TPLinker实体关系抽取新范式TPLinker:单阶段联合抽取,并解决暴漏偏差~
https://zhuanlan.zhihu.com/p/342300800(https://zhuanlan.zhihu.com/p/342300800)
https://zhuanlan.zhihu.com/p/346897151(https://zhuanlan.zhihu.com/p/342300800)
Pipeline方式
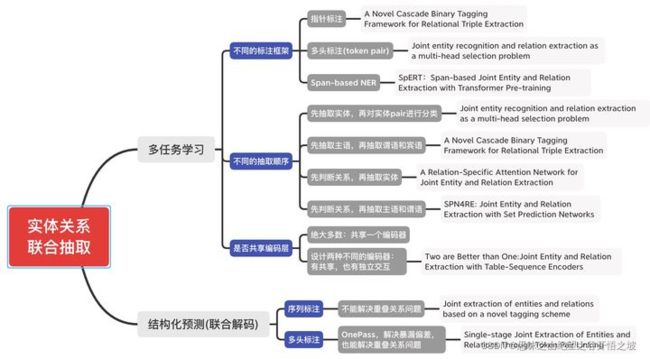
联合抽取主要分为2种范式:
多任务学习:即实体和关系任务共享同一个编码器,但通常会依赖先后的抽取顺序:关系判别通常需要依赖实体抽取结果。这种方式会存在暴漏偏差,会导致误差积累。
结构化预测:即统一为全局优化问题进行联合解码,只需要一个阶段解码,解决暴漏偏差。
暴漏偏差:指在训练阶段是gold实体输入进行关系预测,而在推断阶段是上一步的预测实体输入进行关系判断;导致训练和推断存在不一致。
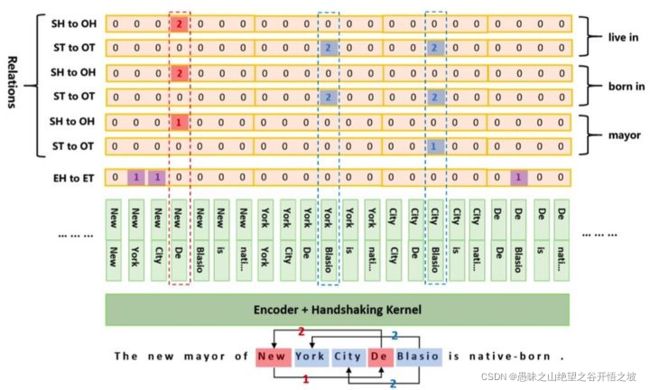
每个关系都是单独的两个矩阵
上图给出了一个完整的标注和编码示意图,标记有“0、1、2”三种。
编码部分实际上是将原始的Span矩阵会展开为一个[公式]序列进行编码,也就是将token pair的每一个token编码拼接在一起。
TPLinker的解码过程为:
1、解码EH-to-ET可以得到句子中所有的实体,用实体头token idx作为key,实体作为value,存入字典D中;
2、对每种关系r,解码ST-to-OT得到token对存入集合E中,解码SH-to-OH得到token对并在D中关联其token idx的实体value;
3、对上一步中得到的SH-to-OH token对的所有实体value对,在集合E中依次查询是否其尾token对在E中,进而可以得到三元组信息。
结合上图的具体case,我们具体描述一下解码过程:
解码EH-to-ET中得到3个实体:{New York,New York City,De Blasio}; 字典D为:{New:(New York,New York City),De:(De Blasio)}
以关系“mayor”为例,
1、解码ST-to-OT得到集合E:{(City,Blasio)};解码SH-to-OH得到{(New,De)},其在字典D中可关联的subject实体集合为{New York,New York City};object集合{De Blasio};
2、遍历上述subject集合和object集合,并在集合E中查询尾token,发现只有一个实体三元组{New York City,mayor,De Blasio}
以关系“born in”为例,
1、解码ST-to-OT得到集合E:{(Blasio,York),(Blasio,City)};解码SH-to-OH得到{(De,New)},其在字典D中可关联的subject实体集合为{De Blasio};object集合为{New York,New York City};
2、遍历上述subject集合和object集合,并在集合E中查询尾token,可得到2个实体三元组:{De Blasio,born in,New York}和{De Blasio,born in,New York City}
由于关系live in与born in一样,所以我们最终可得到5个三元组:
(New York City, mayor, De Blasio), (De Blasio, born in, New York), (De Blasio, born in, New York City), (De Blasio, live in, New York), (De Blasio, live in, New York City)
其实,只要TPLinker的解码过程,对这篇论文就会有深刻的理解了!大家一定要多看哦~