李宏毅学习笔记32.GAN.03.Unsupervised Conditional Generation
文章目录
- 简介
- Unsupervised Conditional Generation
- Direct Transformation
-
- 法1:直接忽略
- 法2:向量化限制
- 法3:Cycle GAN
-
- Issue of Cycle Consistency
- 其他Cycle GAN
- starGAN For multiple domains
- Projection to Common Space
- Voice Conversion
- Reference
简介
上节讲了Conditional GAN,这个GAN是监督学习,带标签的,这节看Unsupervised Conditional GAN
公式输入请参考:在线Latex公式
Conditional GAN如果做到Unsupervised呢?我们先来看几个例子:
Transform an object from one domain to another without paired data (e.g. style transfer)
有两组数据,一组是正常的风景照,一组是复古画,两组数据没有任何的联系。现在要训练一个NN,把风景照图片转换为复古画。



Unsupervised Conditional Generation
从文献上看有两大类的做法。
Approach 1: Direct Transformation(直接转,只能小改:颜色、纹理),主要用在:For texture or color change
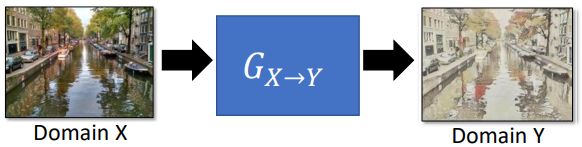
• Approach 2: Projection to Common Space(抽取图片的特征,眼镜、男性。再生成对应的动漫角色),主要用在:Larger change, only keep the semantics(下面的例子不是实作的效果)
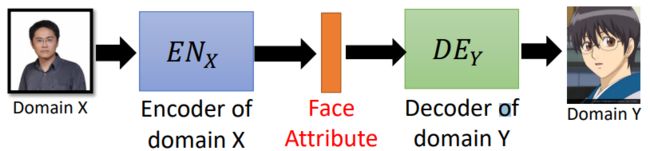
下面分别详细讲:
Direct Transformation
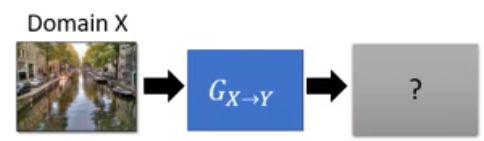
现有有两个domain的数据:

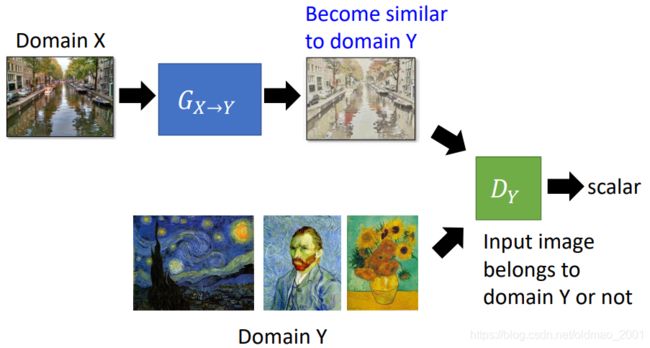
现在的问题是如果输入Domain X的数据,然后用Generator: G X → Y G_{X\rightarrow Y} GX→Y生成对应的Domain Y的图片?如果是监督学习那是没问题的,因为Generator看过Domain Y的风格。现在是非监督的学习方法。
于是我们需要加入一个根据Domain Y的Discriminator: D Y D_Y DY:
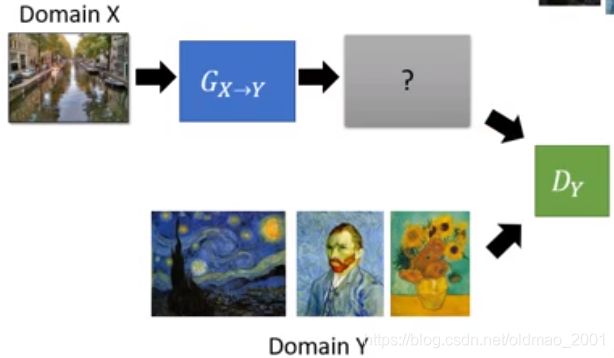
这个 D Y D_Y DY可以输出一个向量,用于鉴别图片是不是输入Domain Y的风格的图片。
Generator就要要生成类似Domain Y的风格的图片,骗过Discriminator:
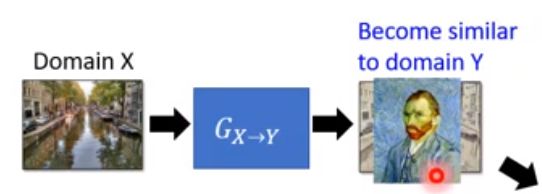
但是如果仅仅是这样,Generator可以直接生成一张与原输入无关,但是与Domain Y的风格类似的图片就直接可以骗过Discriminator:
我们来看如何解决这个问题:
法1:直接忽略
法1:直接忽略这个问题,因为当Generator不是很deep的时候(很shallow),输入和输出不会差得太远,例如你输入一个山水画,输出一个人头这样的事情是不会出现的。
The issue can be avoided by network design. Simpler generator makes the input and output more closely related.[Tomer Galanti, et al. ICLR, 2018]
法2:向量化限制
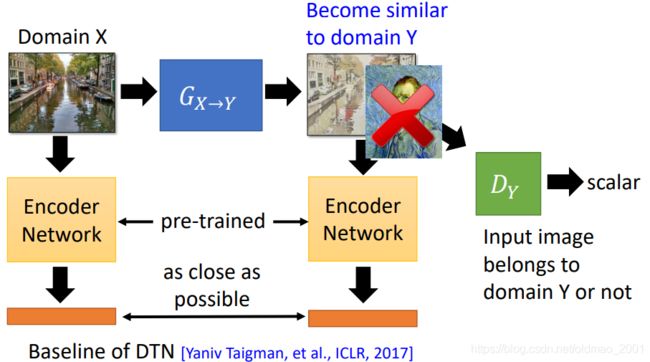
法2:当Generator比较deep,这个时候可以把模型的输入输出接两个预训练(pre-trained)好的NN,这两个NN把Generator的输入和输出分别embedding为一个向量。然后训练Generator条件变为:输入和输出的embedding要越相近越好,然后还要尽量骗过Discriminator:
法3:Cycle GAN
法3:[Jun-Yan Zhu, et al., ICCV, 2017],用两个Generator,第二个(橙色的)Generator要把第一个Generator生成对象重新还原回原输入的照片。两个Generator接在一起,被称为:Cycle GAN。
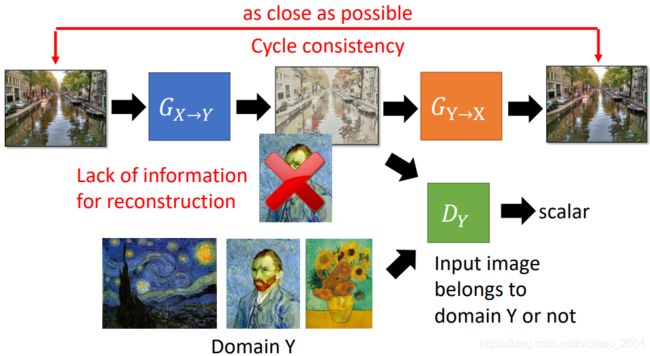
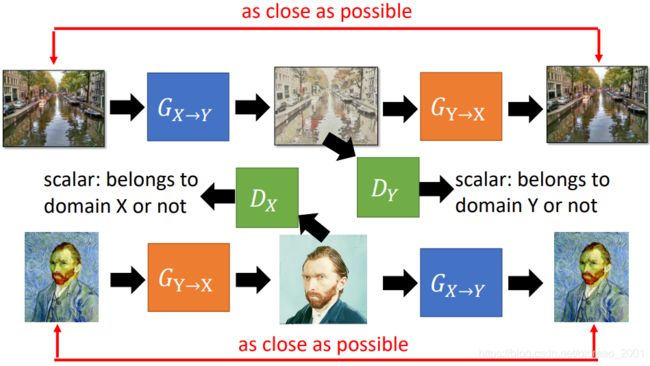
上面还有一个变种,很容易理解,注意模块的颜色:
下面看Cycle GAN的实例:
https://github.com/Aixile/chainer-cyclegan

全部转为银发:

Issue of Cycle Consistency
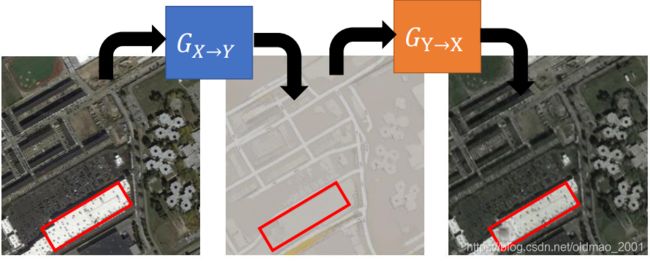
上面的例子我们可以看到转化的图片中(注意红框中的黑点)隐藏了一些信息(The information is hidden.)这个好吗?
从加密的角度来看这个和隐写术很像(• CycleGAN: a Master of Steganography (隱寫術):[Casey Chu, et al., NIPS workshop, 2017] )
但是从我们之前的约束中提到要使得 G X → Y G_{X\rightarrow Y} GX→Y的输入和输出不能差太远,限制Generator会自己把信息藏起来了,就会使得输入输出差别较大,不好。
其他Cycle GAN
同一时间不同作者提出来的与Cycle GAN一样的东西:
Disco GAN[Taeksoo Kim, et al., ICML, 2017]
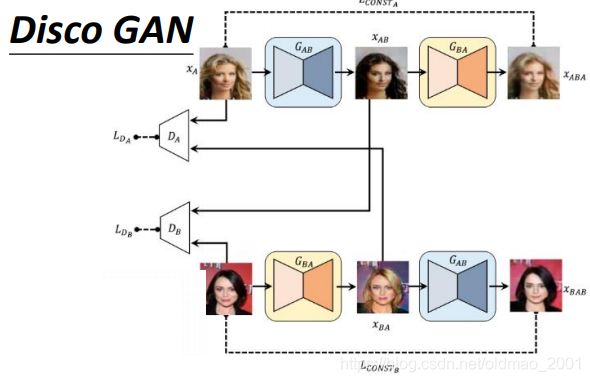
Dual GAN[Zili Yi, et al., ICCV, 2017]

starGAN For multiple domains
For multiple domains, considering starGAN[Yunjey Choi, arXiv, 2017]
(a)Cross-domain models
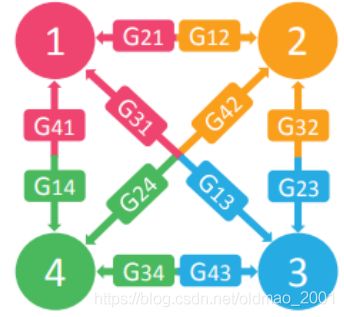
(b)StarGAN
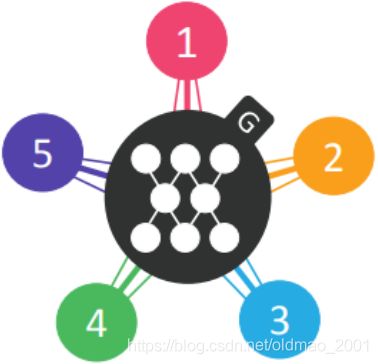
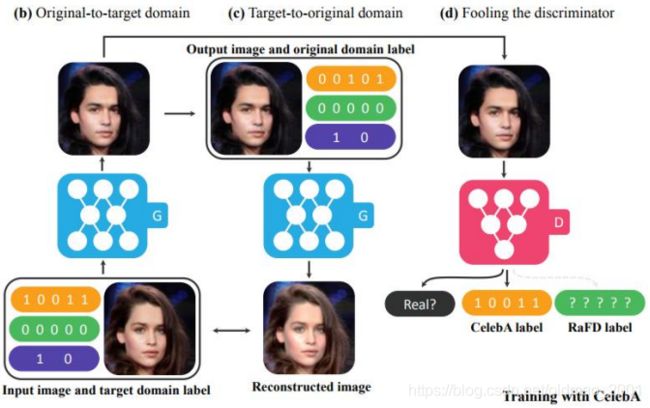
starGAN里面其实用到了Cycle GAN,看下大概步骤:
(a)Training the discriminator,吃一个图片,输出两个东西,一个是图片是真假,一个是图片所属的Domain。
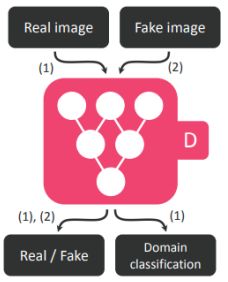
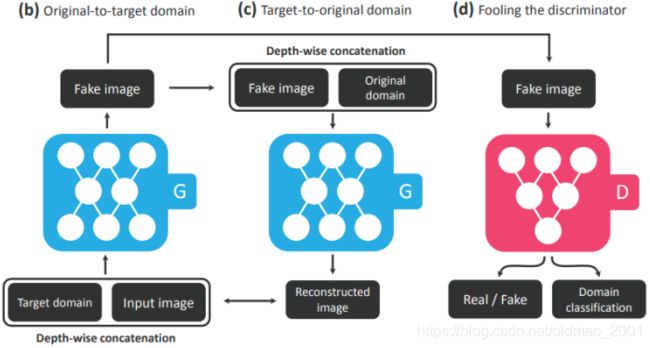
这里的b和c就是用到了Cycle GAN的思想,左边的Generator吃输入图片和目标Domain,输出一个Fake Image,然后右边的Generator吃Fake Image加源Domain要还原回输入图片,而且左边的Generator输出的Fake Image要尽量骗过Discriminator(一来是真图片,二来是目标Domain)。
下面看实例:
(a)Training the discriminator
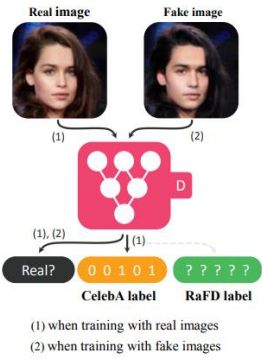
这里表示multi-domain的方法是用编码:
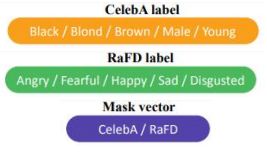
上面的黄色模块00101就是对应:Brown/Young的两个特征。
另外一个改表情的例子:

Projection to Common Space
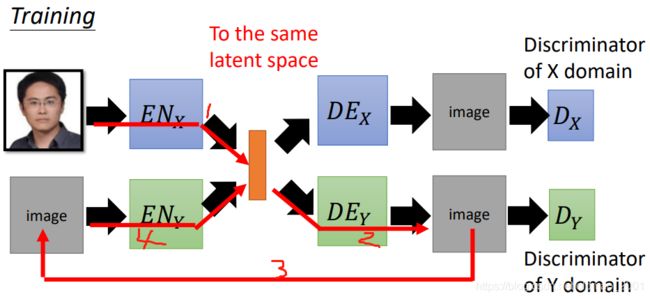
我们想要做到:
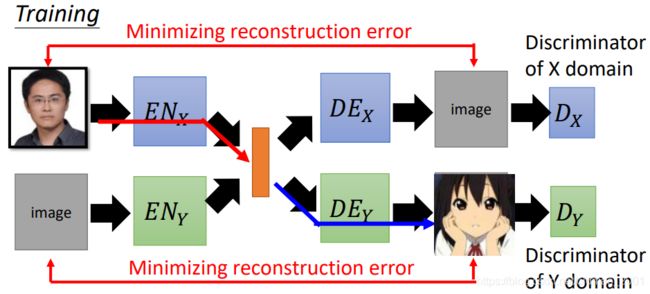
真人图片丢到 E N X EN_X ENX,可以抽出真人的特征到latent vector(橙色),然后经过二次元的 D E Y DE_Y DEY得到对应的二次元图片
二次元图片丢到 E N Y EN_Y ENY,可以抽出二次元的特征到latent vector(橙色),然后经过真人的 D E X DE_X DEX得到对应的二次元图片

如果是监督学习,我们已经有真人和二次元特征的对应关系,那很好做,但是我们现在没有他们之间的关系,只有:

那怎么训练两组encoder和decoder呢?我们把真人的encoder和decoder一起训练,二次元的encoder和decoder一起训练:
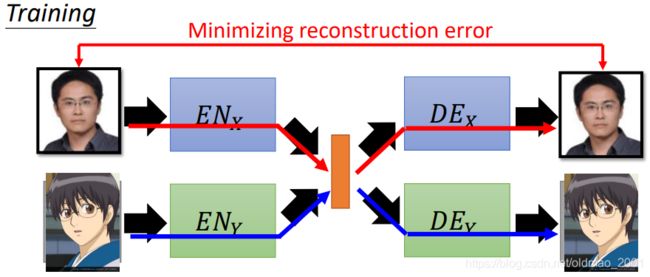
如果只是以Minimizing reconstruction error为目标,就是单纯的AE了,之前说过,这样生成的图片会很模糊,因此我们要加一个Discriminator模块:

这样我们就得到了 E N X + D E X + D X EN_X+DE_X+D_X ENX+DEX+DX和 E N Y + D E Y + D Y EN_Y+DE_Y+D_Y ENY+DEY+DY两套VAE GAN
Because we train two auto-encoders separately …
The images with the same attribute may not project to the same position in the latent space.
可能真人的特征表示用第一维表示性别,第二维表示眼镜;而二次元的特征表示用第一维表示眼镜,第二维表示性别。
因此会得到:
解决这个问题可以用:
法1:
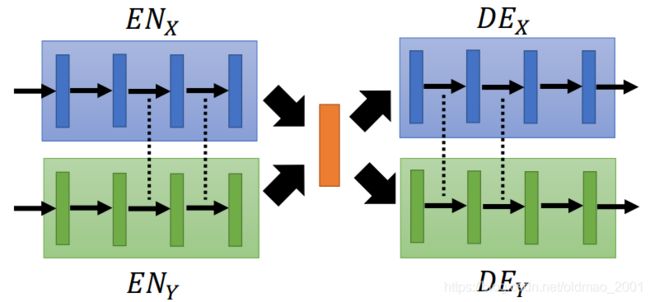
部分参数共享,就是真人和二次元模型的部分隐藏层的参数是共享的(注意下图中虚线的部分)。
使用这个技巧的两个文章:
Couple GAN[Ming-Yu Liu, et al., NIPS, 2016]
UNIT[Ming-Yu Liu, et al., NIPS, 2017]
实作上:直接用code代表不同的Domain,例如1表示真人,-1表示二次元,Encoder和decoder用的是同一套。
法2:
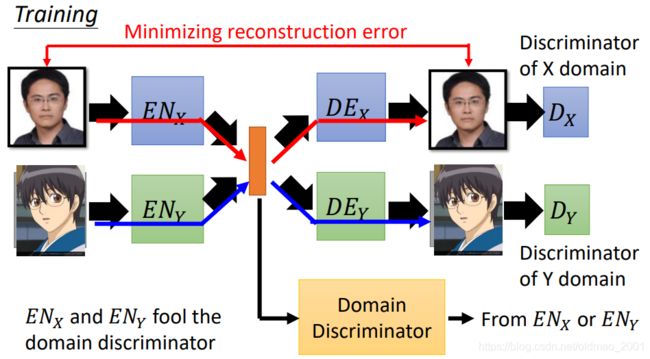
在中间的特征表示上接一个Domain Discriminator,这个Discriminator可以判断特征表示是来自哪个Encoder。而两个Encoder的限制多了一个:要使得Domain Discriminator无法分辨特征表示是来自哪个Encoder。意味两个Encoder产生的特征表示都来自同一个分布。
The domain discriminator forces the output of E N X EN_X ENX and E N Y EN_Y ENY have the same distribution.[Guillaume Lample, et al., NIPS, 2017]
法3:
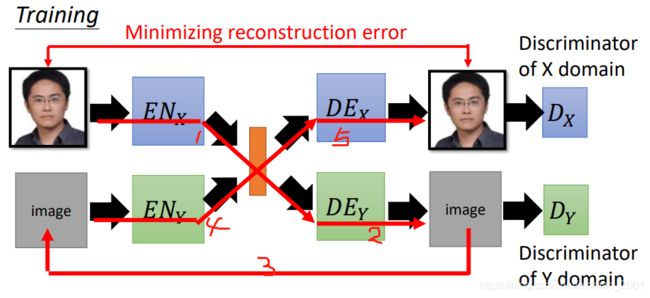
Cycle Consistency: Used in ComboGAN [Asha Anoosheh, et al., arXiv, 017]
真人图片经过1.2.3.4.5.个步骤还原回真人图片,这两个图片越像越好。当然右边的输出还要分别满足两个Discriminator的条件。
法4:
Semantic Consistency: Used in DTN [Yaniv Taigman, et al., ICLR, 2017] and XGAN [Amélie Royer, et al., arXiv, 2017]
真人图片经过1号步骤得到的特征表示,以及真人图片经过1.2.3.4.号步骤得到的特征表示要越接近越好。
因为上面的法3中最后比较差异是比较两个图片,我们说过图片与图片的pixel to pixel的比较是有缺陷的,因此这里直接用特征表示进行比较。
例子:https://github.com/Hi-king/kawaii_creator
It is not cycle GAN, Disco GAN.
数据:

结果,老师变身萌妹子。。。

Voice Conversion
In the past,用的监督学习的方法,要有一堆对应的声音:

然后训练一个seq2seq的模型就可以了,但是这个模型是有缺陷的,例如我想要变声为张学友,那很难请到张学友跟我一起念同样的句子,然后来训练,很麻烦。那如果我想要变声为尼古拉斯凯奇,那就很难搞了,因为他不会中文,就算请到他也讲不来相同的句子。
Today,我们只要收集两组声音,不用讲一样的内容就可以进行训练。
Speakers A and B are talking about completely different things.

Reference
• Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros, Unpaired Image-toImage Translation using Cycle-Consistent Adversarial Networks, ICCV, 2017
• Zili Yi, Hao Zhang, Ping Tan, Minglun Gong, DualGAN: Unsupervised Dual Learning for Image-to-Image Translation, ICCV, 2017
• Tomer Galanti, Lior Wolf, Sagie Benaim, The Role of Minimal Complexity Functions in Unsupervised Learning of Semantic Mappings, ICLR, 2018
• Yaniv Taigman, Adam Polyak, Lior Wolf, Unsupervised Cross-Domain Image Generation, ICLR, 2017
• Asha Anoosheh, Eirikur Agustsson, Radu Timofte, Luc Van Gool, ComboGAN: Unrestrained Scalability for Image Domain Translation, arXiv, 2017
• Amélie Royer, Konstantinos Bousmalis, Stephan Gouws, Fred Bertsch, Inbar Mosseri, Forrester Cole, Kevin Murphy, XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings, arXiv, 2017
• Guillaume Lample, Neil Zeghidour, Nicolas Usunier, Antoine Bordes, Ludovic Denoyer, Marc’Aurelio Ranzato, Fader Networks: Manipulating Images by Sliding Attributes, NIPS, 2017
• Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, Jiwon Kim, Learning to Discover Cross-Domain Relations with Generative Adversarial Networks, ICML, 2017
• Ming-Yu Liu, Oncel Tuzel, “Coupled Generative Adversarial Networks”, NIPS, 2016
• Ming-Yu Liu, Thomas Breuel, Jan Kautz, Unsupervised Image-to-Image Translation Networks, NIPS, 2017
• Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo, StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation, arXiv, 2017