移植的模型放到指定位置
把训练好的pb文件放入Android项目中app/src/main/assets下,若不存在assets目录,右键main->new->Directory,输入assets。
我这个步骤主要是从tensorflow的官方demo中将ssd_mobilenet_v1_android_export.pb和coco_labels_list.txt copy过来放到了assets文件夹下面
2.2 添加.so和 .jar的依赖
将下载的libtensorflow_inference.so和libandroid_tensorflow_inference_java.jar如下结构放在libs文件夹下,这个依赖文件我会放到我的资源里,可以直接下载。
2.3 app\build.gradle(Module:app)配置
在defaultConfig中添加
multiDexEnabled true
ndk {
abiFilters "armeabi-v7a"
}
增加sourceSets
sourceSets {
main {
jniLibs.srcDirs = ['libs']
}
}
添加完之后的截图如下:
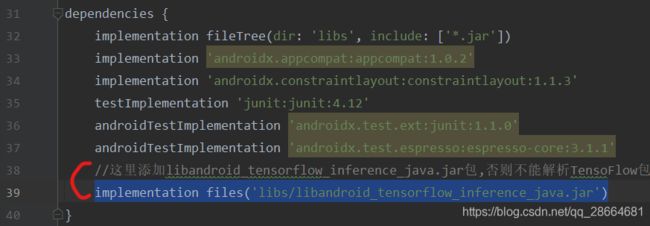
在dependencies中增加TensoFlow编译的jar文件libandroid_tensorflow_inference_java.jar:
implementation files('libs/libandroid_tensorflow_inference_java.jar')
到现在为止,build.gradle就配置完成了,接下来就是模型调用问题了。
3.移植步骤-模型调用
3.1首先创建一个Classifier.java的接口
新建接口和新建类一样的,这里不重复。
这个类是从官方demo中直接抄的,没有做任何的修改,所以直接复制粘贴就行了。
package com.example.mycamera;
import android.graphics.Bitmap;
import android.graphics.RectF;
import java.util.List;
public interface Classifier {
/**
* An immutable result returned by a Classifier describing what was recognized.
*/
public class Recognition {
/**
* A unique identifier for what has been recognized. Specific to the class, not the instance of
* the object.
*/
private final String id;
/**
* Display name for the recognition.
*/
private final String title;
/**
* A sortable score for how good the recognition is relative to others. Higher should be better.
*/
private final Float confidence;
/** Optional location within the source image for the location of the recognized object. */
private RectF location;
public Recognition(
final String id, final String title, final Float confidence, final RectF location) {
this.id = id;
this.title = title;
this.confidence = confidence;
this.location = location;
}
public String getId() {
return id;
}
public String getTitle() {
return title;
}
public Float getConfidence() {
return confidence;
}
public RectF getLocation() {
return new RectF(location);
}
public void setLocation(RectF location) {
this.location = location;
}
@Override
public String toString() {
String resultString = "";
if (id != null) {
resultString += "[" + id + "] ";
}
if (title != null) {
resultString += title + " ";
}
if (confidence != null) {
resultString += String.format("(%.1f%%) ", confidence * 100.0f);
}
if (location != null) {
resultString += location + " ";
}
return resultString.trim();
}
}
List recognizeImage(Bitmap bitmap);
void enableStatLogging(final boolean debug);
String getStatString();
void close();
}
3.2创建一个类继承Classifier接口
创建的这个类主要的功能是:1.创建一个模型的接口,2.将需要识别的图片传入模型 3.将识别的结果从模型中取出,并返回最终结果。
//继承Classifier类的create功能
public static Classifier create(
final AssetManager assetManager,
final String modelFilename,
final String labelFilename,
final int inputSize) throws IOException {
final TFYoloV3Detector d = new TFYoloV3Detector();
InputStream labelsInput = null;
String actualFilename = labelFilename.split("file:///android_asset/")[1];
labelsInput = assetManager.open(actualFilename);
BufferedReader br = null;
br = new BufferedReader(new InputStreamReader(labelsInput));
String line;
while ((line = br.readLine()) != null) {
//LOGGER.w(line);
d.labels.add(line);
}
br.close();
d.inferenceInterface = new TensorFlowInferenceInterface(assetManager, modelFilename);
final Graph g = d.inferenceInterface.graph();
d.inputName = "image_tensor";
final Operation inputOp = g.operation(d.inputName);
if (inputOp == null) {
throw new RuntimeException("Failed to find input Node '" + d.inputName + "'");
}
d.inputSize = inputSize;
final Operation outputOp1 = g.operation("detection_scores");
if (outputOp1 == null) {
throw new RuntimeException("Failed to find output Node 'detection_scores'");
}
final Operation outputOp2 = g.operation("detection_boxes");
if (outputOp2 == null) {
throw new RuntimeException("Failed to find output Node 'detection_boxes'");
}
final Operation outputOp3 = g.operation("detection_classes");
if (outputOp3 == null) {
throw new RuntimeException("Failed to find output Node 'detection_classes'");
}
// Pre-allocate buffers.
d.outputNames = new String[] {"detection_boxes", "detection_scores",
"detection_classes", "num_detections"};
d.intValues = new int[d.inputSize * d.inputSize];
d.byteValues = new byte[d.inputSize * d.inputSize * 3];
d.outputScores = new float[MAX_RESULTS];
d.outputLocations = new float[MAX_RESULTS * 4];
d.outputClasses = new float[MAX_RESULTS];
d.outputNumDetections = new float[1];
return d;
}
直接继承这个Classifier接口,可能会报错,只需要在报错的地方,点击显示的红色的小灯泡,然后就可以继承这个接口了。
3.3 调用模型,并传出识别结果
public List recognizeImage(final Bitmap bitmap) {
//Bitmap bitmapResized = bitmapToFloatArray(bitmap,inputSize,inputSize);//需要将图片缩放带28*28
// Copy the input data into TensorFlow.
bitmap.getPixels(intValues, 0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight());
for (int i = 0; i < intValues.length; ++i) {
byteValues[i * 3 + 2] = (byte) (intValues[i] & 0xFF);
byteValues[i * 3 + 1] = (byte) ((intValues[i] >> 8) & 0xFF);
byteValues[i * 3 + 0] = (byte) ((intValues[i] >> 16) & 0xFF);
}
//将需要识别的图片feed给模型
inferenceInterface.feed(inputName, byteValues, 1, inputSize, inputSize, 3);
inferenceInterface.run(outputNames, logStats);//运行模型
outputLocations = new float[MAX_RESULTS * 4];
outputScores = new float[MAX_RESULTS];
outputClasses = new float[MAX_RESULTS];
outputNumDetections = new float[1];
//将识别的结果取出来
inferenceInterface.fetch(outputNames[0], outputLocations);
inferenceInterface.fetch(outputNames[1], outputScores);
inferenceInterface.fetch(outputNames[2], outputClasses);
inferenceInterface.fetch(outputNames[3], outputNumDetections);
// Scale them back to the input size.
final ArrayList recognitions = new ArrayList();
for (int i = 0; i < (int)outputNumDetections[0]; ++i) {
final RectF detection =
new RectF(
outputLocations[4 * i + 1] * inputSize,
outputLocations[4 * i] * inputSize,
outputLocations[4 * i + 3] * inputSize,
outputLocations[4 * i + 2] * inputSize);
recognitions.add(
new Recognition("" + i, labels.get((int) outputClasses[i]), outputScores[i], detection));
}
/*final ArrayList recognitions = new ArrayList();
for (int i = 0; i <= Math.min(pq.size(), MAX_RESULTS); ++i) {
recognitions.add(pq.poll());
}*/
return recognitions;
}
4.移植步骤-结果显示
4.1 图片传入模型前的处理
将图片缩放至指定的大小:bitmap即为你想要输入模型的图片
Bitmap bitmapResized = bitmapResize(bitmap,YOLO_INPUT_SIZE,YOLO_INPUT_SIZE);//需要将图片缩放至416*416
其中bitmapResize的函数如下:
//将原图缩放到模型的指定输入大小,bitmap是原图,rx,ry是模型的输入图片大小
public static Bitmap bitmapResize(Bitmap bitmap, int rx, int ry){
int height = bitmap.getHeight();
int width = bitmap.getWidth();
// 计算缩放比例
float scaleWidth = ((float) rx) / width;
float scaleHeight = ((float) ry) / height;
Matrix matrix = new Matrix();
matrix.postScale(scaleWidth, scaleHeight);
bitmap = Bitmap.createBitmap(bitmap, 0, 0, width, height, matrix, true);
return bitmap;
}
计算原图和送入模型的图像缩放比:scaleimageX和scaleimageY的类型为float
scaleimageX=(float) (bitmap.getWidth()*1.0)/bitmapResized.getWidth();//计算原图和送入模型的缩放比例x方向
scaleimageY=(float)(bitmap.getHeight()*1.0)/bitmapResized.getHeight();//计算原图和送入模型的缩放比例x方向
4.2 取出模型的识别结果
final List results = detector.recognizeImage(bitmapResized);//取出识别的结果
4.3 在原图上画出识别结果
首先设置画布和画笔的参数,然后计算模型识别结果到原图的映射,最终画出目标检测结果边界框、类别和概率。代码如下:
croppedBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true);//copy原图
final Canvas canvas = new Canvas(croppedBitmap);//创建一个新画布
final Paint paint = new Paint();//创建绘制
paint.setColor(Color.RED);//设置颜色
paint.setStyle(Paint.Style.STROKE);//创建绘制轮廓
paint.setStrokeWidth(5.0f);//设置画笔的宽度
final Paint paintText = new Paint();//创建字体
paintText.setColor(Color.RED);//设置颜色
paintText.setTextSize(80);//设置子图大小
float minimumConfidence = MINIMUM_CONFIDENCE_YOLO;
final List mappedRecognitions =
new LinkedList();
for (final Classifier.Recognition result : results) {
//还原边界框在原图的位置
final RectF location = new RectF(
result.getLocation().left *= scaleimageX,
result.getLocation().top *= scaleimageY,
result.getLocation().right *= scaleimageX,
result.getLocation().bottom *= scaleimageY);
//判断大于设置的置信度则将位置在原图上标记出来
if (location != null && result.getConfidence() >= minimumConfidence) {
//location[0]=location[0]*
canvas.drawRect(location, paint);//画边界框
canvas.drawText(result.getTitle()+" "+result.getConfidence(),
location.left,
location.top-10,
paintText);//将类别和概率显示在图上
//cropToFrameTransform.mapRect(location);
result.setLocation(location);
mappedRecognitions.add(result);
}
}
cameraPicture.setImageBitmap(croppedBitmap);//将最终的图显示在ImageVieView控件
到这里,调用模型的步骤就结束了,我主要是阅读tensorflow中的Android的demo,从里面抽取出我需要的功能,最终成功了。
5.总结
耗时6天,完成了每天除了吃饭睡觉一直在干的事情。从刚开始的一头雾水不知道从何下手,最终完成了我所需要的模型调用功能。这次最大的收获是,知道了Android端调用深度学习模型的几个步骤,相当于我毕设的倒数第二章已经完成,下一步是查找正确的保存模型并正确的转换成.pb文件的方法,将自己训练的粮虫识别的模型移植到手机上。
自己的收获:还是要静下心阅读源码,不能急躁,一直想这抄现成的。
离最后的成功又近一步,加油自己!