知识图谱之nlp端到端实体-关系抽取最强综述
知识图谱之nlp端到端实体-关系抽取最强综述
主要分类方法
根据模型结构特点:
1、基于解码机制(decoder-based):通过编解码机制依次,其中解码器一次像机器翻译模型一样依次提取一种关系、提取一个单词、一个元组
2、基于分解机制(decomposition-based):基于分解的模型首先识别与目标关系有关的所有候选实体主语,然后为每个提取的主语对应的对象谓语实体和关系
根据不同阶段数:
1、两阶段关系抽取
2、单阶段关系抽取
根据不同标注方案:
1、序列标注–A Relation-Specific Attention Network for Joint Entity and Relation Extraction
2、指针标注–Extracting relational facts by an end-to-end neural model with copy mechanisman
根据不同抽取顺序:
1、先实体,后关系–Span-based Joint Entity and Relation Extraction with Transformer Pre-training
2、先主语,后关系谓语–A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
3、先关系,后实体–A Relation-Specific Attention Network for Joint Entity and Relation Extraction
4、先关系,后主语,最后谓语–Extracting relational facts by an end-to-end neural model with copy mechanism
主要考虑问题
1、**实体重叠:**单实体重叠(SingleEntityOverlap),实体对重叠(EntityPairOverlap)以及部分实体重叠(PartialEntityOverlap)【很多论文】
2、**交互缺失:**忽略了关系抽取和实体抽取的内在联系,导致出现单实体抽取准确率较高,但实体对的准确率低的问题
3、**暴露偏差:**主要因为训练阶段和推理阶段的差异导致,在训练阶段使用真实的实体片段标签作为输入,而在推理阶段实体片段通过模型预测产生,并作为上下文信息输入到模型,导致训练和推理阶段的输入数据分布偏差,出现误差积累现象
4、**重复编码:**往往需要重复的输入实体或者实体对及其上下文信息进行重复的解码,降低了预测模型的推理速度,主要解决方法通过共享高层语义特征
两阶段关系抽取two-stage method
先抽取主语,后抽取宾语和关系–A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
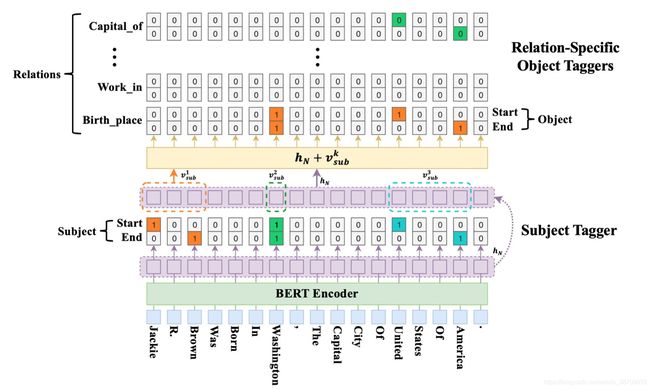
考虑问题:
1、**实体重叠:**通过解耦关系,使得实体关系互相独立,通过指针标注方案判断每种关系条件下实体对的起止位置,但采用最近起止对解码方式无法解决同种关系条件,部分实体重叠导致的配对问题
2、交互缺失:使用层叠指针标注,采用最近start-end对解码机制实体对克服单实体重叠和实体对重叠问题,但最近start-end对解码机制无法解决部分实体重叠问题
先实体,后关系–Span-based Joint Entity and Relation Extraction with Transformer Pre-training
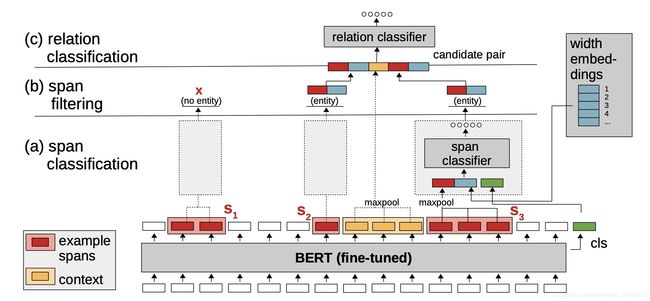
考虑问题:
1、**实体重叠:**列举句子中所有可能的实体片段,并通过限制片段的最大长度降低实体分类带来的时间消耗,可以解决了部分实体重叠的问题,并使用width embedding片段位置信息和classifier token全局上下文表征提高模型精度
先关系,后主语,最后谓语-Extracting relational facts by an end-to-end neural model with copy mechanism
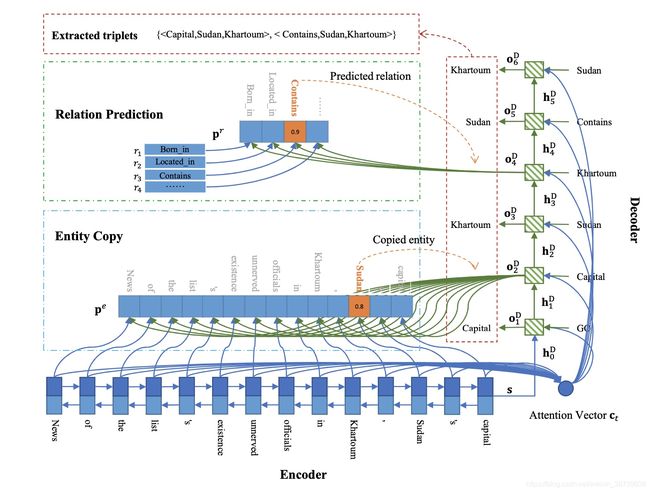
考虑问题:
1、**实体重叠:**采用机器翻译的编解码方式,依次获得所有的关系,主语,谓语
存在问题:
1、交互缺失:只通过机器翻译的方式简单有序的获取所有的关系,主语,谓语,模型没有考虑在关系与词语在细粒度语义上的关联关系
存在的问题
两阶段实体关系抽取由于训练和推断的差异,导致以下几个问题:
1、暴露偏差:由于在训练过程,虽然采用端到端训练方式,而实际上模型内部依然存在级联任务,本质上不是因为刚刚开始模型的初级任务的训练结果精度低的无法作为输入(与机器翻译的teacher forcing略有差异),而是上游任务输出端与下游任务的输入端分布偏差导致的末端标签中断,我这里姑且称为【级联中断】,使得多级任务之间在训练过程中均采用真实标签作为输入,而在推断阶段上游任务输出端作为下游任务的输入端所导致的分布偏差将带来误差积累
单阶段关系抽取( 联合解码)one-stage method(joint decoding)
序列标注方案–Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
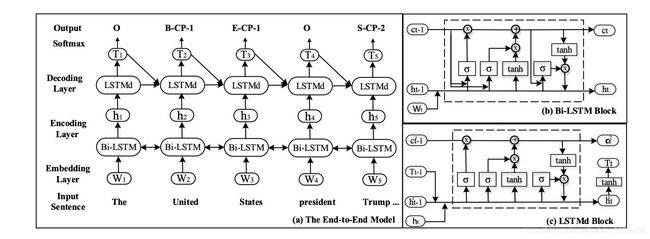
考虑问题:
2、**交互缺失:**使用序列标注方案,考虑到CopyRE and HRL模型在实体和关系语义特征关联性太差,容易造成重复解码等问题,该论文利用固定个数和不同关系类别细粒度语义表征以及attention机制指导实体识别过程,避免了不相关的冗余实体抽取,并引入关系门控机制以及关系负采样策略加快模型收敛
3、**暴露偏差:**通过具体化实体关系的方式抽取对应的实体对,避免多级任务带来的偏差
存在问题:
1、**实体重叠:**采用BIO加relationship序列标注方案,很明显由于每个实体只能对应一个标签,无法解决实体重叠问题
多头序列标注方案–A Relation-Specific Attention Network for Joint Entity and Relation Extraction
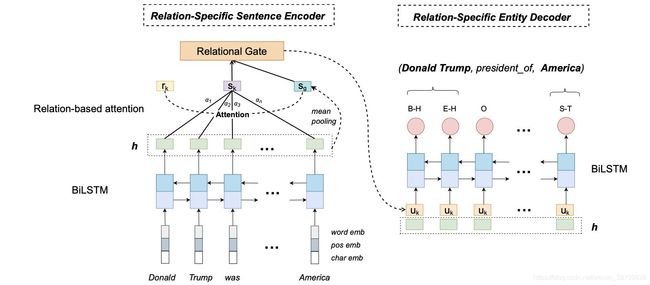
考虑问题:
1、**实体重叠:**也是通过解耦关系,使得实体关系的预测互相独立,采用BIO序列标注方案判断每种关系条件下实体对的起止位置,由于不同关系条件下,系列对应不同的标签,有效的解决了单实体和实体对关系重叠问题
2、**交互缺失:**使用序列标注方案,考虑到CopyRE and HRL模型在实体和关系语义特征关联性太差,容易造成重复解码等问题,该论文利用固定个数和不同关系类别细粒度语义表征以及attention机制指导实体识别过程,避免了不相关的冗余实体抽取,并引入关系门控机制以及关系负采样策略加快模型收敛
3、**暴露偏差:**通过具体化实体关系的方式,抽取对应关系的实体对,避免多级任务带来分布偏差和级联中断
存在问题:
1、实体重叠:很明显由于每个实体只能对应一个标签,依然无法解决同种关系条件下部分实体重叠的问题,以及实体关系交替问题
多头指针标注方案–TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
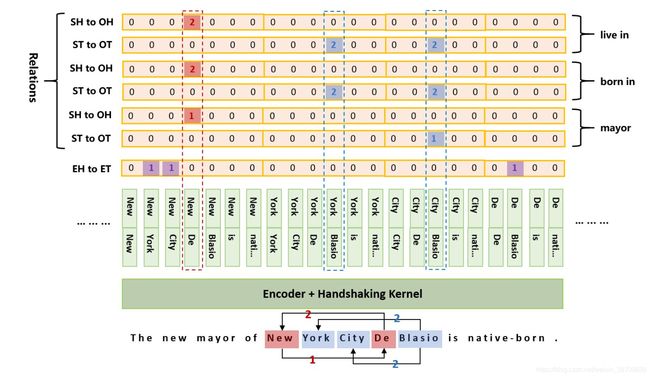
考虑问题:
1、**实体重叠:**通过多头指针标签方案解耦关系、实体、关系和实体的起止位置,采用联合解码的方式,通过n*n的矩阵同时标记实体的起止位置,完美解决了单实体重叠,实体对重叠和部分实体重叠的问题
2、**交互缺失:**通过联合编解码,并在不同关系下,关联主语和谓语的起止位置有效让模型更好的学习到【关系相关实体】,和【实体相关关系】
3、**暴露偏差:**不存在多级训练任务带来的分布偏差,也就自然而然解决了暴露偏差
总结
本文主要从单阶段和两阶段关系抽取进行部分代表性论文的解读和分析,剖析了不同关系抽取模型主要考虑的问题和依然存在的缺陷,部分表述可能不够精准,仅供参考
更多内容参考:本人知乎专栏