【关系抽取】TPLinker:单阶段联合抽取,并解决暴漏偏差
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
信息抽取的两种工作模式
TPLinker
Token Pair的表示
信息抽取的两种工作模式
Pipeline(流水线)形式
把关系抽取拆分为多个子任务。每个子任务都依赖前面的任务结果作为输入,该种工作形式存在着曝光偏差和误差传播的问题。
Joint(联合)模式
不同任务间共享编码层,通过编码层参数共享来实现实体抽取和关系抽取的信息交互。
不同任务间没有相互输入依赖。One-Stage形式。
error accumulation 误差传播 前序任务的误差(如: 识别遗漏)的错误结果,会传递给后续任务而导致的误差。由于前后任务间结果传递的依赖性,所以错误传播是不可逆的。
exposure bias 曝光偏差 后序任务模型训练时,使用真实标签作为模型的输入。而后序任务在推理时则是重新开始推理。和前序任务缺少直接的关联性。
联合抽取主要分为2种范式:
- 多任务学习:即实体和关系任务共享同一个编码器,但通常会依赖先后的抽取顺序:关系判别通常需要依赖实体抽取结果。这种方式会存在暴漏偏差,会导致误差积累。
- 结构化预测:即统一为全局优化问题进行联合解码,只需要一个阶段解码,解决暴漏偏差。
暴漏偏差:指在训练阶段是gold实体输入进行关系预测,而在推断阶段是上一步的预测实体输入进行关系判断;导致训练和推断存在不一致。

TPLinker要解决什么问题?
基于结构化预测的联合抽取方法,最早出现在17年论文《Joint extraction of entities and relations based on a novel tagging scheme》中,这篇论文用一个统一的序列标注框架抽取实体关系,如上图所示:直接以关系标签进行BIOES标注,subject实体序号为1,object实体序号为2。

Single Entity Overlap (SEO) 单实体重叠
Entity Pair Overlap (EPO) 实体对重叠
Subject Object Overlap (SOO) 主体、目标重叠
也就是说:结构化预测不能在解决暴漏偏差的同时,却不能cover关系重叠问题。因此,TPLinker要同时能够解决这两个问题。
TPLinker
TPLinker 是中科大2020年的一篇论文。提出了一种实体和重叠关系联合提取的单阶段(one stage)解决方案。
其思想是把联合抽取任务转化成一个Token对链接 (Token Pair Linking) 问题。
具体实现就是:把每种spo关系标注转换成为3个token链接矩阵,然后第1个矩阵用于抽取subject和object,另外两个矩阵分别对应着subject头部与object头部,subject尾部与object尾部,这两对组合在当前关系下是否成立。最后利用handshaking tagging scheme来做一个实体关系之间的对齐,从而解码出三元组。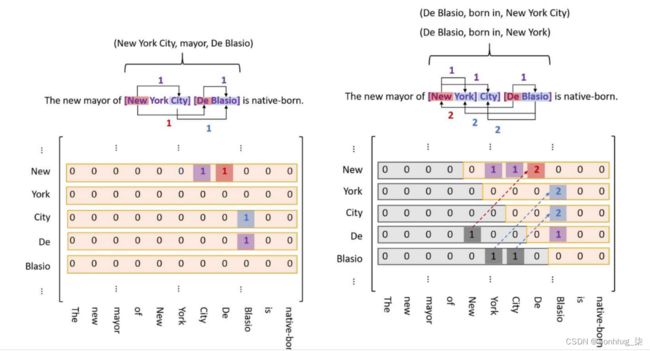
左图是一个Token链接矩阵,其中每种颜色对应一种特定的token。
给定一个句子的链接矩阵用来表示特定的关系r,其中使用行列位置p_1,p_2来进行标记:
- p_1和p_2标记实体的起始和结束位置
- p_1和p_2标记属于关系r的两个实体的起始位置
- p_1和p_2标记属于关系r的两个实体的结束位置
问题:
在关系非常多的情况下,每个关系都会映射一个Token链接矩阵。矩阵非常多,同时也非常稀疏。
由于实体的尾部不可能出现在头部之前,所以矩阵的下三角区域全部都是0值,本身对内存的浪费也非常大。
关键是在原始语料中,object实体的出现位置很有可能出现在subject之前,所以直接放弃下三角区域也是不合理的。
为此,设计者提出的解决的方案是把下三角区域中的所有标记1映射到上三角区域的标记2中,然后再删除下三角区域。
这样虽然解决了合理性问题,但矩阵的内存的浪费问题并没有得到彻底的解决。
右图是一张handshaking tagging scheme矩阵,阴影部分标记的就是object和subject位置倒置的问题和解决方案。
为了张量计算的方便。在实际操作中,上三角区域被展平成了一个序列。序列中的每个元素映射原矩阵中的位置关系。
序列的这种映射方式类似于token之间的 handshaking,设计者称这种序列为 handshaking tagging scheme。
这种标记方案可以解决实体重叠(SEO)和实体嵌套问题,但是却不能解决实体对重叠(EPO)问题,因为在一个矩阵中,不能标记不同关系的同一个实体对。
解决方案就是——为每个关系独立标记,创建多个 handshaking tagging 序列来分别标记实体对的首尾。
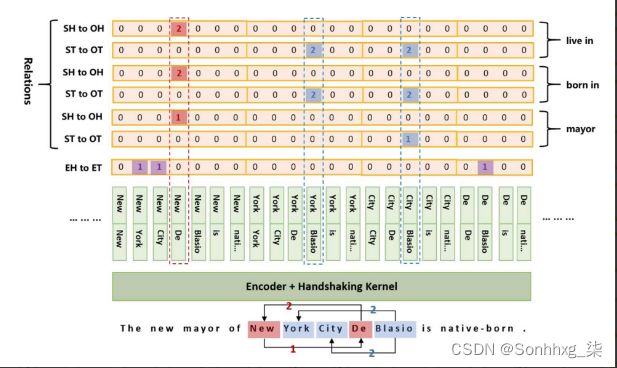
-
EH(Entity Head) to ET(Entity Tail)矩阵
用来标记Subject实体和Object实体的起始和结束位置
-
SH(Subject Head) to OH(Object Head)矩阵
用来标记某种特定关系情况下的Subject和Object实体的起始位置
-
ST(Subject Tail) to OT(Object Tail)矩阵
用来标记某种特定关系情况下的Subject和Object实体的结束位置
这里的 EH to ET序列是所有关系对序列共享的,因为它只关注的实体的提取。
Token Pair的表示
通过把给定长度为n的句子[w_1,\cdots,w_n],先抽取出每个token的w_i映射成一个低维的向量h_i,把它作为编码器。
之后再为每个 token pair (w_i,w_j) 生成一个对应的 h_{i,j} 表示
![]()
其中W_h是参数矩阵,b_h 是偏置。该公式表示的就是上图中的 Handshaking Kernel 。
TPLinker 代码实现:TPLinker-joint-extraction