《文本分析》结课报告
一、语料库
1、读入语料库:
import pandas as pd
raw = pd.read_csv(r"C:\Users\Administrator\Desktop\1-8章节python相关资料\金庸-射雕英雄传txt精校版.txt",
names = ['txt'], sep ='aaa', encoding ="GBK")
print(len(raw))
raw
2、加入章节标识:
def m_head(tmpstr):
return tmpstr[:1]
def m_mid(tmpstr):
return tmpstr.find("回 ")
raw['head'] = raw.txt.apply(m_head)
raw['mid'] = raw.txt.apply(m_mid)
raw['len'] = raw.txt.apply(len)
raw.head(50)
3、章节判断:
chapnum = 0
for i in range(len(raw)):
if raw['head'][i] == "第" and raw['mid'][i] > 0 and raw['len'][i] < 30 :
chapnum += 1
if chapnum >= 40 and raw['txt'][i] == "附录一:成吉思汗家族" :
chapnum = 0
raw.loc[i, 'chap'] = chapnum
del raw['head']
del raw['mid']
del raw['len']
raw.head(50)
4、提取所需章节:
raw[raw.chap == 1].head()
#将每一个章节单独整体显示出来:
rawgrp = raw.groupby('chap')
chapter = rawgrp.agg(sum)
chapter = chapter[chapter.index != 0]
chapter.txt[1]

二、分词
1、默认的精确模式:
import jieba
tmpstr = "杨过和哀牢山三十六剑。"
res = jieba.cut(tmpstr)
print(res)
print('/ '.join(res))
res = jieba.cut(tmpstr)
list(word for word in res)
print(jieba.lcut(tmpstr)) # 结果直接输出为list
2、全模式:
print('/'.join(jieba.cut(tmpstr, cut_all = True)))
3、搜索引擎模式:
print('/'.join(jieba.cut_for_search(tmpstr)))
#修改词典(一个一个加):
#增加:
jieba.add_word("哀牢山三十六剑")
'/'.join(jieba.cut(tmpstr))
#删除:
jieba.del_word("哀牢山三十六剑")
'/'.join(jieba.cut(tmpstr))
4、自定义词典:
dict = r'C:\Users\Administrator\Desktop\1-8章节python相关资料\金庸小说词库.txt'
jieba.load_userdict(dict) # dict为自定义词典的路径
'/'.join(jieba.cut(tmpstr))
#搜狗细胞库:
#在程序中导入相应词库:dict = '金庸小说词库.txt'
jieba.load_userdict(dict) # dict为自定义词典的路径
'/'.join(jieba.cut(tmpstr))
# 先分词再去除停用词:
# 直接给出:
newlist = [ w for w in jieba.cut(tmpstr) if w not in ['和', '。'] ]
print(newlist)
#读入外部文件:
import pandas as pd
tmpdf = pd.read_csv(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt',
names = ['w'], sep = 'aaa', encoding = 'utf-8')
tmpdf.head()
[ w for w in jieba.cut(tmpstr) if w not in list(tmpdf.w) ]
#先出去停用词再分词:
import jieba.analyse as ana
ana.set_stop_words(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt')
jieba.lcut(tmpstr)
ana.extract_tags(tmpstr, topK = 20)#(默认去前几个词)
5、词性标注:
import jieba.posseg as psg
tmpres = psg.cut(tmpstr) # 附加词性的分词结果
print(tmpres)
for item in tmpres:
print(item.word, item.flag)#(print出来tmpres的两个属性,字以及对应的属性)
psg.lcut(tmpstr)
psg.lcut(tmpstr)[1].word
三、词云
1、分词:
import jieba
word_list = jieba.lcut(chapter.txt[1])
word_list[:10]
import pandas as pd
df = pd.DataFrame(word_list, columns = ['word'])
df.head(30)
result = df.groupby(['word']).size()
print(type(result))
freqlist = result.sort_values(ascending=False)
freqlist[:20]
2、词频统计:
import nltk
word_list[:10]
fdist = nltk.FreqDist(word_list)
fdist
fdist['颜烈']
fdist.keys()#(所有词列表)
fdist.tabulate(10)#(高频词)
fdist.most_common(5)#(最高的词,以及词频数)
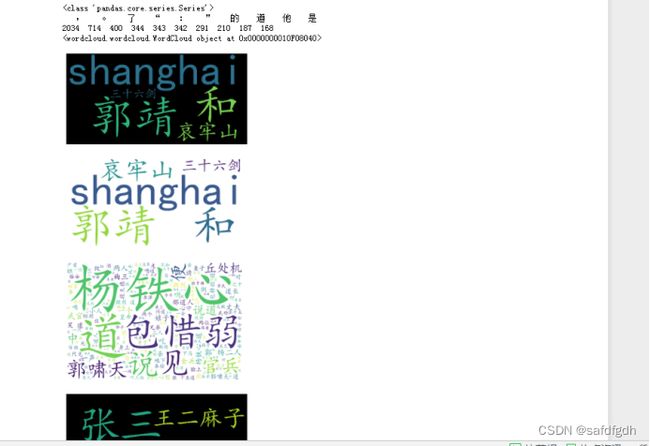
3、绘制词云:
#形成词云但是不显示:
import wordcloud
myfont = r'C:\Windows\Fonts\simkai.ttf'
text = 'this is shanghai, 郭靖, 和, 哀牢山 三十六剑'
cloudobj = wordcloud.WordCloud(font_path = myfont).generate(text)
print(cloudobj)
4、显示词云:
import matplotlib.pyplot as plt
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
5、更改词云参数:
cloudobj = wordcloud.WordCloud(font_path = myfont,
width = 360, height = 180,
mode = "RGBA", background_color = None).generate(text)
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
6、保存图片:
cloudobj.to_file(r"C:\Users\Administrator\Desktop\1-8章节python相关资料\词云.png")
#射雕第一章的词云:
import pandas as pd
import jieba
stoplist = list(pd.read_csv(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt', names = ['w'], sep = 'aaa',
encoding = 'utf-8', engine='python').w)
def m_cut(intxt):
return [ w for w in jieba.cut(intxt) if w not in stoplist ]
cloudobj = wordcloud.WordCloud(font_path = myfont,
width = 1200, height = 800,
mode = "RGBA", background_color = None,
stopwords = stoplist).generate(' '.join(jieba.lcut(chapter.txt[1])))
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
#保存图片:
cloudobj.to_file("词云2.png")
7、基于分词频数绘制:
txt_freq = {'张三':100,'李四':90,'王二麻子':50}
cloudobj = wordcloud.WordCloud(font_path = myfont).fit_words(txt_freq)
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
#用频数生成第一章词云:
import nltk
from nltk import FreqDist
tokens = m_cut(chapter.txt[1])
fdist = FreqDist(tokens) # 生成完整的词条频数字典
type(fdist)
cloudobj = wordcloud.WordCloud(font_path = myfont).fit_words(fdist)
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
8、美化词云:
from imageio import imread
def m_cut(intxt):
return [ w for w in jieba.cut(intxt) if w not in stoplist and len(w) > 1 ]
cloudobj = wordcloud.WordCloud(font_path = myfont,
mask = imread("射雕背景1.png"),
mode = "RGBA", background_color = None
).generate(' '.join(m_cut(chapter.txt[1])))
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
9、制定图片色系:
import numpy as np
imgobj = imread("射雕背景2.png")
image_colors = wordcloud.ImageColorGenerator(np.array(imgobj))
cloudobj.recolor(color_func=image_colors)
plt.imshow(cloudobj)
plt.axis("off")
plt.show()
10、指定单词组颜色:
# 官网提供的颜色分组类代码,略有修改
from wordcloud import get_single_color_func
class GroupedColorFunc(object):
def __init__(self, color_to_words, default_color):
self.color_func_to_words = [
(get_single_color_func(color), set(words))
for (color, words) in color_to_words.items()]
self.default_color_func = get_single_color_func(default_color)
def get_color_func(self, word):
"""Returns a single_color_func associated with the word"""
try:
color_func = next(
color_func for (color_func, words) in self.color_func_to_words
if word in words)
except StopIteration:
color_func = self.default_color_func
return color_func
def __call__(self, word, **kwargs):
return self.get_color_func(word)(word, **kwargs)
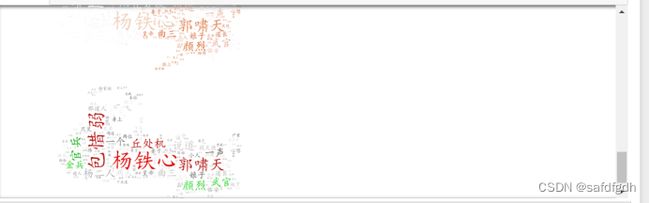
11、指定分组色系:
color_to_words = {
'#00ff00': ['颜烈', '武官', '金兵', '官兵'],
'red': ['包惜弱', '郭啸天', '杨铁心', '丘处机']
}
default_color = 'grey' # 指定其他词条的颜色
grouped_color_func = GroupedColorFunc(color_to_words, default_color)
cloudobj.recolor(color_func=grouped_color_func)
plt.imshow(cloudobj)
plt.axis("off")
plt.show()

四、向量化
chapter.head()
1、设定分词及清理停用词函数
# 熟悉Python的可以使用 open('stopWord.txt').readlines() 获取停用词list,效率更高
stoplist = list(pd.read_csv(r"C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt"))
import jieba
def m_cut(intxt):
return [ w for w in jieba.cut(intxt)
if w not in stoplist and len(w) > 1 ]
2、设定数据框转换函数
def m_appdf(chapnum):
tmpdf = pd.DataFrame(m_cut(chapter.txt[chapnum + 1]), columns = ['word'])
tmpdf['chap'] = chapter.index[chapnum] #其实是将前面程序中的chap取回来,也可以直接 = chapnum + 1
return tmpdf
3、全部读入并转换为数据框
df0 = pd.DataFrame(columns = ['word', 'chap']) # 初始化结果数据框
for i in range(len(chapter)):
df0 = df0.append(m_appdf(i))
df0.tail()
4、输出为序列格式
df0.groupby(['word', 'chap']).agg('size').tail(10)
5、直接输出为数据框
t2d = pd.crosstab(df0.word, df0.chap)
len(t2d)
6、计算各词条的总出现频次,准备进行低频词删减
totnum = t2d.agg(func = 'sum', axis=1)
t2dclean = t2d.iloc[list(totnum >= 10)]
t2dclean.T
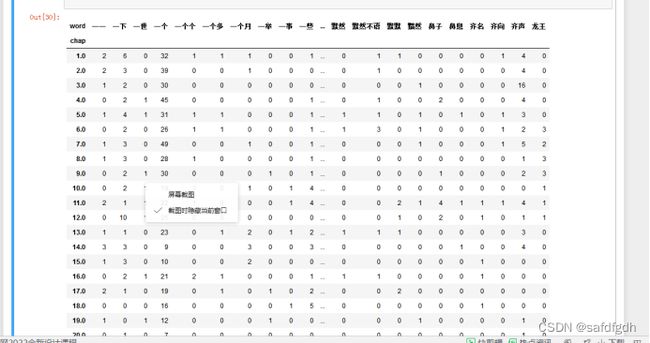
五、关键词提取
1、Jieba关键词的提取
import jieba
import jieba.analyse
# 注意:函数是在使用默认的TFIDF模型进行分析!
jieba.analyse.extract_tags(chapter.txt[1])
jieba.analyse.extract_tags(chapter.txt[1], withWeight = True)
2、应用自定义词典改善分词效果
jieba.load_userdict(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\金庸小说词库.txt')
jieba.analyse.set_stop_words(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt')
TFres = jieba.analyse.extract_tags(chapter.txt[1], withWeight = True)
TFres[:10]
3、使用自定义TF-IDF频率文件
jieba.analyse.set_idf_path(r"C:\Users\Administrator\Desktop\1-8章节python相关资料\idf.txt.big")
TFres1 = jieba.analyse.extract_tags(chapter.txt[1], withWeight = True)
TFres1[:10]
4、Sklearn关键词的提取
from sklearn.feature_extraction.text import TfidfTransformer,CountVectorizer
txtlist = [ " ".join(m_cut(w)) for w in chapter.txt.iloc[:5]]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(txtlist) # 将文本中的词语转换为词频矩阵
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X) #基于词频矩阵X计算TF-IDF值
tfidf
tfidf.toarray() # 转换为数组
tfidf.todense() # 转换为矩阵
tfidf.todense().shape
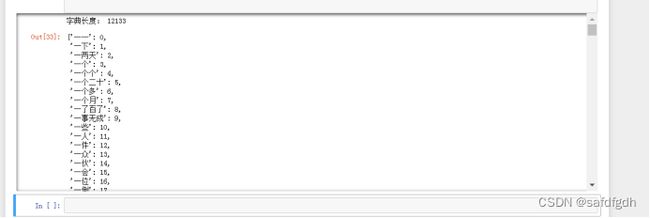
print("字典长度:", len(vectorizer.vocabulary_))
vectorizer.vocabulary_
chaplist = [m_cut(w) for w in chapter.txt.iloc[:5]]
chaplist
5、Genism关键词的提取
from gensim import corpora, models
# 生成文档对应的字典和bow稀疏向量
dictionary = corpora.Dictionary(chaplist)
corpus = [dictionary.doc2bow(text) for text in chaplist] # 仍为list in list
corpus
tfidf_model = models.TfidfModel(corpus) # 建立TF-IDF模型
corpus_tfidf = tfidf_model[corpus] # 对所需文档计算TF-IDF结果
corpus_tfidf
tfidf_model = models.TfidfModel(corpus) # 建立TF-IDF模型
corpus_tfidf = tfidf_model[corpus] # 对所需文档计算TF-IDF结果
corpus_tfidf
corpus_tfidf[3] # 列出所需文档的TF-IDF计算结果
dictionary.token2id # 列出字典内容
六、主题词提取
1、Sklearn主题提取方式:
# 设定分词及清理停用词函数
# 熟悉Python的可以使用 open('stopWord.txt').readlines() 获取停用词list,效率更高
stoplist = list(pd.read_csv(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt', names = ['w'], sep = 'aaa',
encoding = 'utf-8', engine='python').w)
import jieba
def m_cut(intxt):
return [ w for w in jieba.cut(intxt)
if w not in stoplist and len(w) > 1 ]
# 生成分词清理后章节文本
cleanchap = [ " ".join(m_cut(w)) for w in chapter.txt]
# 将文本中的词语转换为词频矩阵
from sklearn.feature_extraction.text import CountVectorizer
countvec = CountVectorizer(min_df = 5)
wordmtx = countvec.fit_transform(cleanchap)
wordmtx
#基于词频矩阵X计算TF-IDF值
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(wordmtx)
tfidf
# 设定LDA模型
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 10
ldamodel = LatentDirichletAllocation(n_components = n_topics)
# 拟合LDA模型,注意这里使用的是原始wordmtx矩阵
ldamodel.fit(wordmtx)
# 拟合后模型的实质
print(ldamodel.components_.shape)
ldamodel.components_[:2]
# 主题词打印函数
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
n_top_words = 12
tf_feature_names = countvec.get_feature_names()
print_top_words(ldamodel, tf_feature_names, n_top_words)
2、genism实现方法:
# 设定分词及清理停用词函数
# 熟悉Python的可以使用 open('stopWord.txt').readlines()获取停用词list,效率更高
stoplist = list(pd.read_csv(r'C:\Users\Administrator\Desktop\1-8章节python相关资料\停用词.txt', names = ['w'], sep = 'aaa',
encoding = 'utf-8', engine='python').w)
import jieba
def m_cut(intxt):
return [ w for w in jieba.cut(intxt)
if w not in stoplist and len(w) > 1 ]
# 文档预处理,提取主题词
chaplist = [m_cut(w) for w in chapter.txt]
# 生成文档对应的字典和bow稀疏向量
from gensim import corpora, models
dictionary = corpora.Dictionary(chaplist)
corpus = [dictionary.doc2bow(text) for text in chaplist] # 仍为list in list
tfidf_model = models.TfidfModel(corpus) # 建立TF-IDF模型
corpus_tfidf = tfidf_model[corpus] # 对所需文档计算TF-IDF结果
corpus_tfidf
from gensim.models.ldamodel import LdaModel
# 列出所消耗的时间备查
%time ldamodel1 = LdaModel(corpus, id2word = dictionary, \
num_topics = 10, passes = 2)
ldamodel1.print_topics()
# 计算各语料的LDA模型值
corpus_lda = ldamodel1[corpus_tfidf] # 此处应当使用和模型训练时相同类型的矩阵
for doc in corpus_lda:
print(doc)
ldamodel1.get_topics()
# 检索和文本内容最接近的主题
query = chapter.txt[1] # 检索和第1章最接近的主题
query_bow = dictionary.doc2bow(m_cut(query)) # 频数向量
query_tfidf = tfidf_model[query_bow] # TF-IDF向量
print("转换后:", query_tfidf[:10])
ldamodel1.get_document_topics(query_bow) # 需要输入和文档对应的bow向量
# 检索和文本内容最接近的主题
ldamodel1[query_tfidf]
3、主题模型的可视化:
#Sklearn实现:
# 对sklearn的LDA结果作呈现
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(ldamodel, wordmtx, countvec)
#Genism实现:
# 对gensim的LDA结果作呈现
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
pyLDAvis.gensim.prepare(ldamodel1, corpus, dictionary)
pyLDAvis.disable_notebook() # 关闭notebook支持后,可以看到背后所生成的数据