【机器学习】支持向量机【下】软间隔与核函数
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
在阅读本篇之前建议先学习:
【机器学习】拉格朗日对偶性
【机器学习】核函数
由于字数限制,分成两篇博客。
【机器学习】支持向量机【上】硬间隔
【机器学习】支持向量机【下】软间隔与核函数
线性支持向量机
软间隔最大化
在实际中,线性可分属于比较理想的情况,大多数数据都是线性不可分的,这时可以修改硬间隔最大化,使其成为软间隔最大化,来处理线性不可分问题。这里所谓的“线性不可分”是指,训练数据中有一些特异点(outlier),将这些特异点除去后,剩下大部分的样本点组成的集合是线性可分的。
线性不可分意味着某些样本点 ( x i , y i ) (x_i,y_i) (xi,yi) 不能满足约束条件 y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\ge 1 yi(wTxi+b)≥1。为了解决这个问题,可以对每个样本点 ( x i , y i ) (x_i,y_i) (xi,yi) 引进一个松弛变量 ξ ≥ 0 \xi\ge 0 ξ≥0,使约束条件变为
y i ( w T x i + b ) ≥ 1 − ξ i y_i(w^Tx_i+b)\ge 1-\xi_i yi(wTxi+b)≥1−ξi
对每一个松弛变量 ξ i \xi_i ξi,支付一个代价 ξ i \xi_i ξi。目标函数由原来的 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2} ||w||^2 21∣∣w∣∣2 变为
1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i (9) \frac{1}{2} ||w||^2 + C\sum_{i=1}^n \xi_i \tag{9} 21∣∣w∣∣2+Ci=1∑nξi(9)
其中, C > 0 C>0 C>0 称为惩罚(超)参数,一般根据应用问题人为决定, C C C 值越大对误分类的惩罚越大。最小化目标函数式 ( 9 ) (9) (9) 包含两层含义:使 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2 尽量小即间隔尽量大,同时使误分类点的个数尽量少, C C C 是调和二者的系数。
基于上面允许误分类的思想,对于线性不可分的支持向量机学习问题,我们可以采用与线性可分时类似的学习过程。
定义原始问题:
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i , i = 1 , 2 , … , n ξ i ≥ 0 , i = 1 , 2 , … , n (10) \begin{matrix} &\min_{w,b,\xi} \frac{1}{2} ||w||^2 + C\sum_{i=1}^n\xi_i& \\\\ s.t.&y_i(w^Tx_i+b)\ge 1-\xi_i,& i=1,2,\dots,n \\ &\xi_i\ge0,& i=1,2,\dots,n \\ \end{matrix} \tag{10} s.t.minw,b,ξ21∣∣w∣∣2+C∑i=1nξiyi(wTxi+b)≥1−ξi,ξi≥0,i=1,2,…,ni=1,2,…,n(10)
原始问题式 ( 10 ) (10) (10) 是一个凸二次规划问题,因而关于 ( w , b , ξ ) (w,b,\xi) (w,b,ξ) 的最优解是存在的。而且 w w w 的最优解是唯一的,但 b b b 的最优解可能不唯一,而是存在于一个区间。假设最优解为 w ∗ w^* w∗ 和 b ∗ b^* b∗,于是可以得到划分超平面 w ∗ T x + b ∗ = 0 {w^*}^Tx+b^*=0 w∗Tx+b∗=0 及分类决策函数 f ( x ) = s i g n ( w ∗ T x + b ∗ ) f(x)={\rm sign}({w^*}^Tx+b^*) f(x)=sign(w∗Tx+b∗)。称这样的模型为训练样本线性不可分时的线性支持向量机,简称为线性支持向量机。
对偶问题
构建广义拉格朗日函数
L ( w , b , ξ , α , β ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i − ∑ i = 1 n α i ( y i ( w T x i + b ) − 1 + ξ i ) − ∑ i = 1 n β i ξ i L(w, b, \xi,\alpha,\beta) = \frac{1}{2} ||w||^2 + C\sum_{i=1}^n \xi_i -\sum_{i=1}^n \alpha_i \big(y_i(w^Tx_i+b)-1+\xi_i\big) - \sum_{i=1}^n\beta_i\xi_i L(w,b,ξ,α,β)=21∣∣w∣∣2+Ci=1∑nξi−i=1∑nαi(yi(wTxi+b)−1+ξi)−i=1∑nβiξi
其中,拉格朗日乘子 α i ≥ 0 \alpha_i\ge 0 αi≥0, β i ≥ 0 \beta_i\ge 0 βi≥0。
首先求 L ( w , b , ξ , α , β ) L(w,b,\xi,\alpha,\beta) L(w,b,ξ,α,β) 对 w w w, b b b 和 ξ \xi ξ 的极小,由
∇ w L ( w , b , ξ , α , β ) = w − ∑ i = 1 n α i y i x i = 0 ∇ b L ( w , b , ξ , α , β ) = − ∑ i = 1 n α i y i = 0 ∇ ξ i L ( w , b , ξ , α , β ) = C − α i − β i = 0 \nabla_w L(w,b,\xi, \alpha,\beta) = w - \sum_{i=1}^n \alpha_iy_ix_i=0\\ \nabla_b L(w,b,\xi, \alpha,\beta) = - \sum_{i=1}^n \alpha_iy_i=0\\ \nabla_{\xi_i} L(w,b,\xi, \alpha,\beta) = C - \alpha_i - \beta_i=0\\ ∇wL(w,b,ξ,α,β)=w−i=1∑nαiyixi=0∇bL(w,b,ξ,α,β)=−i=1∑nαiyi=0∇ξiL(w,b,ξ,α,β)=C−αi−βi=0
可得
w = ∑ i = 1 n α i y i x i (11) w = \sum_{i=1}^n \alpha_i y_i x_i\tag{11} w=i=1∑nαiyixi(11)
∑ i = 1 n α i y i = 0 (12) \sum_{i=1}^n \alpha_i y_i=0\tag{12} i=1∑nαiyi=0(12)
C − α i − β i = 0 (13) C - \alpha_i - \beta_i = 0\tag{13} C−αi−βi=0(13)
将式 ( 11 ) ∼ ( 13 ) (11)\sim(13) (11)∼(13) 代入拉格朗日函数中得
min w , b , ξ L ( w , b , ξ , α , β ) = − 1 2 ∑ i = 1 n ∑ i = 1 n α i α j y u y j ( x i T x j ) + ∑ i = 1 n α i \min_{w,b, \xi} L(w, b, \xi,\alpha, \beta) = -\frac{1}{2} \sum_{i=1}^n\sum_{i=1}^n\alpha_i\alpha_jy_uy_j(x_i^Tx_j)+\sum_{i=1}^n\alpha_i w,b,ξminL(w,b,ξ,α,β)=−21i=1∑ni=1∑nαiαjyuyj(xiTxj)+i=1∑nαi
再对 min w , b , ξ L ( w , b , ξ , α , β ) \min\limits_{w,b, \xi} L(w, b, \xi,\alpha, \beta) w,b,ξminL(w,b,ξ,α,β) 求 α \alpha α 和 β \beta β 的极大。显然这已经与 β \beta β 无关,得到对偶问题:
max α − 1 2 ∑ i = 1 n ∑ i = 1 n α i α j y u y j ( x i T x j ) + ∑ i = 1 n α i s . t . ∑ i = 1 n α i y i = 0 C − α i − β i = 0 α i ≥ 0 β i ≥ 0 , i = 1 , 2 , … , n (14) \begin{array}{ll} \max\limits_\alpha & -\frac{1}{2} \sum\limits_{i=1}^n\sum\limits_{i=1}^n\alpha_i\alpha_jy_uy_j(x_i^Tx_j)+\sum\limits_{i=1}^n\alpha_i \\ \\ s.t.& \sum \limits_{i=1}^n\alpha_iy_i = 0\\ &C-\alpha_i - \beta_i = 0 \\ &\alpha_i\ge 0\\ &\beta_i\ge 0,\space\space\space\space i=1,2,\dots, n \end{array} \tag{14} αmaxs.t.−21i=1∑ni=1∑nαiαjyuyj(xiTxj)+i=1∑nαii=1∑nαiyi=0C−αi−βi=0αi≥0βi≥0, i=1,2,…,n(14)
对对偶问题式 ( 14 ) (14) (14) 进行变形:利用等式约束 C − α i − β i = 0 C-\alpha_i-\beta_i=0 C−αi−βi=0 消去 β i \beta_i βi,从而只留下变量 α i \alpha_i αi,并将后三条约束共同表达为
0 ≤ α i ≤ C 0\le \alpha_i\le C 0≤αi≤C
最终将问题从求极大转化为求极小,得
min α 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y u y j ( x i T x j ) − ∑ i = 1 n α i s . t . ∑ i = 1 n α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , … , n (15) \begin{matrix} &\min\limits_\alpha \frac{1}{2} \sum\limits_{i=1}^n\sum\limits_{j=1}^n\alpha_i\alpha_jy_uy_j(x_i^Tx_j)-\sum\limits_{i=1}^n\alpha_i \\ \\ s.t.& \sum_{i=1}^n \alpha_iy_i = 0 \\ & 0\le \alpha_i\le C,\space\space\space\space i=1,2,\dots,n \\ \end{matrix} \tag{15} s.t.αmin21i=1∑nj=1∑nαiαjyuyj(xiTxj)−i=1∑nαi∑i=1nαiyi=00≤αi≤C, i=1,2,…,n(15)
由于问题具有强对偶性,所以 KKT 条件成立,即得
y i ( w ∗ T x i + b ∗ ) − 1 + ξ i ∗ ≥ 0 ξ i ∗ ≥ 0 y_i({w^*}^Tx_i+b^*)-1+\xi_i^* \ge 0\\\\ \xi_i^*\ge0\\ yi(w∗Txi+b∗)−1+ξi∗≥0ξi∗≥0
∇ w L ( w ∗ , b ∗ , ξ ∗ , α ∗ , β ∗ ) = w ∗ − ∑ i = 1 n α i ∗ y i x i = 0 (16) \nabla_w L(w^*,b^*,\xi^*, \alpha^*,\beta^*) = w^* - \sum_{i=1}^n \alpha_i^*y_ix_i=0\tag{16} \\ ∇wL(w∗,b∗,ξ∗,α∗,β∗)=w∗−i=1∑nαi∗yixi=0(16)
∇ b L ( w ∗ , b ∗ , ξ ∗ , α ∗ , β ∗ ) = − ∑ i = 1 n α i ∗ y i = 0 \nabla_b L(w^*,b^*,\xi^*, \alpha^*,\beta^*) = - \sum_{i=1}^n \alpha_i^*y_i=0 ∇bL(w∗,b∗,ξ∗,α∗,β∗)=−i=1∑nαi∗yi=0
∇ ξ L ( w ∗ , b ∗ , ξ ∗ , α ∗ , β ∗ ) = C − α ∗ − β ∗ = 0 (17) \nabla_{\xi} L(w^*,b^*,\xi^*, \alpha^*,\beta^*) = C - \alpha^* - \beta^*=0 \tag{17} ∇ξL(w∗,b∗,ξ∗,α∗,β∗)=C−α∗−β∗=0(17)
α i ∗ ≥ 0 β i ∗ ≥ 0 \alpha_i^*\ge 0\\\\ \beta_i^*\ge 0 αi∗≥0βi∗≥0
α i ∗ ( y i ( w ∗ T x i + b ∗ ) − 1 + ξ i ∗ ) = 0 (18) \alpha_i^*\big( y_i({w^*}^Tx_i+b^*)-1+\xi_i^* \big) = 0\tag{18} αi∗(yi(w∗Txi+b∗)−1+ξi∗)=0(18)
β i ∗ ξ i ∗ = 0 (19) \beta^*_i\xi_i^*=0\tag{19} βi∗ξi∗=0(19)
由式 ( 16 ) (16) (16) 可知
w ∗ = ∑ i = 1 n α i ∗ y i x i (20) w^* = \sum_{i=1}^n \alpha_i^*y_ix_i \tag{20} w∗=i=1∑nαi∗yixi(20)
若存在 α j ∗ \alpha_j^* αj∗, 0 < α j ∗ < C 0<\alpha_j^*
b ∗ = y j − ∑ i = 1 n y i α i ∗ ( x i T x j ) (21) b^* = y_j - \sum_{i=1}^n y_i\alpha_i^*(x_i^Tx_j)\tag{21} b∗=yj−i=1∑nyiαi∗(xiTxj)(21)
由此,划分超平面可以写为
∑ i = 1 n α i ∗ y i ( x i T x ) + b ∗ = 0 \sum_{i=1}^n \alpha_i^*y_i(x_i^Tx)+b^*=0 i=1∑nαi∗yi(xiTx)+b∗=0
分类决策函数可以写为
f ( x ) = s i g n ( ∑ i = 1 n α i ∗ y i ( x i T x ) + b ∗ ) f(x) ={\rm sign}\Big( \sum_{i=1}^n \alpha_i^*y_i(x_i^Tx)+b^* \Big) f(x)=sign(i=1∑nαi∗yi(xiTx)+b∗)
上式称为线性支持向量机的对偶形式。线性支持向量机学习算法如下。
输入: 训 练 集 D = { ( x 1 , y 1 ) , ⋅ ⋅ ⋅ , ( x n , y n ) } , 其 中 x i ∈ R d , y i ∈ { + 1 , − 1 } , i = 1 , … , n 过程: \begin{array}{ll} \textbf{输入:}&\space训练集\space D = \{(x_1,y_1),···,(x_n,y_n)\},\space 其中\space x_i\in \mathbb R^{d},\space y_i\in \{+1,-1\},\space i=1,\dots,n \\ \textbf{过程:} \end{array} 输入:过程: 训练集 D={(x1,y1),⋅⋅⋅,(xn,yn)}, 其中 xi∈Rd, yi∈{+1,−1}, i=1,…,n
1 : 选 择 惩 罚 参 数 C > 0 , 构 造 并 求 解 凸 二 次 规 划 问 题 min α 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j ( x i T x j ) − ∑ i = 1 n α i s . t . ∑ i = 1 n α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , … , n 求 得 最 优 解 α ∗ = { α i ∗ } , i = 1 , 2 , … , n 2 : 计 算 w ∗ = ∑ i = 1 n α i ∗ y i x i 3 : 选 择 0 < α j ∗ < C , 计 算 b ∗ = y j − ∑ i = 1 n α i ∗ y i ( x i T x j ) 4 : 求 得 划 分 超 平 面 w ∗ T x + b ∗ = 0 分 类 决 策 函 数 f ( x ) = s i g n ( w ∗ T x + b ∗ ) \begin{array}{rl} 1:& 选择惩罚参数 \space C>0,构造并求解凸二次规划问题\\ \\ &\begin{array}{c} & \min \limits_\alpha \frac{1}{2}\sum \limits_{i=1}^n\sum \limits_{j=1}^n \alpha_i\alpha_jy_iy_j(x_i^Tx_j) -\sum \limits_{i=1}^n \alpha_i &\\ &s.t.\space\space\space\space \sum\limits_{i=1}^n \alpha_iy_i = 0 \\ &0\le\alpha_i\le C,\space\space\space\space i=1,2,\dots, n \\\\ \end{array}\\ & 求得最优解 \space \alpha^* = \{\alpha_i^*\},\space i=1,2,\dots,n \\ 2:& 计算\\ \\ &\begin{array}{c} &&w^* = \sum \limits_{i=1}^n \alpha_i^*y_ix_i \end{array}\\\\ 3:& 选择 \space 0<\alpha_j^*
输出: 划 分 超 平 面 和 分 类 决 策 函 数 \begin{array}{l} \textbf{输出:}\space 划分超平面和分类决策函数 &&&&&&&&&&&&&&&&&& \end{array} 输出: 划分超平面和分类决策函数
算法 2 线性支持向量机学习算法
支持向量
在线性不可分的情况下,将对偶问题式 ( 15 ) (15) (15) 的解 α ∗ = { α i ∗ } α^*=\{\alpha_i^*\} α∗={αi∗} 中对应于 α i ∗ > 0 α_i^* > 0 αi∗>0 的样本点 ( x i , y j ) (x_i, y_j) (xi,yj) 的实例 x i x_i xi 称为支持向量(软间隔的支持向量)。如图 3 3 3 所示,这时的支持向量要比线性可分时的情况复杂一些。图中,划分超平面由实线表示,间隔边界由虚线表示,正样本由“o”表示,负样本由“×”表示。图中还标出了样本 x i x_i xi 到间隔边界的距离 ξ i ∣ ∣ w ∣ ∣ \frac{\xi_i}{||w||} ∣∣w∣∣ξi 。
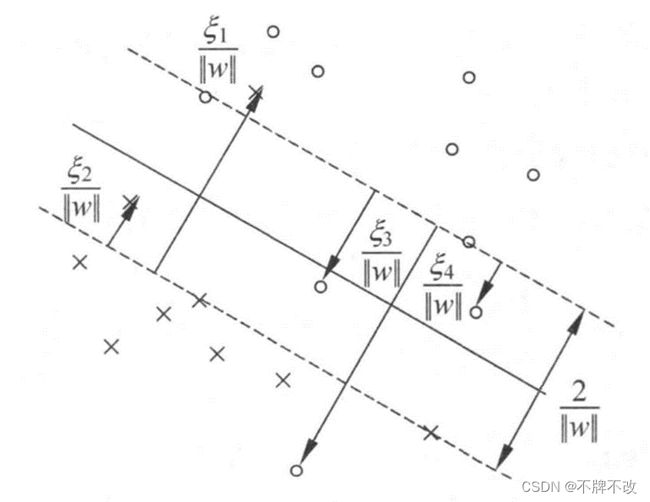
图 3 软间隔的支持向量
软间隔的支持向量 x i x_i xi 或者在间隔边界上,或者在间隔边界与划分超平面之间,或者在划分超平面误分一侧。由式 ( 17 ) (17) (17) 和 ( 19 ) (19) (19) 可得,若 α i ∗ < C α_i^*
合页损失函数
还可以从另一个角度解释线性支持向量机学习。定义损失函数为划分错误的样本个数,即
J ( w , b ) = ∑ i = 1 n 1 { y i ( w T x i + b ) < 1 } J(w,b) = \sum_{i=1}^n1\{y_i(w^Tx_i+b)<1\} J(w,b)=i=1∑n1{yi(wTxi+b)<1}
其中, 1 { ⋅ } 1\{·\} 1{⋅} 的作用类似于艾弗森括号,即括号内为真返回 1 1 1,否则返回 0 0 0。显然,函数 J J J 非连续,且存在跳跃,数学性质不好,不便于求导。故将损失函数 J J J 重新定义
J ( w , b ) = ∑ i = 1 n [ 1 − y i ( w T x i + b ) ] + J(w,b) = \sum_{i=1}^n[1-y_i(w^Tx_i+b)]_+ J(w,b)=i=1∑n[1−yi(wTxi+b)]+
其中,函数 [ z ] + [z]_+ [z]+ 为合页函数(hinge function)
[ z ] + = { z , z > 0 0 , z ≤ 0 [z]_+ = \left\{ \begin{matrix} z,&z>0\\ 0,&z\le 0 \end{matrix} \right. [z]+={z,0,z>0z≤0
也可以等价表示为
[ z ] + = max ( 0 , z ) [z]_+ = \max(0, z) [z]+=max(0,z)
函数 J J J 加上正则化项后定义为最终损失函数 L L L
L ( w , b ) = J ( w , b ) + λ ∣ ∣ w ∣ ∣ 2 = ∑ i = 1 n [ 1 − y i ( w T x i + b ) ] + + λ ∣ ∣ w ∣ ∣ 2 \begin{aligned} L(w,b) &= J(w,b) + \lambda ||w||^2 \\ &= \sum_{i=1}^n[1-y_i(w^Tx_i+b)]_+ + \lambda ||w||^2 \end{aligned} L(w,b)=J(w,b)+λ∣∣w∣∣2=i=1∑n[1−yi(wTxi+b)]++λ∣∣w∣∣2
因此我们的优化目标为
min w , b ∑ i = 1 n [ 1 − y i ( w T x i + b ) ] + + λ ∣ ∣ w ∣ ∣ 2 (22) \min_{w,b} \sum_{i=1}^n[1-y_i(w^Tx_i+b)]_+ + \lambda ||w||^2 \tag{22} w,bmini=1∑n[1−yi(wTxi+b)]++λ∣∣w∣∣2(22)
观察损失函数 L L L,当样本点 ( x i , y i ) (x_i ,y_i) (xi,yi) 被正确分类且确信度 y i ( w T x i + b ) y_i(w^T x_i+b) yi(wTxi+b) 大于 1 1 1 时,损失为 0 0 0,否则损失为 1 − y i ( w T x i + b ) 1-y_i(w^T x_i+b) 1−yi(wTxi+b)。注意到图 3 3 3 中的样本点 x 4 x_4 x4 被正确分类,但损失不是 0 0 0。损失函数的第二项是系数为 λ \lambda λ 的 w w w 的 L 2 L_2 L2 范数,是正则化项。
可以很容易证明优化问题 ( 22 ) (22) (22) 与原始问题 ( 10 ) (10) (10) 等价。令
[ 1 − y i ( w T x i + b ) ] + = ξ i [1-y_i(w^Tx_i+b)]_+ = \xi_i [1−yi(wTxi+b)]+=ξi
则 ξ i ≥ 0 \xi_i\ge0 ξi≥0,式 ( 10 ) (10) (10) 中的第二个不等式约束成立。由上式,当 1 − y i ( w T x i + b ) > 0 1-y_i(w^Tx_i+b)>0 1−yi(wTxi+b)>0 时,有 y i ( w T x i + b ) = 1 − ξ i y_i(w^Tx_i+b)=1-\xi_i yi(wTxi+b)=1−ξi;当 1 − y i ( w T x i + b ) ≤ 0 1-y_i(w^Tx_i+b)\le 0 1−yi(wTxi+b)≤0 时, ξ i = 0 \xi_i=0 ξi=0,有 y i ( w T x i + b ) ≥ 1 − ξ i y_i(w^Tx_i+b)\ge 1-\xi_i yi(wTxi+b)≥1−ξi。故式 ( 10 ) (10) (10) 中的第一个不等式约束成立。于是 w w w, b b b 和 ξ i \xi_i ξi 满足式 ( 10 ) (10) (10) 的约束条件,所以最优化问题 ( 22 ) (22) (22) 可以写成
min w , b ∑ i = 1 n ξ i + λ ∣ ∣ w ∣ ∣ 2 \min_{w,b} \sum_{i=1}^n \xi_i + \lambda||w||^2 w,bmini=1∑nξi+λ∣∣w∣∣2
若取 λ = 1 2 C \lambda=\frac{1}{2C} λ=2C1,则
min w , b 1 C ( 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i ) \min_{w,b}\frac{1}{C} \Big(\frac{1}{2} ||w||^2 + C\sum_{i=1}^n\xi_i \Big) w,bminC1(21∣∣w∣∣2+Ci=1∑nξi)
与原始问题 ( 10 ) (10) (10) 等价。反之,也可以将优化问题 ( 22 ) (22) (22) 表示成问题 ( 10 ) (10) (10)。
合页损失函数 L ( y ( x T x + b ) ) L\big(y(x^Tx+b)\big) L(y(xTx+b)) 的图形如图 4 4 4 所示,横轴为 y ( w T x + b ) y(w^Tx+b) y(wTx+b),纵轴为损失。由于函数形状像一个合页,故名合页损失函数。图中还画出了出 01 01 01 损失函数,可以认为它是二类分类问题的真正的损失函数,而合页损失函数是 0 ~ 1 0\text{\textasciitilde}1 0~1 损失函数的上界。由于 0 ~ 1 0\text{\textasciitilde}1 0~1 损失函数是跳跃的,不利于求导,直接优化由其构成的目标函数比较困难,可以认为线性支持向量机是优化由 0 ~ 1 0\text{\textasciitilde}1 0~1 损失函数的上界(合页损失函数)构成的目标函数。这时的上界损失函数又称为代理损失函数(surrogate loss function)。
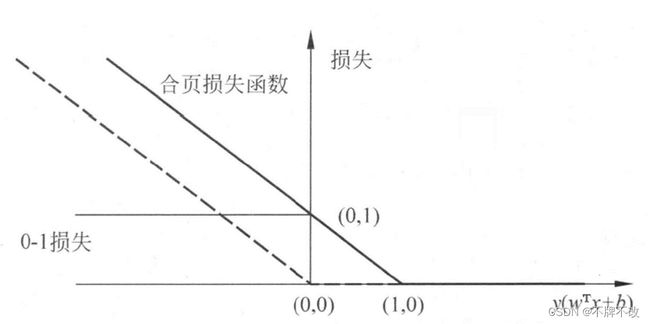
图 4 合页损失函数
图 4 4 4 中虚线显示的是感知机的损失函数 [ − y i ( w T x i + b ) ] + [-y_i(w^Tx_i+b)]_+ [−yi(wTxi+b)]+。这时,当样本点 ( x i , y i ) (x_i, y_i) (xi,yi) 被正确分类时,损失为 0 0 0,否则损失是 − y i ( w T x i + b ) -y_i(w^Tx_i+b) −yi(wTxi+b)。相比之下,合页损失函数不仅要分类正确,而且确信度足够高时损失才为 0 0 0。也就是说,合页损失函数对学习有更高的要求。
将式 ( 15 ) (15) (15) 与硬间隔对偶问题对比可以看出,二者唯一的差别就在于对偶变量的约束不同:前者是 0 ≤ α i 0\le \alpha_i 0≤αi,后者是 0 ≤ α i ≤ C 0\le \alpha_i\le C 0≤αi≤C。因此,在引入核函数后,硬间隔和软间隔能够得到同样形式的决策函数。
非线性支持向量机
我们注意到在线性支持向量机的对偶问题中,无论是目标函数还是决策函数(划分超平面)都只涉及输入样本与样本之间的内积。在对偶问题的目标函数 ( 15 ) (15) (15) 中的内积 x i T x j x_i^Tx_j xiTxj 可以用核函数 K ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) K(x_i,x_j)=\phi(x_i)^T\phi(x_j) K(xi,xj)=ϕ(xi)Tϕ(xj) 来代替。此时对偶问题的目标函数成为
W ( α ) = 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y u y j ( ϕ ( x i ) T ϕ ( x j ) ) − ∑ i = 1 n α i = 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y u y j K ( x i , x j ) − ∑ i = 1 n α i \begin{aligned} W(\alpha) &= \frac{1}{2} \sum\limits_{i=1}^n\sum\limits_{j=1}^n\alpha_i\alpha_jy_uy_j \big(\phi(x_i)^T\phi(x_j)\big)-\sum_{i=1}^n\alpha_i \\ &=\frac{1}{2} \sum\limits_{i=1}^n\sum\limits_{j=1}^n\alpha_i\alpha_jy_uy_jK(x_i,x_j)-\sum_{i=1}^n\alpha_i \end{aligned} W(α)=21i=1∑nj=1∑nαiαjyuyj(ϕ(xi)Tϕ(xj))−i=1∑nαi=21i=1∑nj=1∑nαiαjyuyjK(xi,xj)−i=1∑nαi
同样,分类决策函数中的内积也可以用核函数替代,而分类决策函数成为
f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i ( ϕ ( x i ) T ϕ ( x ) ) + b ∗ ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x i , x ) + b ∗ ) \begin{aligned} f(x) &= {\rm sign}\Big( \sum_{i=1}^N \alpha_i^* y_i \big(\phi(x_i)^T\phi(x)\big) +b^* \Big) \\ &= {\rm sign} \Big( \sum_{i=1}^N \alpha_i^* y_i K(x_i,x) +b^* \Big) \\ \end{aligned} f(x)=sign(i=1∑Nαi∗yi(ϕ(xi)Tϕ(x))+b∗)=sign(i=1∑Nαi∗yiK(xi,x)+b∗)
这等价于经过映射函数 ϕ \phi ϕ 将原来的输入空间变换到一个新的特征空间,将输入空间中的内积 x i T x j x_i^Tx_j xiTxj 变换为特征空间中的内积 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^T\phi(x_j) ϕ(xi)Tϕ(xj),在新的特征空间里从训练样本中学习线性支持线性向量机。当映射函数是非线性函数时,学习到的含有核函数的支持向量机是非线性分类模型。
也就是说,在核函数 K ( x , z ) K(x,z) K(x,z) 给定的条件下,可以利用解线性分类问题的方法求解非线性分类问题的支持向量机。学习是隐式地在特征空间进行的,不需要显式地定义特征空间和映射函数。这样的技巧称为核技巧,它是巧妙地利用线性分类学习方法与核函数解决非线性问题的技术。在实际应用中,往往依赖领域知识直接选择核函数,核函数选择的有效性需要通过实验验证。
非线性支持向量机学习算法如下。
输入: 线 性 可 分 训 练 集 D = { ( x 1 , y 1 ) , ⋅ ⋅ ⋅ , ( x n , y n ) } , 其 中 x i ∈ R d , y i ∈ { + 1 , − 1 } , i = 1 , … , n 过程: \begin{array}{ll} \textbf{输入:}&\space线性可分训练集\space D = \{(x_1,y_1),···,(x_n,y_n)\},\space 其中\space x_i\in \mathbb R^{d},\space y_i\in \{+1,-1\},\space i=1,\dots,n \\ \textbf{过程:} \end{array} 输入:过程: 线性可分训练集 D={(x1,y1),⋅⋅⋅,(xn,yn)}, 其中 xi∈Rd, yi∈{+1,−1}, i=1,…,n
1 : 选 取 适 当 的 核 函 数 K ( x , z ) 和 适 当 的 参 数 C , 构 造 并 求 解 最 优 化 问 题 min α 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j ( x i T x j ) − ∑ i = 1 n α i s . t . ∑ i = 1 n α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , … , n 求 得 最 优 解 α ∗ = { α i ∗ } , i = 1 , 2 , … , n 2 : 计 算 w ∗ = ∑ i = 1 n α i ∗ y i x i 3 : 选 择 α j ∗ > 0 , 计 算 b ∗ = y j − ∑ i = 1 n α i ∗ y i K ( x i , x j ) 4 : 分 类 决 策 函 数 f ( x ) = s i g n ( ∑ i = 1 n α i ∗ y i K ( x i , x ) + b ∗ ) \begin{array}{rl} 1:& 选取适当的核函数 \space K(x,z) \space 和适当的参数\space C,构造并求解最优化问题\\ \\ &\begin{array}{c} & \min \limits_\alpha \frac{1}{2}\sum \limits_{i=1}^n\sum \limits_{j=1}^n \alpha_i\alpha_jy_iy_j(x_i^Tx_j) -\sum \limits_{i=1}^n \alpha_i &\\ &s.t.\space\space\space\space \sum\limits_{i=1}^n \alpha_iy_i = 0 \\ &0\le\alpha_i\le C,\space\space\space\space i=1,2,\dots, n \\\\ \end{array}\\ & 求得最优解 \space \alpha^* = \{\alpha_i^*\},\space i=1,2,\dots,n \\ 2:& 计算\\ \\ &\begin{array}{c} &&w^* = \sum \limits_{i=1}^n \alpha_i^*y_ix_i \end{array}\\\\ 3:& 选择 \space \alpha_j^*>0,\space 计算\\ \\ &\begin{array}{c} &&b^* = y_j - \sum\limits_{i=1}^n\alpha_i^*y_iK(x_i,x_j) \end{array}\\\\ 4: & 分类决策函数\\ \\ &\begin{array}{c} &&f(x)={\rm sign}\left(\sum\limits_{i=1}^n\alpha_i^*y_i K(x_i,x)+b^*\right) \end{array} \end{array} 1:2:3:4:选取适当的核函数 K(x,z) 和适当的参数 C,构造并求解最优化问题αmin21i=1∑nj=1∑nαiαjyiyj(xiTxj)−i=1∑nαis.t. i=1∑nαiyi=00≤αi≤C, i=1,2,…,n求得最优解 α∗={αi∗}, i=1,2,…,n计算w∗=i=1∑nαi∗yixi选择 αj∗>0, 计算b∗=yj−i=1∑nαi∗yiK(xi,xj)分类决策函数f(x)=sign(i=1∑nαi∗yiK(xi,x)+b∗)
输出: 分 类 决 策 函 数 \begin{array}{l} \textbf{输出:}\space 分类决策函数 &&&&&&&&&&&&&&&&&& \end{array} 输出: 分类决策函数
算法 3 非线性支持向量机学习算法
REF
[1]《统计学习方法(第二版)》李航著
[2]《机器学习》周志华著
[2] 机器学习-白板推导系列(六)-支持向量机SVM(Support Vector Machine)- bilibili
[3] 机器学习-白板推导系列(六)-支持向量机SVM(Support Vector Machine)- 知乎
[4] 【机器学习】拉格朗日对偶性 - CSDN